- +1
Nature立新规:ChatGPT等大模型不可以成为作者
内容来自机器之心(ID:almosthuman2014)
随着研究人员不断涌入先进的 AI 聊天机器人的「新世界」,像《Nature》这样的出版商需要承认它们的合法用途,并制定明确的指导方针以避免滥用。
几年来,人工智能正在获得生成流畅语言的能力,开始大量制造越来越难以与人类生成文本区分的句子。一些科学家很早就在使用聊天机器人作为研究助手,帮助组织自己的思维,生成对自身工作的反馈,协助编写代码以及对研究文献进行摘要。
但在 2022 年 11 月发布的 AI 聊天机器人 ChatGPT,正式将这种被称为大型语言模型的工具能力带给了大众。其研发机构 —— 位于旧金山的初创公司 OpenAI 提供了这款聊天机器人的免费使用权限,即使不具备技术专长的人也能轻松使用。
数以百万计的人正在使用它,生成结果有时是有趣的、有时是可怕的。「AI 写作实验」的爆炸性增长,让人们对这些工具越来越感到兴奋和不安。
ChatGPT 超能力的喜与忧
ChatGPT 可以写出漂亮的学生作文、总结研究论文、回答问题、生成可用的计算机代码,甚至足以通过医学考试、MBA 考试、司法考试等。
前段时间,ChatGPT 在一项实验中已经「接近」通过美国医学执照考试(USMLE)。一般来说,这需要四年的医学院学习和两年以上的临床经历才能通过。

Step 1 是在医学院学习 2 年后进行,包括基础科学、药理学和病理生理学。学生平均学习 300 多个小时才能通过。
Step 2 是在医学院 4 年 + 1.5-2 年的临床经历后进行的,包括临床推断和医疗管理。
Step 3 是由完成了 0.5-1 年的研究生医学教育的医生参加。
ChatGPT 还成功通过了沃顿商学院的 MBA 运营管理期末考试。当然,这种考试并不是最难的问题,但在 1 秒钟内完成必须算是「突破性」的。



在司法考试这件事上,ChatGPT 仍然展现出了非凡的能力。在美国,要想参加律师专业执照考试,大多数司法管辖区要求申请人完成至少七年高等教育,包括在经认可的法学院学习三年。此外,大多数应试者还需要经过数周至数月的考试准备。尽管投入了大量的时间和资金,大约 20% 的应试者在第一次考试中的得分仍然低于通过考试的要求。
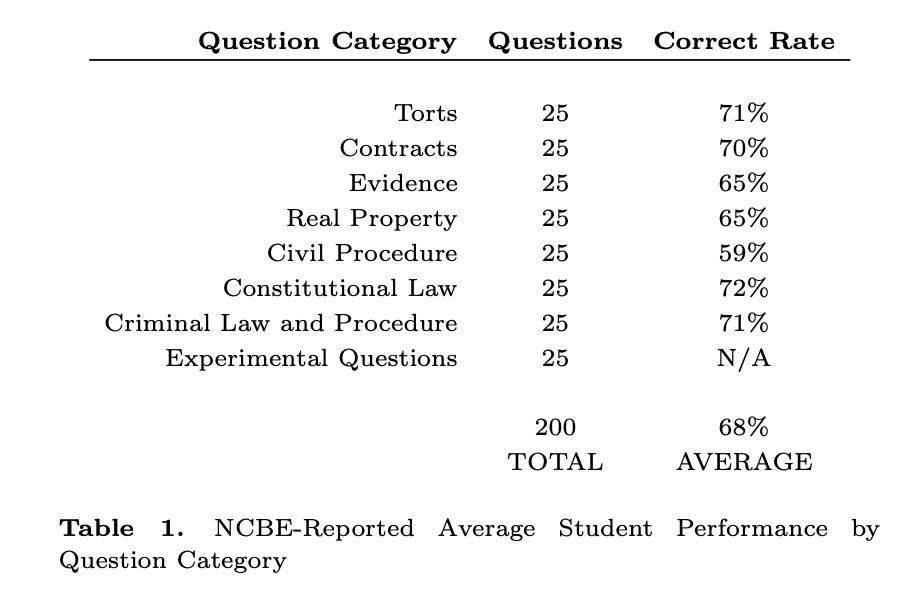
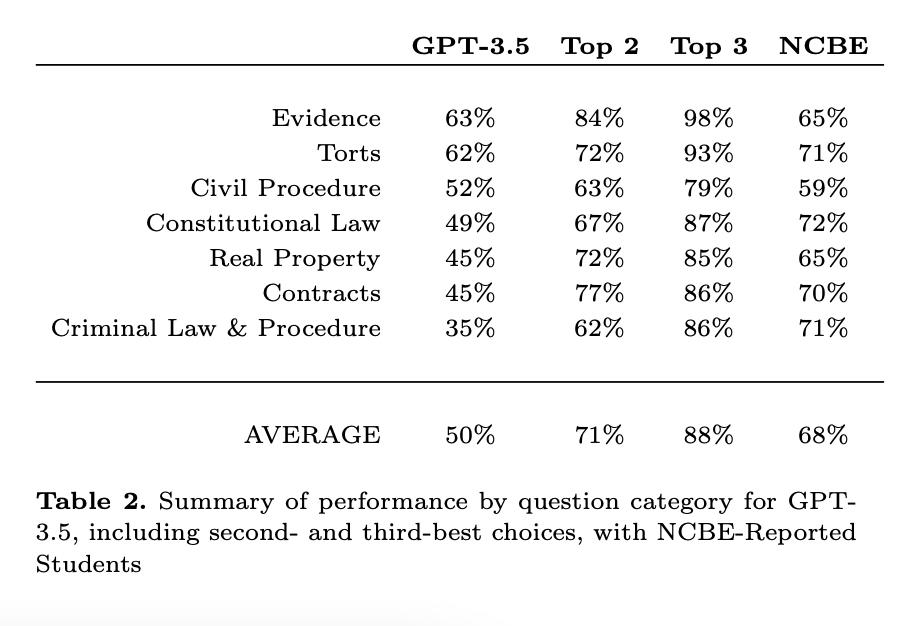
但在最近的一项研究中,研究者发现,对于最佳 prompt 和参数,ChatGPT 在完整的 NCBE MBE 练习考试中实现了 50.3% 的平均正确率,大大超过了 25% 的基线猜测率,并且在证据和侵权行为方面都达到了平均合格率。ChatGPT 的答案排名也与正确率高度相关;其 Top 2 和 Top 3 的选择分别有 71% 和 88% 的正确率。作者认为,这些结果强烈表明大型语言模型将在不久的将来通过律师资格考试的 MBE 部分。
ChatGPT 编写的研究摘要水平也很高,以至于科学家们发现很难发现这些摘要是由计算机编写的。反过来说,对整个社会来说,ChatGPT 也可能使垃圾邮件、勒索软件和其他恶意输出更容易产生。
目前为止,语言模型生成的内容还不能完全保证其正确性,甚至在一些专业领域的错误率是很高的。如果无法区分人工编写内容和 AI 模型生成内容,那么人类将面临被 AI 误导的严重问题。尽管 OpenAI 试图为这款聊天机器人的行为设限,但用户已经找到了绕过限制的方法。
学术界的担心
学术研究界最大的担忧是,学生和科学家可以欺骗性地把大模型写的文本当作自己写的文本,或者以简单化的方式使用大模型(比如进行不完整的文献综述),生成一些不可靠的工作。
在近期西北大学 Catherine Gao 等人的一项研究中,研究者选取一些发表在美国医学会杂志(JAMA)、新英格兰医学杂志(NEJM)、英国医学期刊(BMJ)、《柳叶刀》和《Nature Medicine》上的人工研究论文,使用 ChatGPT 为论文生成摘要,然后测试审稿人是否可以发现这些摘要是 AI 生成的。
实验结果表明,审稿人仅正确识别了 68% 的生成摘要和 86% 的原始摘要。他们错误地将 32% 的生成摘要识别为原始摘要,将 14% 的原始摘要识别为 AI 生成的。审稿人表示:「要区分两者出奇地困难,生成的摘要比较模糊,给人一种公式化的感觉。」
甚至还有一些预印本和已发表的文章已经将正式的作者身份赋予 ChatGPT。一些学术会议率先公开反对,比如机器学习会议 ICML 就表示过:「ChatGPT 接受公共数据的训练,这些数据通常是在未经同意的情况下收集的,这会带来一系列的责任归属问题。」
因此,现在或许是研究人员和出版商制定以道德方式使用大型语言模型的基本规则的时候了。《自然》杂志公开表示,已经与所有 Springer Nature 期刊共同制定了两条原则,并且这些原则已被添加到现有的作者指南中:
首先,任何大型语言模型工具都不会被接受作为研究论文的署名作者。这是因为任何作者的归属权都伴随着对工作的责任,而 AI 工具不能承担这种责任。
第二,使用大型语言模型工具的研究人员应该在方法或致谢部分记录这种使用。如果论文不包括这些部分,可以用引言或其他适当的部分来记录对大型语言模型的使用。

作者指南:https://www.nature.com/nature/for-authors/initial-submission
通讯作者应以星号标明。大型语言模型(LLM),如 ChatGPT,目前不符合我们的作者资格标准。值得注意的是,作者的归属带有对工作的责任,这不能有效地适用于 LLM。LLM 的使用应该在稿件的方法部分(如果没有方法部分,则在合适的替代部分)进行适当记录。
据了解,其他科学出版商也可能采取类似的立场。「我们不允许 AI 被列为我们发表的论文的作者,并且在没有适当引用的情况下使用 AI 生成的文本可能被视为剽窃,」《Science》系列期刊的主编 Holden Thorp 说。
为什么要制定这些规则?
编辑和出版商可以检测由大型语言模型生成的文本吗?现在,答案是「或许可以」。如果仔细检查的话,ChatGPT 的原始输出是可以被识别出来的,特别是当涉及的段落超过几段并且主题涉及科学工作时。这是因为,大型语言模型是根据它们的训练数据和它们所看到的 prompt 中的统计学关联来生成词汇模式的,这意味着它们的输出可能看起来非常平淡,或者包含简单的错误。此外,它们还不能引用资料来记录他们的输出。
但在未来,人工智能研究人员也许能够解决这些问题 —— 例如,已经有一些实验将聊天机器人与引用资源的工具联系起来,还有一些实验用专门的科学文本训练聊天机器人。
一些工具声称可以检测出大型语言模型生成的输出,《自然》杂志的出版商 Springer Nature 就是开发这项技术的团队之一。但是大型语言模型将会迅速改进。这些模型的创建者希望能够以某种方式为其工具的输出添加水印,尽管这在技术上可能不是万无一失的。

近期较火的一篇为大型语言模型输出添加「水印」的论文。论文地址:https://arxiv.org/pdf/2301.10226v1.pdf
从最早的时候起,「科学」就主张对方法和证据公开透明,无论当时流行的是哪种技术。研究人员应该扪心自问,如果他们或他们的同事使用的软件以一种根本不透明的方式工作,那么产生知识的过程所依赖的透明度和可信度如何保持。
这就是为什么《自然》杂志制定了这些原则:最终,研究方法必须透明,作者必须诚实、真实。毕竟,这是科学赖以发展的基础。
参考链接:
https://www.nature.com/articles/d41586-023-00191-1
https://www.nature.com/articles/d41586-023-00107-z
原标题:《Nature立新规:ChatGPT等大模型不可以成为作者》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

