- +1
漫画科普ChatGPT:绝不欺负文科生
原创 亲爱的数据 亲爱的数据
图文原创:亲爱的数据
你所热爱的,都值得拥有一个名字。
世界上里程碑式计算机,问世之时大多拥有自己的名字。
我认为,假如计算机的诞生是元年,下一个元年将会是“奇点”。
不是比特币,不是虚拟现实,不是AIGC(用人工智能技术来生成内容)。这些只是过程。
当然,过程足够重要,也要有名字。
很多人看到GPT-2,GPT-3, Switch Transformer,DALL·E 2 ,Codex,LaMDA,就头晕,看不懂。

它们都是模型的名字。以它们在信息技术发展史上的地位,高低得整个名字。
模型里有什么?
模型中的运算形式设计,和运算所需要的参数,都是模型的一部分。
近几年,大模型发展的有声有色,一个做得比一个大。
参数数量是模型大小的重要指标,但不是唯一指标。运算量也是指标之一。同样的参数量,你设计的运算的形式不同,计算量也不同。
运算形式设计是人类脑力精华。
参数,你可以简单理解为机器部件,部件越多,体量越大。但不见得部件越多,机器就越好,模型也一样。
参数量很直观,一度“参数比大小”成了关键。
2020年5月,GPT-3有1750亿参数。比它的兄弟GPT-1和GPT-2强大的多。GPT-3 发布仅几个月后,谷歌大脑团队就发布了Switch Transformer,参数量是GPT-3的9倍。
但是“比大小”不是目的,“效果好”才是目的。
这些“配有姓名”的大模型,规模很关键,但是创新更关键。
贾扬清说,不是别人做出大模型之后,简单跟进说“我们可以做得更大”,更重要的是,在前人基础上,做更多创新成果。
OpenAI也只是一家搞AI创业的“小公司”,在“转身”成为公司之前,是一家公益性质的科研实验室。
公司虽小,愿景却大:“让人工智能有益于全人类”。
从此,OpenAI他们矢志不渝地朝着通用人工智能(AGI)的方向不断尝试。
AGI是最有抱负的科技方向之一,拥抱AGI必须让机器展示出人类所拥有的各项智能,亲情,爱情,友情。
但怎么前往AGI,人类毫无头绪,也有人说,毫无希望。
情况就是这么一个情况。

把模型做大是不是通向人工智能的路?谁也不知道。
但是模型大了,效果确实好了。大模型的竞争从寥寥到陷入忙碌, 比方法,比技巧,比谁有效。
2022年3月,InstructGPT,加入了人类的评价和反馈数据,效果也很好。
参数降到了13亿,小也可以很能打。
Instruct的中文有吩咐,指令之意,就是说,按照人类的指示行事。
讲到InstructGPT,距离ChatGPT也不远了。
ChatGPT也按指令行事,方式是通过问答。
大模型超级难做,消耗无数系统工程师和算法工程师的智慧和精力,是个系统工程,而今看来,国之重器,毫不为过。
这擎天玩意让缺乏创新的模型看起来像夜市地摊上粗糙的塑料玩具。
这种规模的模型,用“做出来”这个动词已经不合适了,与其说是“开发”,不如说是“组织开发”。

为此OpenAI配套了上游数据团队,和下游芯片“大军”。
根 InstructGPT 的技术博客,从事高质量数据收集、挖掘、清理、增强等方面的工作的人数,从40人增加到1000人。数据团队有技术含量,收入可观,说是一家科创板上市公司也不过分。
作为ChatGPT的数据公司,那怕轮次融资,投资人会爱极了。
为了开发一个模型,配套一家上市公司,真是妙。
这还没有完。
芯片方面,据谭老师截获了一个信息:
“OpenAI公司为训练ChatGPT用了10万块英伟达A100的GPU。”
我也问了一个业内顶级大佬,他亦认为合理。
且不说价钱,而这一型号的高端GPU已经被美国限制,国内买不到了。
ChatGPT背后的一些信息来自InstructGPT的学术论文。
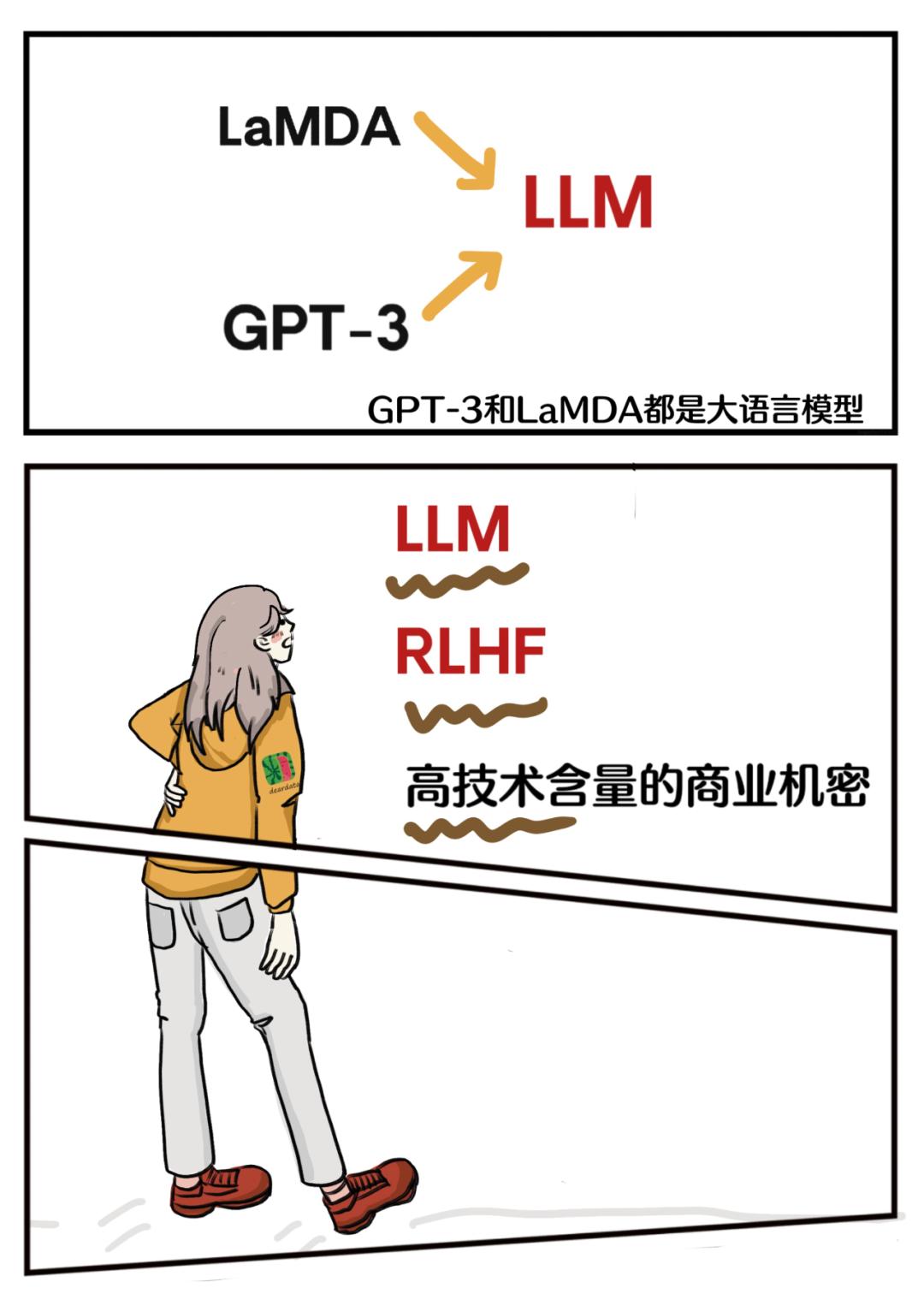
InstructGPT的核心思路由之前两条研究线路所带来。
也就是说,装在ChatGPT弹匣里的银色子弹中,一颗叫“自然语言理解的大语言模型 LLM”,一颗叫“带人类反馈的强化学习 RLHF”。
贾扬清的解释是,这一系列大预语言模型多少都采取了不带太强结构的统计方法:“根据周边的词语来预测中间的词语”,或者“根据前面的文字来生成后面的词语”。
当然,还有一些银弹叫,“外人不知道”。
叹服ChatGPT前沿科研的能力之余,思考它如何从一个科研成果变成人见人爱的科技产品?
OpenAI此前所推出了一种产品试用机制,用了两个工具。工具一Playground,工具二GPT-3 API。API必须要代码调用接口,并不是人人都可以轻而易举体验它的能力。
虽然GPT-3 API已经非常简单,代码复制粘贴也能试一下。
贾扬清认为,这种产品试用让产品和市场在做小范围的磨合,尝鲜者虽少,但本质上,产品试用为后续的科研带来了大量的数据输入。
科研没有停止,科研在不断走向产品。
计算机领域有一个短语叫做 “human in the loop”,有人翻译成“人机交互”,并没有揭示核心。也有人翻译成“人机回环”。
贾扬清的解释是,将一篇科研文章变成一个软件原型(prototype)。再将用户的体验、数据的回流、标注、再训练这个闭环做得非常精准。ChatGPT 在这一个领域中体现出了高超能力。
科技产品可以粗糙,也可以精美。
ChatGPT的科研背景非常强,满身都是商业机密的ChatGPT,虽然公布出来的技术大家都懂,但是为什么他们的效果这么好?
OpenAI团队做出来一个目前为止最接近AGI的东西,似乎证明了通用人工智能是存在的。
无论是不是,它离我们想象中的AI越来越近了。
(完)

最后,再介绍一下主编自己吧,
我是谭婧,科技和科普题材作者。
为了在时代中发现故事,
我围追科技大神,堵截科技公司。
偶尔写小说,画漫画。
生命短暂,不走捷径。
个人微信:18611208992
原创不易,多谢转发
还想看我的文章,就关注“亲爱的数据”。
原标题:《漫画科普ChatGPT:绝不欺负文科生》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

