- +1
一万亿参数,512个昇腾910训练,华为PanGu-Σ大模型来了
机器之心报道
机器之心编辑部
为了让 1.085 万亿参数的 PanGu-Σ 超大模型实现高性能和高效训练,华为的研究团队提出了一系列的优化方法。
最近几个月,我们已经见识到了大型语言模型 (LLM) 的魅力,无论是在文本生成还是推理方面,无不令人惊讶。在海量数据的基础上,语言模型随着算力的增加和参数的扩充得以不断改善,从而展示出强大的零样本、少样本学习能力甚至出现了涌现能力 。
自 GPT-3 发布以来,具有数千亿参数的大语言模型不断涌出,包括但不限于 Megatron-Turing NLG、PanGu-α、ERNIE 3.0 Titan、Gopher、PaLM、OPT、Bloom GLM-130B 。不仅如此,AI 研究者甚至开始构建具有超过一万亿参数的更大的语言模型。在这些万亿参数模型中,有几个值得关注的研究,如 Switch-C、GLaM、MoE-1.1T、Wu Dao 2.0 和 M6-10T。然而,在众多任务中,只有少数研究发布了综合评估结果,实现了预期性能。
近日,华为发布了具有稀疏架构的大型语言模型 PanGu-Σ,参数量多达 1.085 万亿。该模型基于 MindSpore 框架开发,并在 100 天内仅用 512 个昇腾 910 AI 加速器和 3290 亿 token 训练完成。PanGu-Σ 固有参数来自 PanGu-α,并且还包含 Transformer 解码器架构并通过随机路由专家 (RRE) 进行扩展。

论文地址:https://arxiv.org/pdf/2303.10845.pdf
与传统的 MoE 不同,RRE 采用二级路由。第一级,专家按领域或任务进行分组;第二级,token 随机且统一地映射到每个组中的专家,而不像 MoE 那样使用可学习的门函数。通过 RRE ,研究者可以很容易地从 PanGu-Σ 中提取子模型,用于各种下游应用,例如对话、翻译、代码生成或一般自然语言理解。
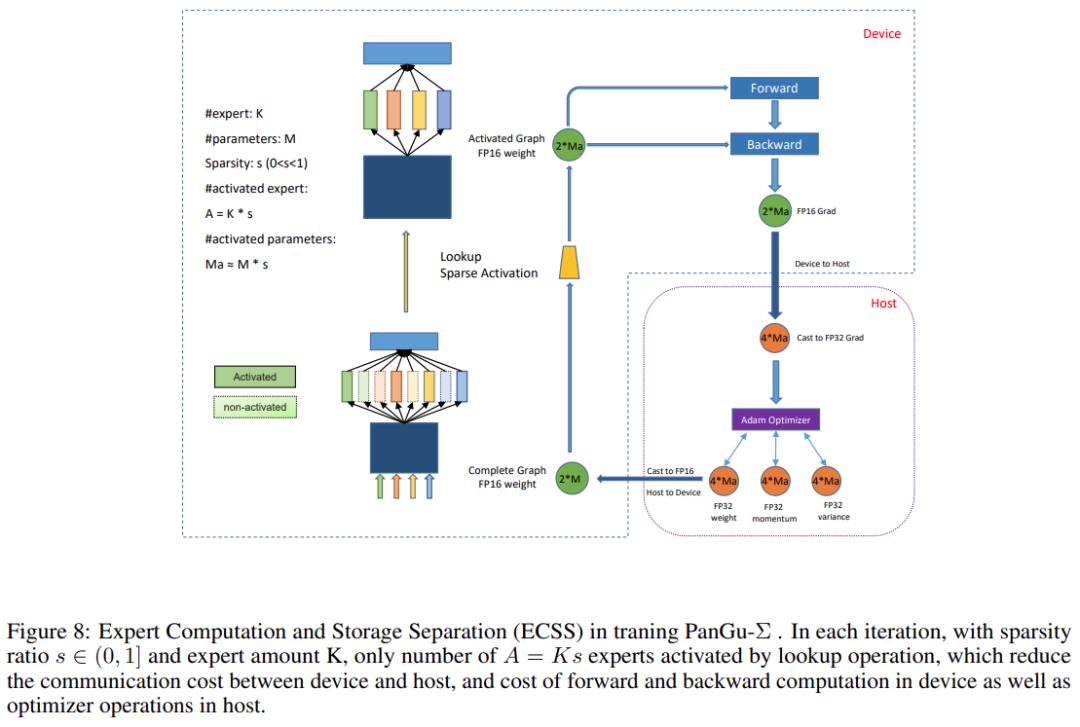
此外,为了使训练系统高效且可扩展,该研究还提出了 ECSS(Expert Computation and Storage Separation)机制,该机制在 512 个昇腾 910 加速器集群上训练 PanGu-Σ 时实现了 69905 个 token / 秒的观察吞吐量,并减少了主机到设备和设备到主机的通信以及优化器更新计算大幅增加。
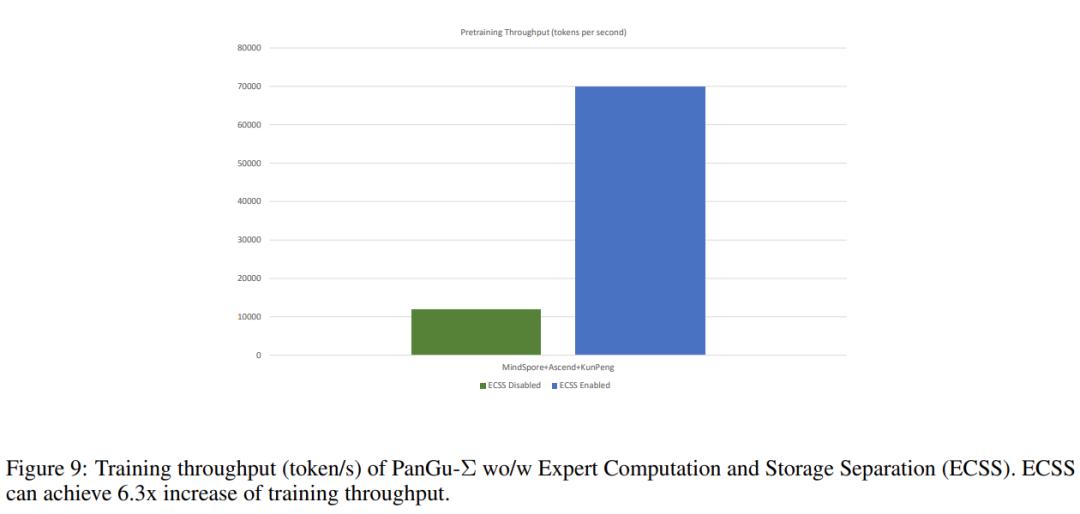
总体而言,与具有相同超参数但具有 MoE 架构的模型相比,PanGu-Σ 训练吞吐量提高了 6.3 倍。通过在 40 多种自然语言和编程语言上的 329B token 测试表明,在没有多任务微调和指令调优的情况下,在零样本设置下,PanGu-Σ 在中文域的 6 个类别的 16 个下游任务上,显著优于先前的 PanGu-α (13B 参数) 和 ERNIE 3.0 Titan (260B 参数) 这些 SOTA 模型。该研究还在对话、机器翻译和代码生成等多个应用领域测试了经过微调的 PanGu-Σ 的性能,结果表明 PanGu-Σ 在相应领域优于 SOTA 模型。
模型介绍
从总体设计看,PanGu-Σ 旨在实现以下目标:
性能:跨多个领域和任务的 SOTA NLP 性能。
效率:在 modest 集群上以最大的系统性能训练万亿参数模型。
可用性:可扩展到各种领域或任务,无需从头开始重新训练模型。
部署:在各种现实世界环境中轻松定制和部署。
PanGu-Σ 模型的整体架构如下图所示:
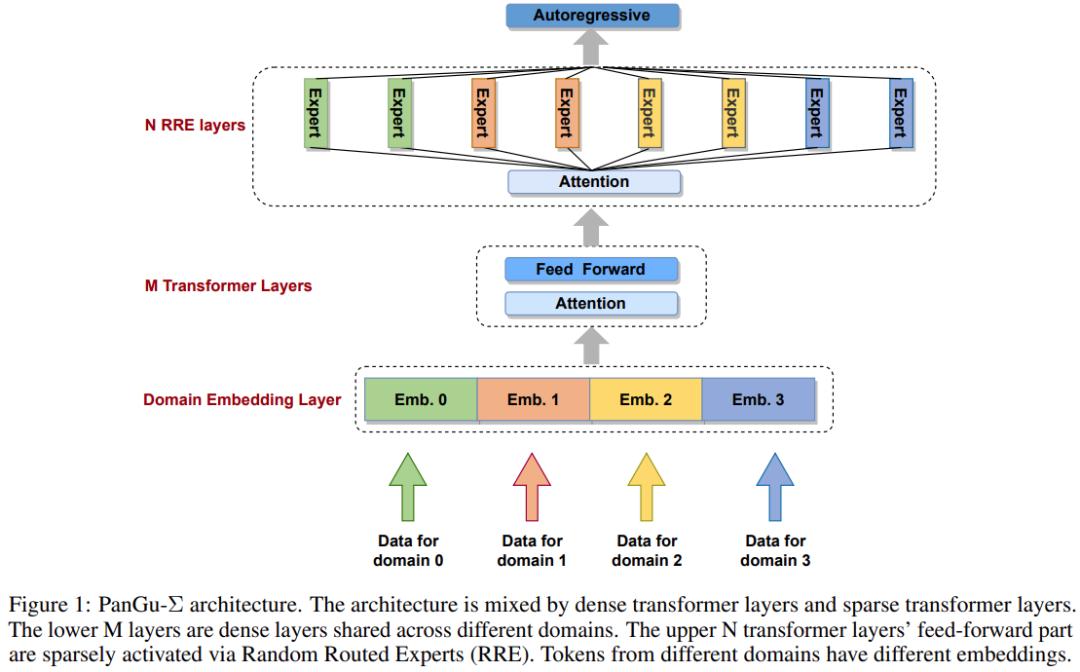
随机路由专家
在前 N 层中,PanGu-Σ 遵循混合专家系统 (MoE) 范式,用多个条件激活的前馈子层(专家)替换每个前馈子层。
设计 MoE 架构的一个关键问题是如何将 token 路由给专家。研究团队为 PanGu-Σ 提出了一种随机路由专家(Random Routed Experts,RRE)机制,其灵感来自 Stephen Roller 等人 2021 年提出的哈希层。
具体来说,RRE 以两级方式按 ID 路由 token。在第一级中,token 按领域映射到一组候选专家,然后在第二级中,根据 token - 专家路由映射选择该组中的一个专家来处理 token。路由映射是随机初始化的,每一层都有一个独立初始化的映射来平衡计算。
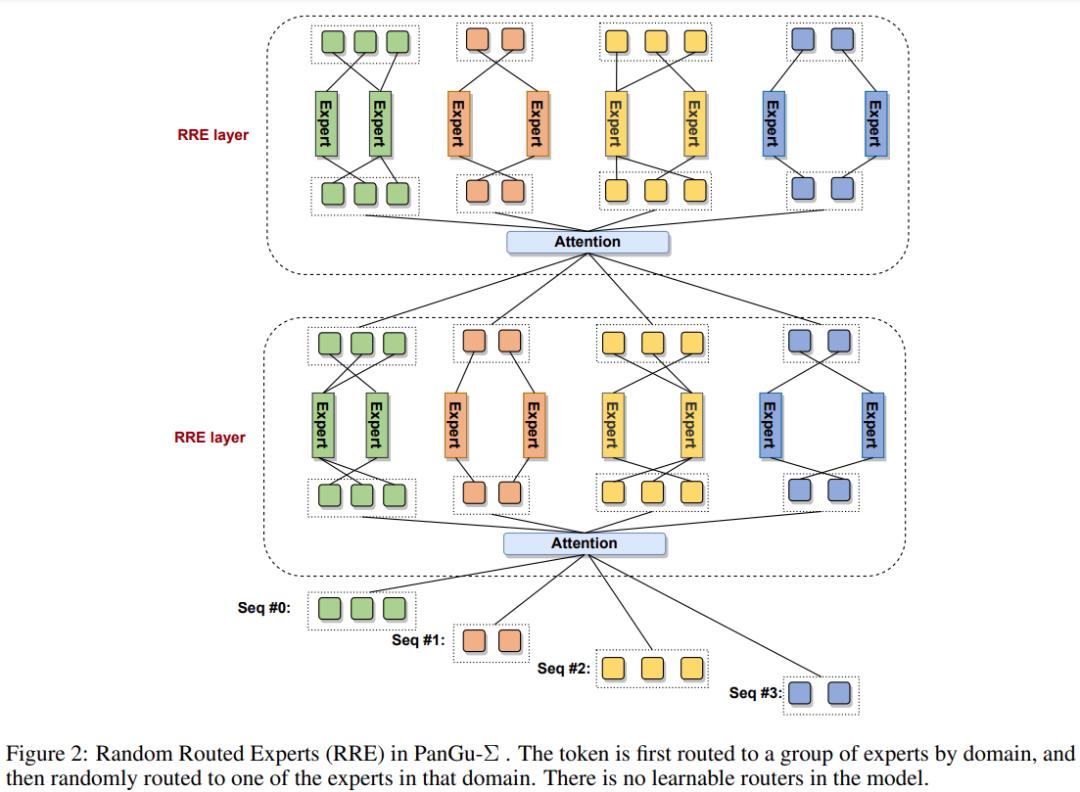
与常用的可学习路由器(learnable router)相比,RRE 有如下几个优点:
在训练期间,PanGu-Σ 允许添加、修改或删除特定领域的专家,而不会对其他专家产生任何影响。此属性使 PanGu-Σ 高度灵活,可以缓解常见的灾难性遗忘(catastrophic forgetting)问题,这对于持续学习至关重要。
在大多数实际部署环境中,部署万亿参数模型是不必要或不切实际的。PanGu-Σ 允许根据实际需要提取特定领域的子模型,只部署子模型。子模型可能包含数百亿个参数,但仍保持原始模型对目标域的预测能力。使用这种提取和部署操作,人们可以轻松地为多个工业应用程序部署模型。
所有传统的 MoE 模型都依赖于 all-to-all 聚合通信操作,以在不同设备上的专家之间移动数据。而 PanGu-Σ 提出的两级路由让来自不同领域的专家不交换 token,并且每个域内的 all-to-all 通信也受到限制。这样做的结果就是,昂贵的全局 all-to-all 操作被减少为分组 all-to-all,节省了大量通信量并减少了端到端训练延迟。
可学习路由器需要更多的计算,并且可能会遇到专家负载不平衡的问题,这通常会使训练过程不稳定。RRE 避免了上述所有陷阱,因为没有引入额外的参数,并且随机初始化的路由表有助于平衡专家负载。
RRE 需要一个在预训练之前初始化的路由映射,下图算法 1 描述了该研究构建路由表的方法。

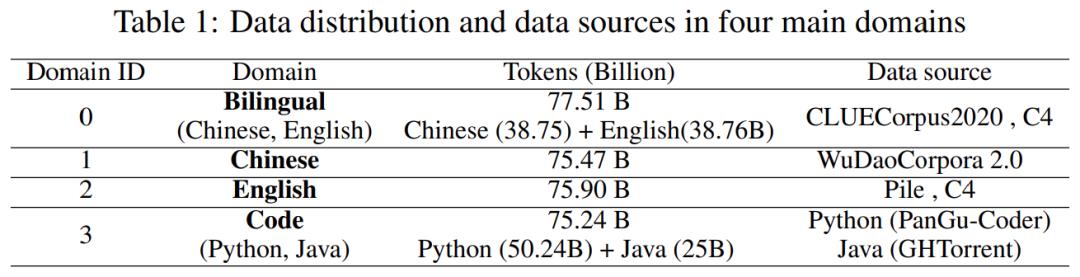
在数据集方面,该研究主要使用 4 个域的数据,数据分布和数据来源如下表 1 所示:
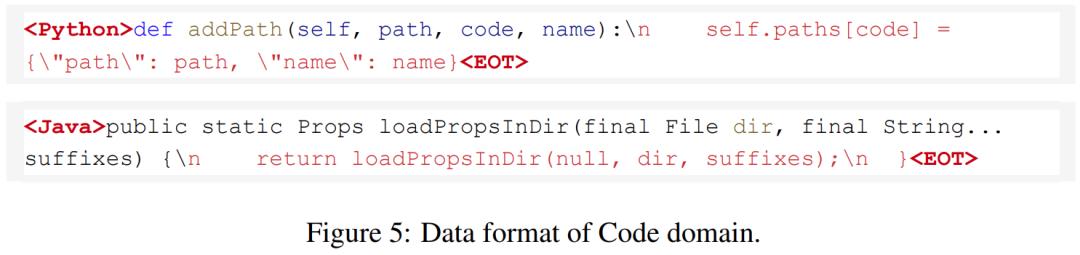
其中,每个域都可以适应不同的下游任务。为了更好地支持特定域的下游任务,该研究针对不同的域使用不同的数据格式。具体来说,4 个域的数据格式如下所示:


为了充分利用昇腾 910 集群的计算能力,在预训练阶段加速训练,研究团队将数据集中的所有样本拼接成一个序列,然后按照固定长度(1024)截取拼接序列中的训练实例,如下图 6 所示。

在微调阶段,对于格式化数据集中的每个训练样本,如果长度小于固定长度,该研究用一个特殊的 token 将样本填充到固定长度;如果长度大于固定长度,多余的部分将被截断,如下图 7 所示。
与 PanGu-α 模型不同,PanGu-Σ 模型的每个训练样本包含两个字段:作为训练实例的 token ID 输入序列及其域 ID。域 ID 指示训练实例属于哪个域。PanGu-Σ 模型的 RRE 层会根据域 ID 决定训练 token 路由到哪些专家。
ECSS
PanGu-Σ 使用 MindSpore 1.6 框架实现,并在 512 个昇腾 910 加速器(也称为 Ascend 910 NPU)上进行训练。
研究团队还提出了如下图 8 所示的专家计算和存储分离 (Expert Computation and Storage Separation,ECSS) 方法,使得 PanGu-Σ 实现了高效稀疏化。
使用 ECSS 方法的 PanGu-Σ,在吞吐量方面是普通异构训练 PanGu-Σ 的 6.3 倍,如下图 9 所示。
实验
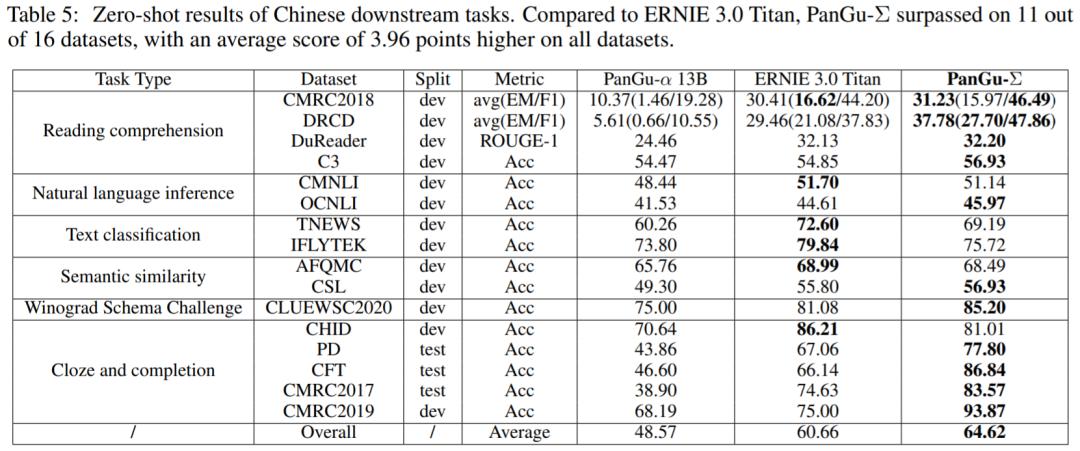
该研究选择 PanGu-α 和 ERNIE 3.0 Titan 作为比较基准,在中文下游任务的性能如表 5 所示。结果显示与具有 2600 亿参数的 ERNIE 3.0 Titan 相比,PanGu-Σ 在 16 个数据集中有 11 个超越 ERNIE 3.0 Titan,并且在所有数据集上比 ERNIE 3.0 Titan 的平均得分高出 3.96 分。
接下来是验证 PanGu-Σ 的中文对话生成能力,参与比较的系统包括 CDialGPT、EVA、EVA 2.0 和 PanGu-Bot。如表 6 所示,在 Self-chat 评价中, PanGu-Σ 的整体响应质量远远高于基线,尤其是在 Specificity 方面。
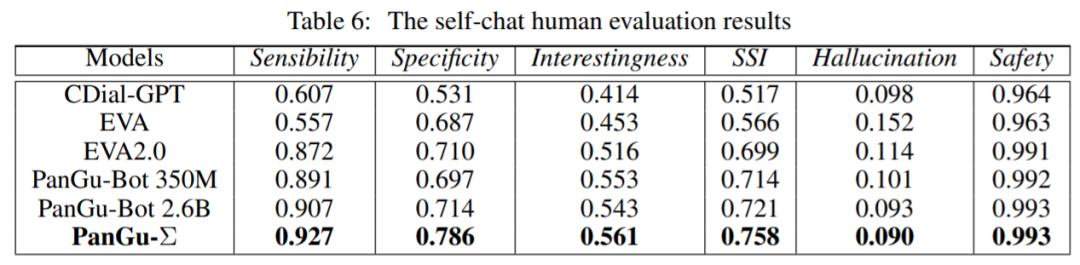
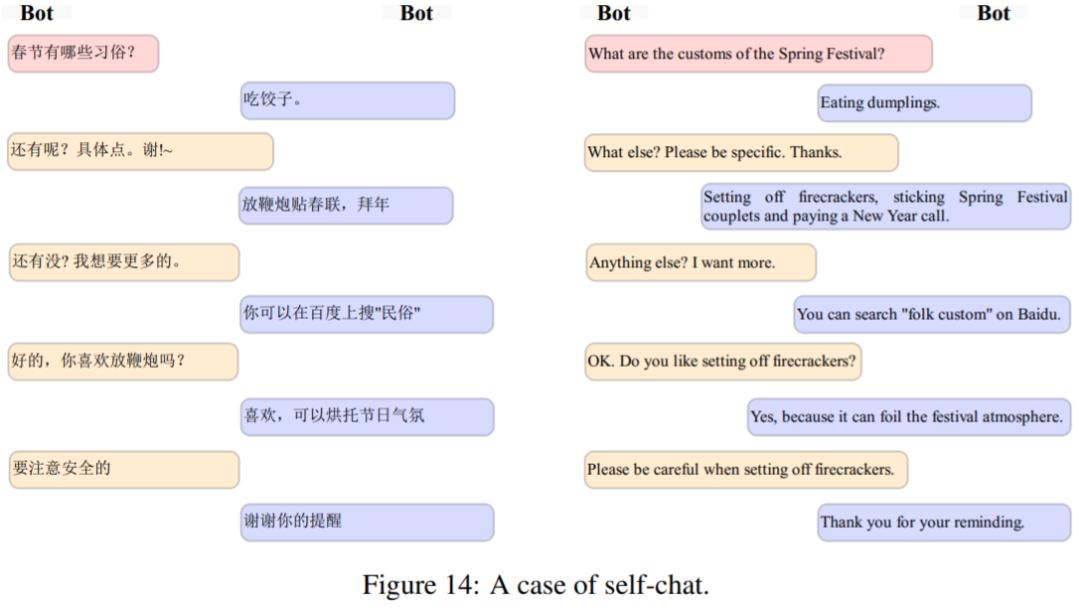
图 14 显示了一个 Self-chat 案例,其中对话进行得很顺利,包含的知识也很丰富。
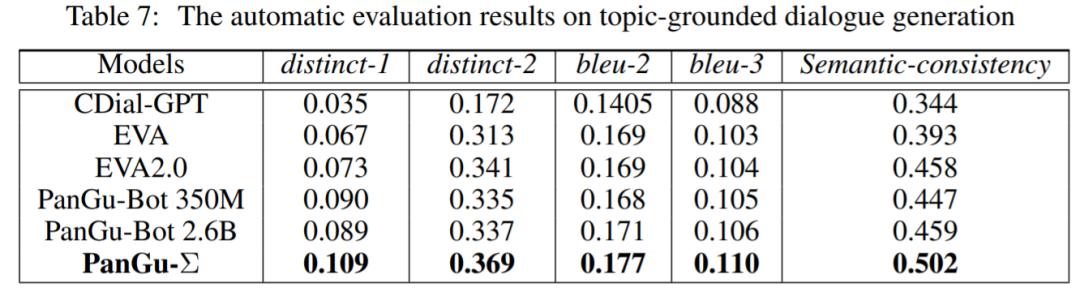
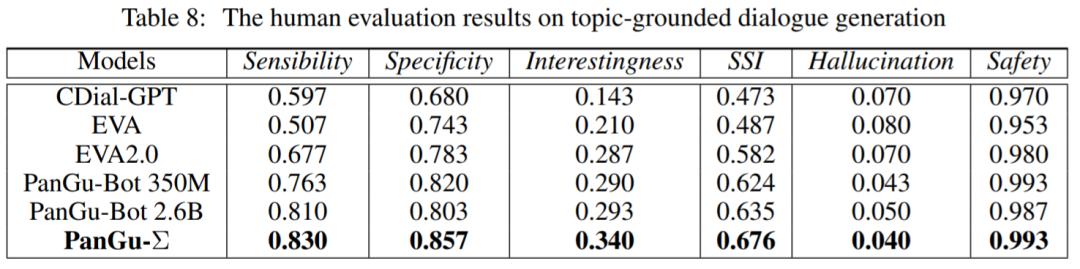
一个设计良好的对话系统应该能够将相关知识与闲聊的特点结合起来。实验中,该研究还评估了模型基于主题的对话表现,其中对话历史包含丰富的知识和主题信息。结果如表 7 和表 8 所示。与基线相比,PanGu-Σ 可以生成更多样化、语义一致、知识丰富且有趣的响应。
下图 9 为 PanGu-Σ 在历史对话背景下,给出的回答,结果显示,相比于 EVA2.0 等,PanGu-Σ 的回答和主题更贴切:

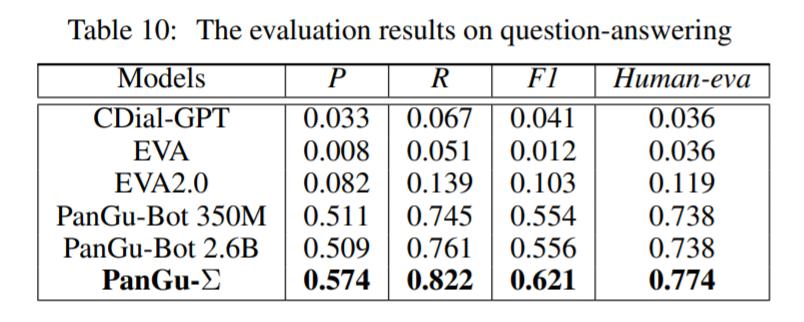
模型在开放域问答评价结果如表 10 所示,PanGu-Σ 能够很好地回答事实性问题,准确率最高。
问答案例如表 11 所示,其中 PanGu-Σ 的答案是最准确的:

代码能力:PanGu-Σ 在下游任务上的评估。图 15 显示了 MBPP(是衡量预训练模型从自然语言描述生成 Python 程序能力的基准)微调数据集中的一个示例。

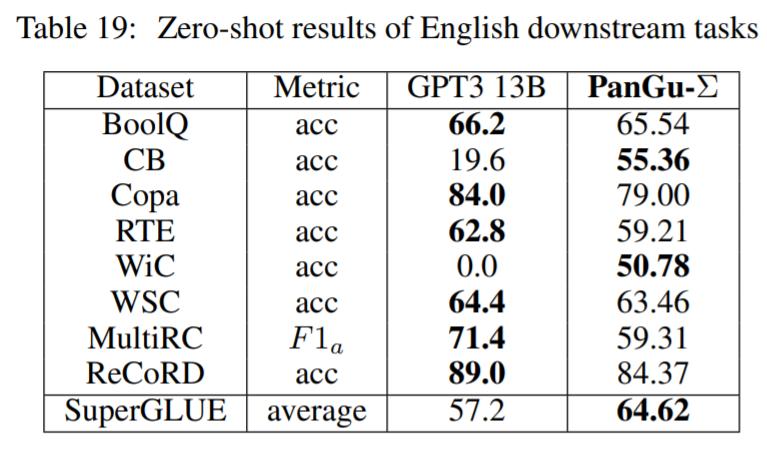
表 19 给出了在英语下游任务上,模型的零样本结果:
原标题:《一万亿参数,512个昇腾910训练,华为PanGu-Σ大模型来了》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

