- +1
AIGC的浪潮下,文本生成发展得怎么样了?
机器之心报道
编辑:小舟
1 月 12 日,在机器之心 AI 科技年会 AIGC 技术应用论坛上,澜舟科技创始人兼 CEO、中国计算机学会 CCF 副理事长、创新工场首席科学家周明发表了主题演讲《文本生成研究进展》。

以下为演讲的详细内容,机器之心进行了不改变原意的编辑、整理。
我今天主要介绍一下文本生成,尤其是可控文本生成目前的几个重要研究进展,包括文本生成基本方法与应用、文本生成中的可控方法研究、文本生成中如何融入知识和常识,长文本生成方法以及文本生成中的解码方法。在此之后,我会介绍一下澜舟科技在文本生成方面的最新项目。

首先我来介绍一下文本生成的任务和主流的框架。文本生成的任务定义是输入结构化的数据、图片或者文本来生成一段新的文本。例如输入结构化的数据、输入一张图片,或者输入若干关键词来生成文本。目前的主流生成模型都是基于 Transformer 架构的编码器 - 解码器框架,如下图所示。
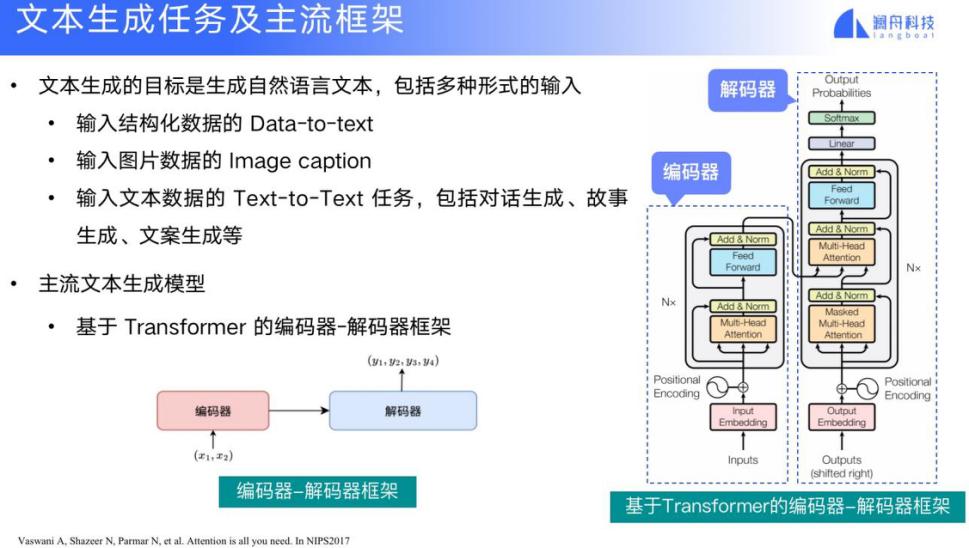
Transformer 是谷歌在 2017 年提出的一个架构体系,可以利用多头注意力模型来扩展不同的信息抽取能力,并且利用多层的神经网络架构来实现更加精准的编码和解码过程。
可控文本生成是指我们希望生成文本不是随意生成的,而是能够把一些要素添加进去,比如情感的要素,关键词的要素,主题的要素和事实的要素,如下图所示。

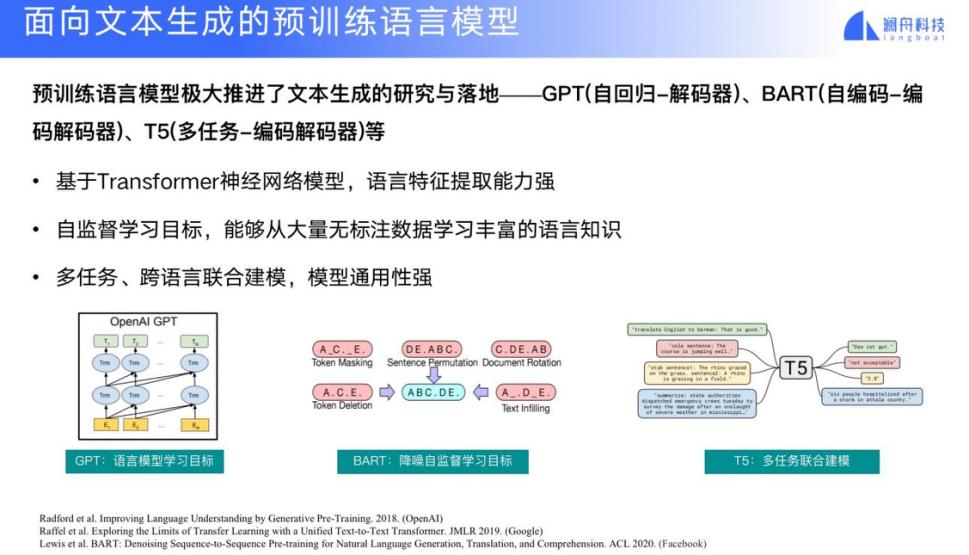
面向文本生成的预训练模型,有像 GPT 这样的自回归解码器模型,例如最新的 ChatGPT,它主要的模型架构是 GPT-3.5 的 InstructGPT。当然也有一些其他类型的模型,例如 BART 是自编码解码器模型,还有 T5 是多任务编码器 - 解码器模型。
文本生成面临的问题很多,我这里总结了 4 点:
常识错误;
内容逻辑错误;
内容发散;
语句重复。

解决当下文本生成问题的关键技术有如下几点:第一是如何来改进文本生成的可控性;第二是如何改进事实的正确性;第三是如何改进文本生成的前后一致性和连贯性。第四是如何克服重复生成,如何增加多样性等等。下面我就逐一快速介绍一下。

首先我介绍一下文本生成中的可控方法。可控方法目前有几种:
第一种是调整解码策略,使得生成的结果尽可能地包含目标的内容,也就是我们所指定的主题关键词;
第二种是调整训练的目标函数,构建面向特定任务的可控训练目标函数;
第三种是调整模型输入,通过输入控制元素来影响生成的结果。

下面我对这几种方法逐一展开介绍。
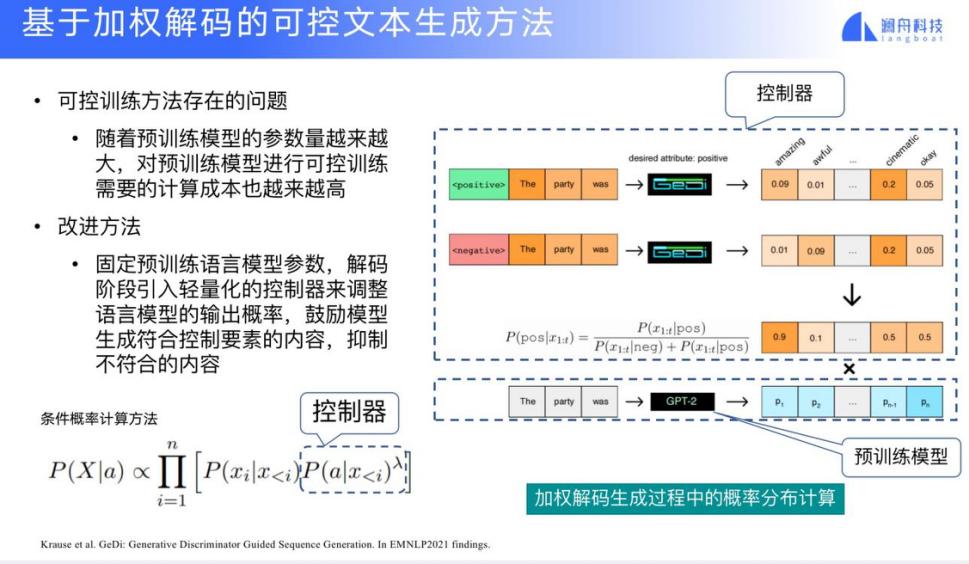
第一个是基于加权解码的可控文本生成。当我们想生成一句 positive 的话,就会希望下一个生成的词接近 positive,所以这就需要添加一个控制器。原始模型是基于前面的词预测下一个词的 GPT 模型。加一个控制器就意味着如果下面的词是 positive 的,我们就更加倾向于选择它,因此加了一个这样的控制器来控制解码的过程。其中,控制器中的参数 λ 是固定的。
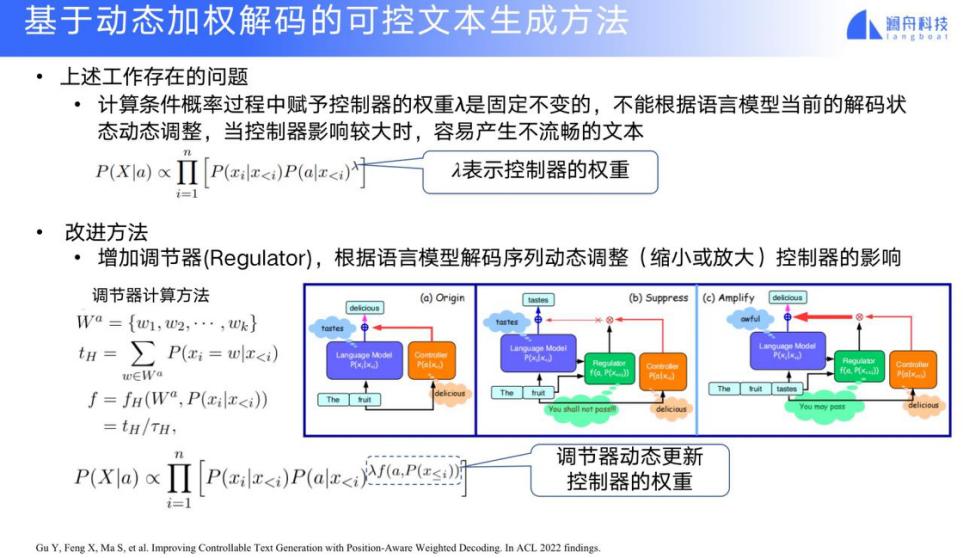
我们有时需要根据上下文信息,增加或减少某些词的输出概率,做一个动态的调整,所以我们可以加入一个动态的解码权重。
可控文本生成也可以用 prompt 的方式。我们已经有一个预训练模型,可以用一些提示词的方式来生成可控结果,比如我们要生成正面情感的一句话,可以输入「这首歌充满感情」这句话,输出的结果可能就倾向于正面。但是这种方法需要人工地针对不同场景找到相应的提示词。这是很花工夫的一种方法。
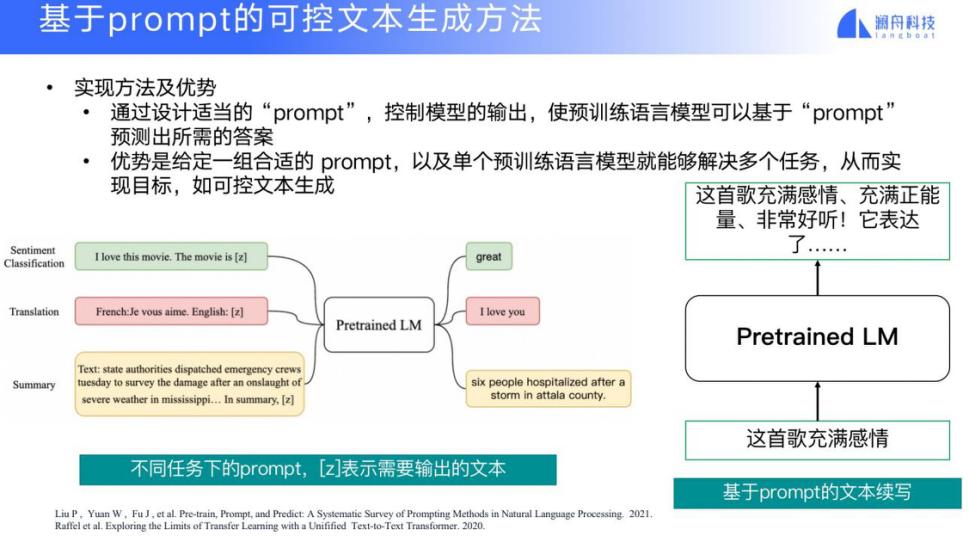
另一种方法,我们针对可控要素生成一个连续向量(prefix)来代替具体的 prompt,与传统的经典预训练模型(例如 GPT)组合在一起来体现某些可控要素。
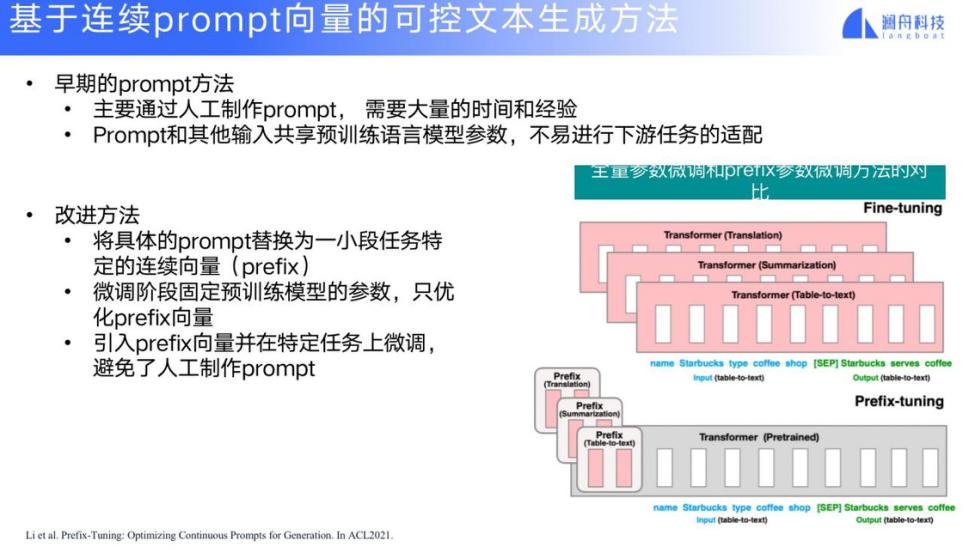
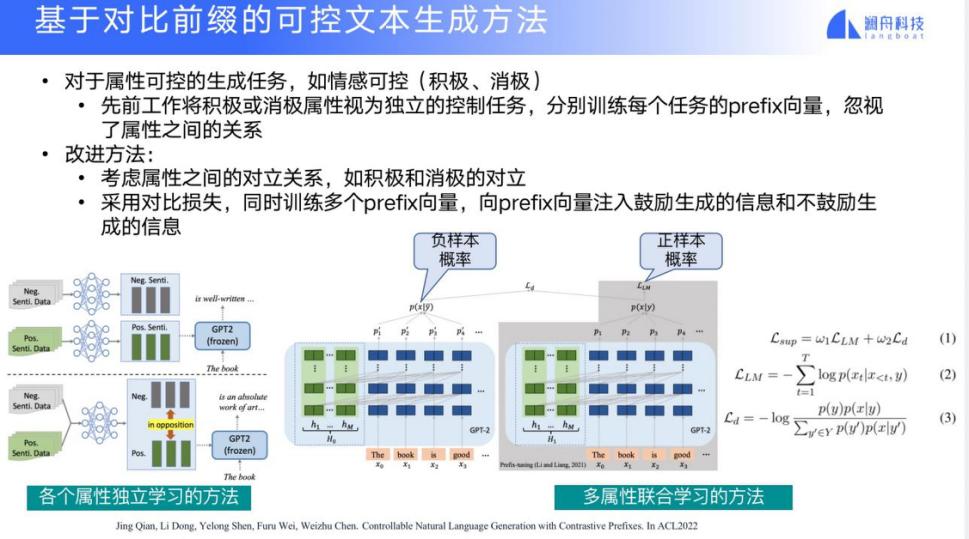
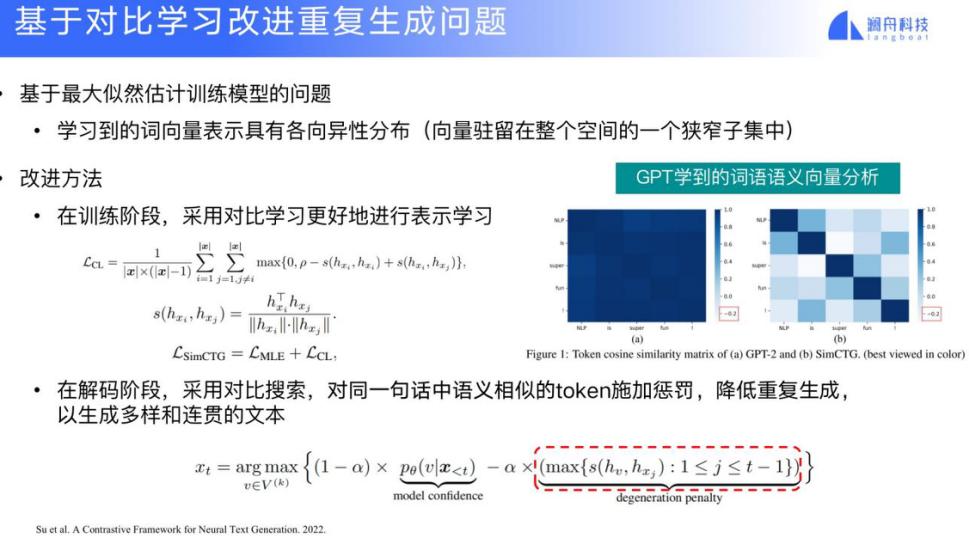
有一种特别简单的方法是我每生成一种情感或者要素,就构建一个网络,每次都从头开始训练网络。还有一种改进的方法是基础的网络不变,只是每次针对具体的生成目标来调整 prompt。这方面已经出现了一些具体的进展,比如基于对比学习的可控文本生成方法:要生成一个 positive 的要素,在做 positive 要素的模型时,就试图让生成结果尽可能逼近 positive,远离 negative。这就是将对比学习的机制引入到模型训练中。
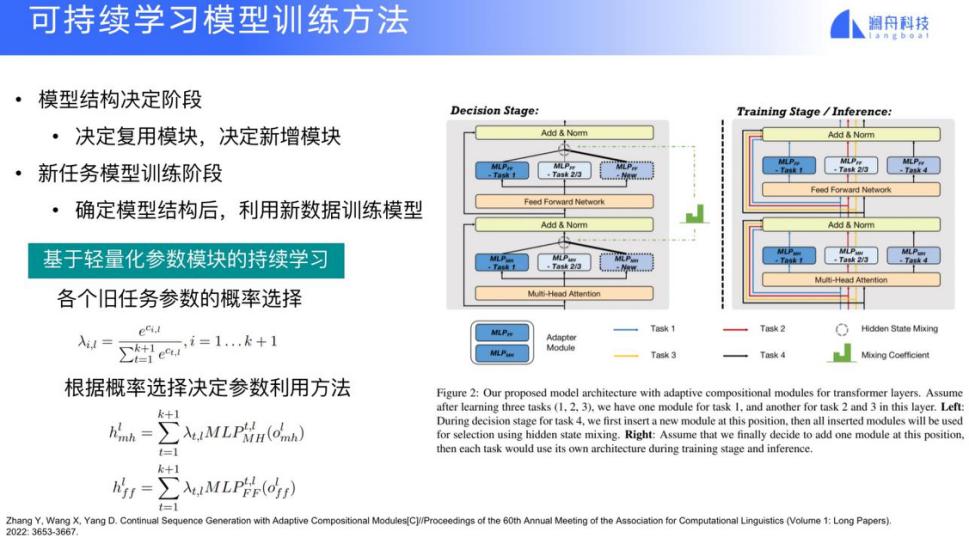
还要特别关注一个叫可持续学习的方法。通常在训练一个文本生成模型时,每添加一个要素,都可能重新训练或者调整网络。我们考虑在增加一个新要素时,能否复用(reuse)已有的网络。这里有一种研究方法是在层间加入一个自适应的组合模块,来进行轻量化的微调,提高训练效率。

当我们加入一些自适应的组合模块,只需调整需要调整的模块。并且在加入新任务时,最大限度地 reuse 已有的一些模块,来提高训练效率。这种具体的学习方法是当面对一个有新要素的文本生成任务,我们通过计算的方法来选择网络之间已有的自适应模块,选择跟训练目标最接近的模块,这样就从每一层到最后一层形成一个选择路径。如果没有一个特别合适的已有自适应模块,那么就添加一个新的自适应模块。然后再利用大规模的微调(fine-tune) 数据调整整个网络,就可以得到一个针对新要素的文本生成网络。
下面我解释一下文本生成中如何融入常识和知识。在真实世界中,无论是不同的场景,不同的领域,都有自己的一些特定知识体系,包括常识知识和事实知识。我们希望在文本生成中融合这些常识和知识。一种通用的方法是根据文本生成的输入和关键词或要素,来触发相应的知识库条目,并融入到生成模块中,以产生一个更好地体现知识和常识的输出。
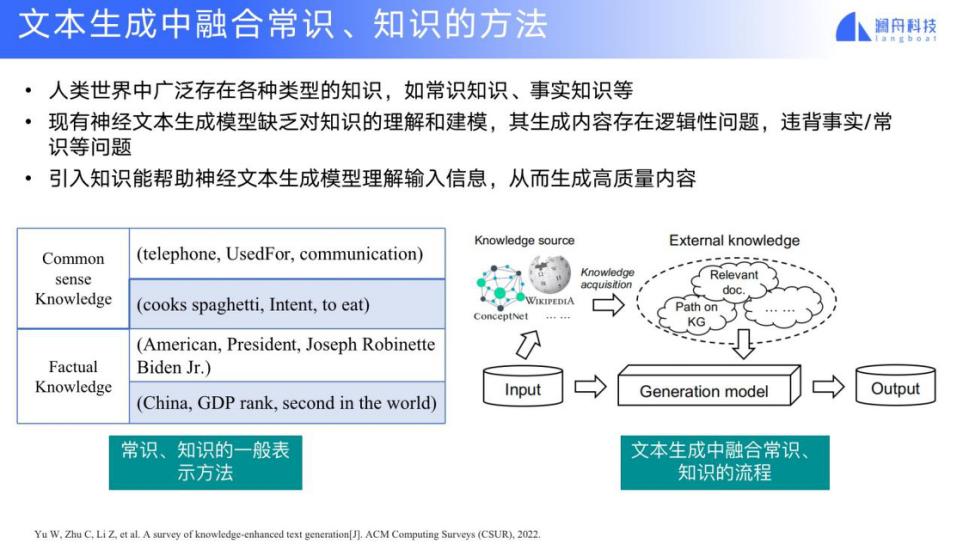
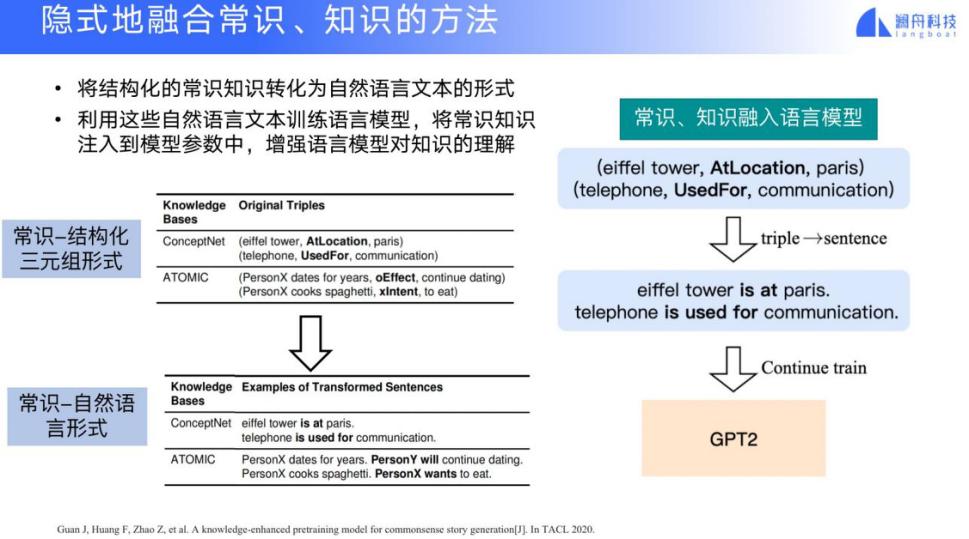
另一种方法是隐含地融合常识和知识,就是我们把常识 - 结构化的三元组转换成常识的自然语言描述形式,并把这些自然语言的描述形式加入到训练数据中继续训练,GPT 就是这种文本生成模型。
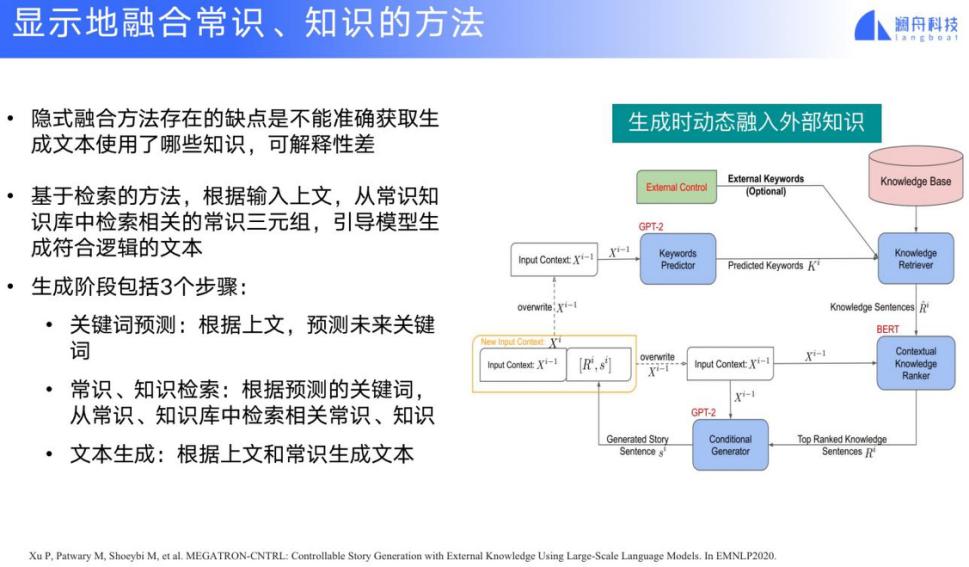
我们也可以显式地融合常识和知识,具体流程如下:首先根据上文来预测未来的关键词,从常识和知识库中检索相应的常识和知识条目,把检索结果加入到原有的上文中,并依此得到一个新的输出结果。
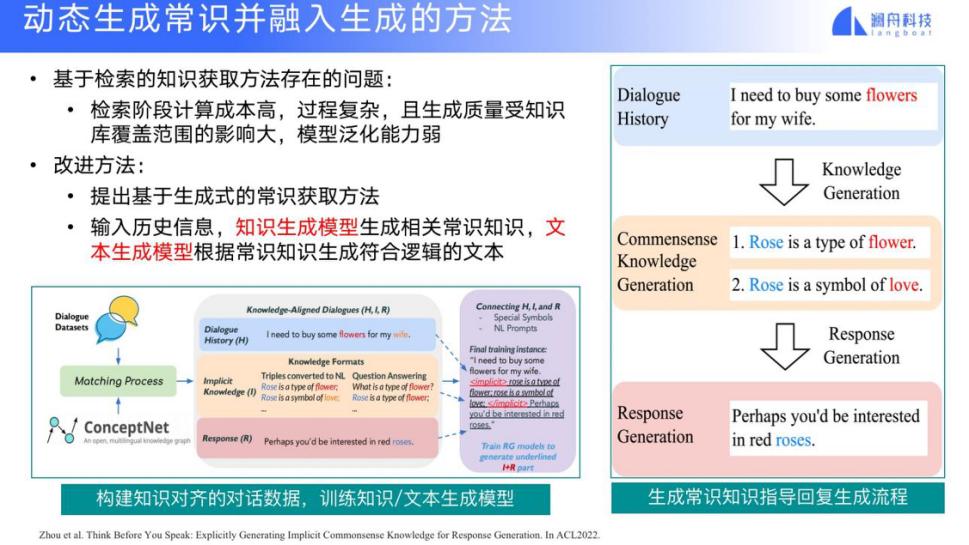
还有一种方法是根据输入得到一个结果,动态地生成一些参考知识条目,把这些知识条目再融入原输入来得到一个输出。这个任务就变成根据一个输入的句子,如何来触发(trigger)或者生成相应的知识条目。假设我们有大规模的对话 Q&A 和一个知识库,首先我们根据 Q&A 寻找出匹配的知识条目,得到训练文本,根据训练文本,输入一个句子,就可以触发或者生成一些新的知识条目,我们选择概率最大者加入到生成过程中。
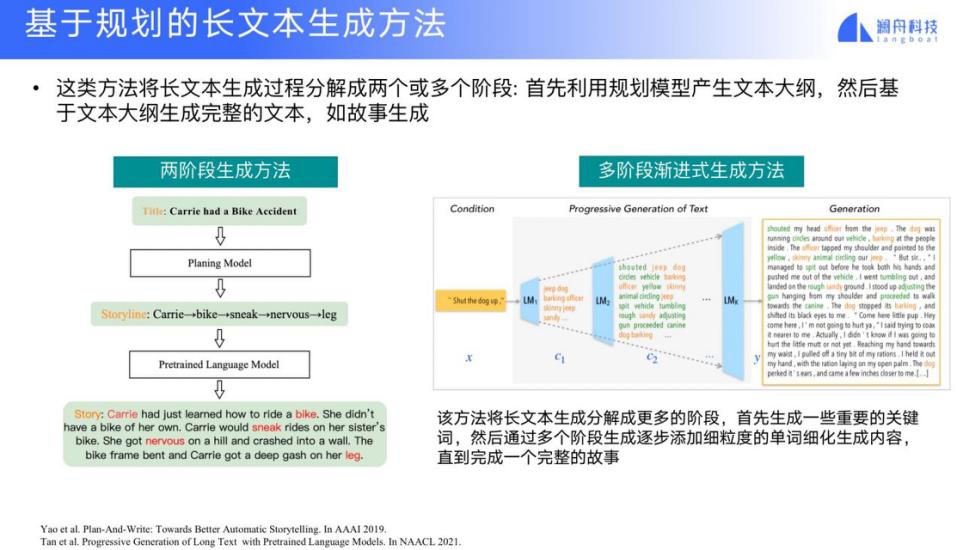
下面我再介绍一下长文本生成的方法。由于建模能力的问题,非常长的文本就没办法生成很好的结果了。一种简单的方法就是两阶段生成方法。
首先我们做一个 planning 的阶段,生成一些关键词来代表 storyline。把输入和 storyline 都加入到文本生成模块中,作为输入来产生一个更长的句子。这样的过程可以迭代分层,每次产生更多的 storyline,直到产生足够的 storyline,然后再去得到一个文本生成的结果。
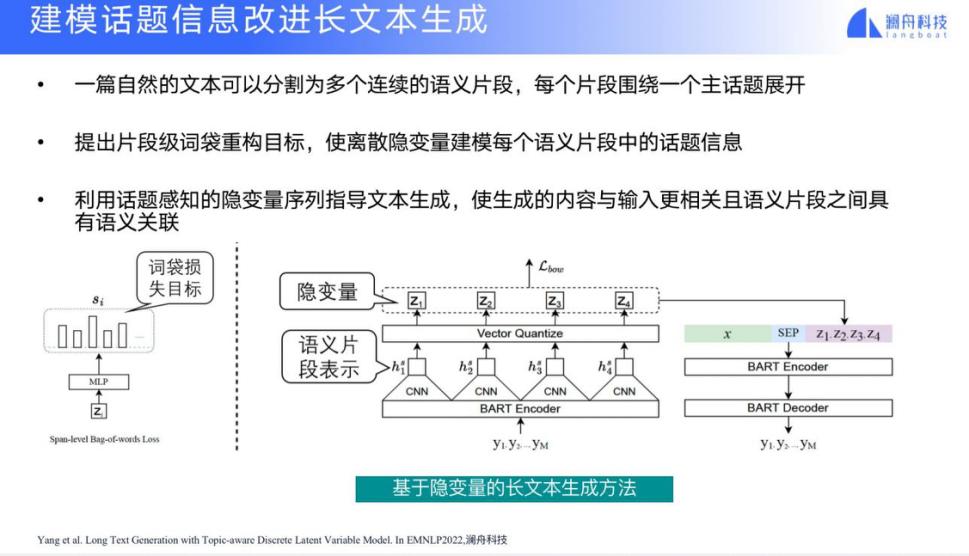
还有一种方法是基于隐变量的长文本生成方法。这种方法的思路是:一篇自然的文本可以分割为多个连续的语义片段,每个片段围绕一个主话题展开;提出片段级词袋重构目标,使离散隐变量建模每个语义片段中的话题信息;利用话题感知的隐变量序列指导文本生成,使生成的内容与输入更相关且语义片段之间具有语义关联。
我们也可以基于动态规划来做长文本生成。现在的两阶段长文本生成,规划和生成二者是分离的,存在错误累积问题。基于动态规划的方法就是将规划和生成联合在一个模型中,并给定一个文本生成的输入来动态产生一个隐变量(SN),再生成组成下一个句子的单词序列,同时生成代表下一个句子的隐变量,然后持续生成。
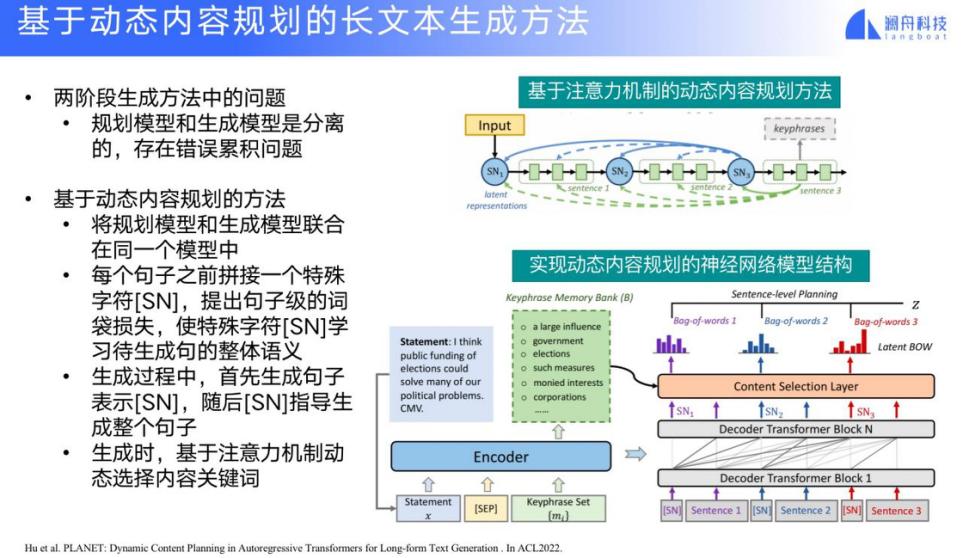
上图右是具体的流程示意图,给定输入,编码器的输出结果作为解码器的输入,解码器先输出代表一个句子的隐变量 SN_1,然后隐变量生成 Bag-of-words,用于词序列信息的学习,然后基于生成的前文和 SN_1 再生成下一个句子的隐变量,持续地进行输出。
这样就相当于先生成了一个句子的架构,再根据句子架构生成具体的词序列。这样就对整体句子结构有很好的控制能力。
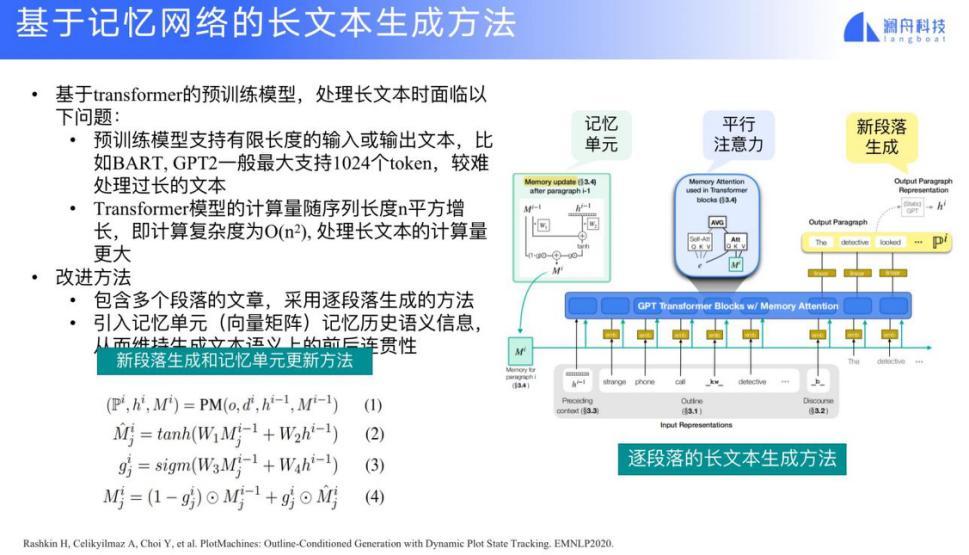
也可以利用记忆网络的长文本生成方式来做,每一层都加入一个记忆网络。在输出的时候,记忆网络跟当前 encoder 的结果一起决定输出的结果。我这里就不一一介绍记忆网络的训练公式了。
下面我介绍一下文本生成中解码方法的研究。文本生成一般是依靠一个编码器和一个解码器,解码器是逐词进行解码。
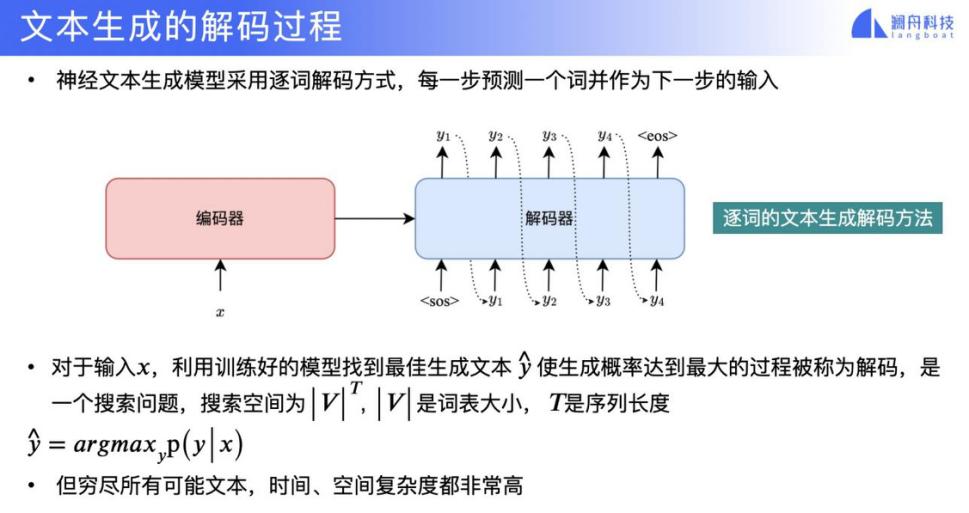
神经文本生成模型常用的解码策略是 Greedy search 和 Beam search。它们都存在一个问题,就是输出的时候可能出现重复的词或者片段,这个不容易控制。

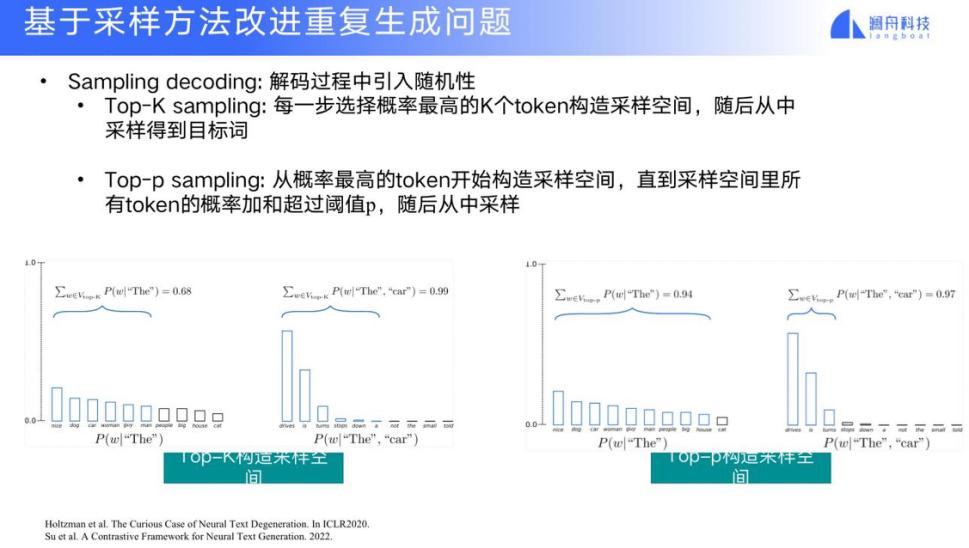
当前针对这个问题的两种已有方法,一个叫 Top-K k sampling,一个叫 Top-p sampling,都是从概率最高的 n 个词中采样,或在概率最高的空间内选择,随机选择输出的结果,再持续往下输出,这样就改进了多样性。
为了解决重复生成的问题,这类方法还引入了一种叫对比训练的方法。如果输出的结果跟前面已经生成的结果有很大的重复性,则对它进行一定程度的惩罚,以减少重复生成的情况,生成多样化的文本。
这里我简单总结一下,刚才我介绍了可控文本生成的关键技术、可控生成融入常识和知识、文本生成解码方法等等。

未来还有很多需要探索的方向,例如现在的可控主要集中在情感关键词方面,而篇章的可控,多样性的可控,细粒度的可控目前都做得不够。在融入常识和知识方面,当前的方法都是利用知识图谱中的三元组,这种方法知识获取难度比较高,还需要进行有效改进。
长文本生成则需要对主题一致性、事实一致性、文章层次结构和前后逻辑进行学习。还有记忆网络的能力如何进一步提升?这些都需要我们进行更多的探索。
最后,在多样化解码能力方面,从词汇到短语到单句到跨句,都有一些改进空间。
我没有提到文本生成的评价体系、评测集和自动评测方法,也没有提到 AI 伦理,比如如何防止生成有安全隐患甚至有害的文本,但是这些都非常非常重要。这里由于时间关系我没有展开讨论。
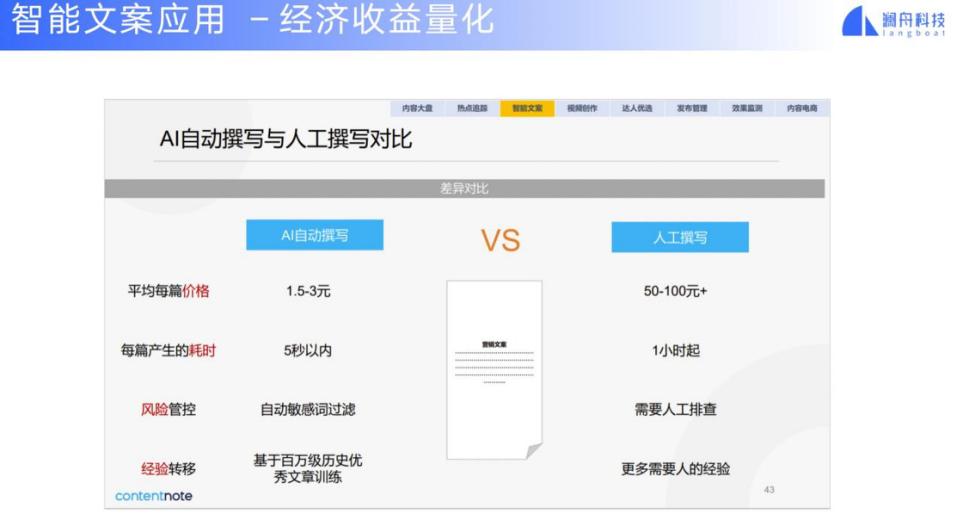
下面我介绍一下澜舟科技部分的文本生成项目。我们首先搭建了澜舟文本生成的平台。基于底层的大规模数据(包括通用的数据,垂直的数据和特定任务的数据),我们建立了一个轻量级神经网络生成模型,它是 encoder-decoder 架构。我们根据垂直领域做了一些适配,包括数据的获取、对垂直领域弱标注学习数据的构建、细粒度可控文本生成方法和篇章建模等等。基于这样的技术体系,我们就可以做一些具体任务或构建垂直领域的生成引擎。目前我们已经做了营销文案引擎、文章摘要、故事生成、散文小说、文本复述、研报生成等各个方面。
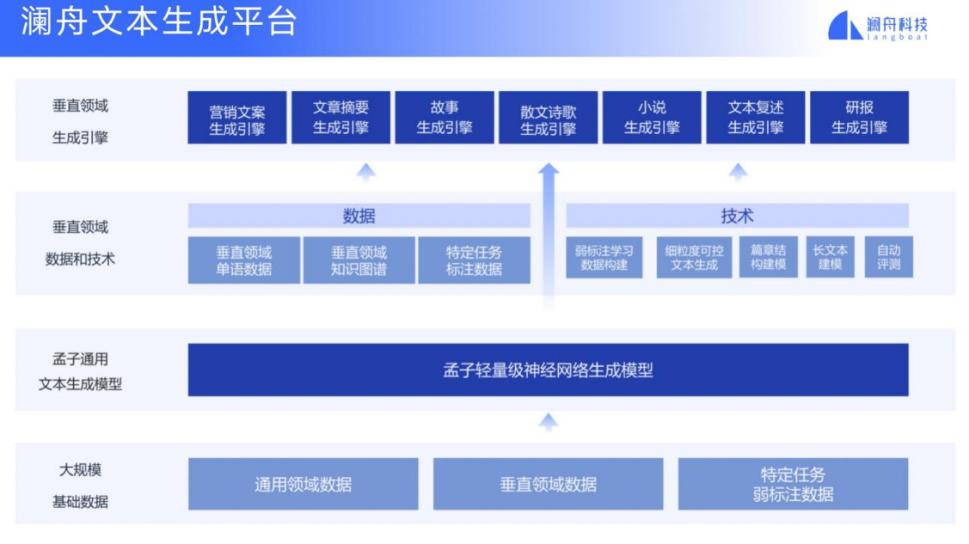
我们的技术特点如下图所示,包括多属性的可控文本生成、多样化的生成、基于知识图谱嵌入进行文本生成。

在长文本生成方面,我们也做了很多研究,轻量化微调使模型效率更高,并做了很多的多任务联合建模来支持多种场景。
我们也做了一些内容和风格的定制化,以及文本自动评测,支持多行业多领域。
下面我就简单介绍几个典型的项目。
第一个就是网文生成,比如用户输入下图所示的一些关键词,电脑会自动生成一个非常丰富的句子,供网文写手来参考。
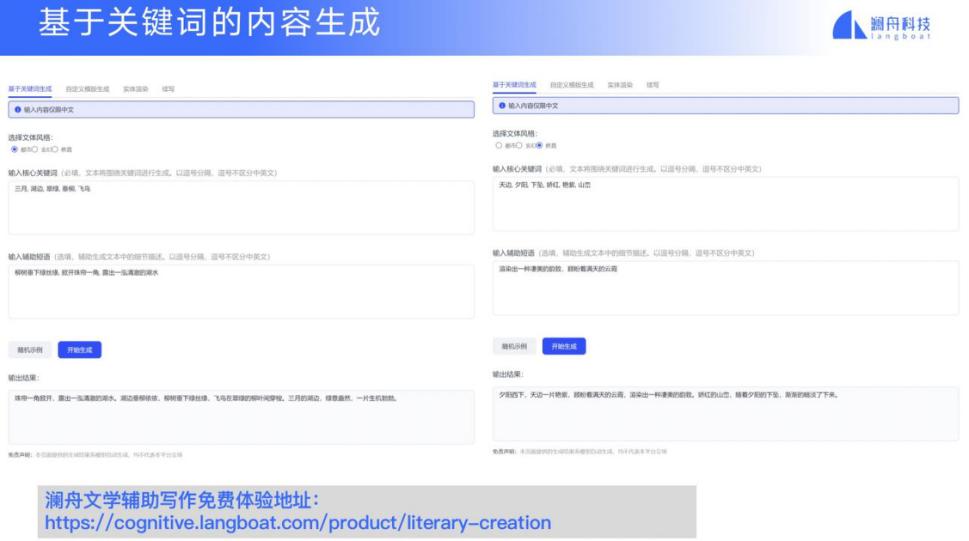
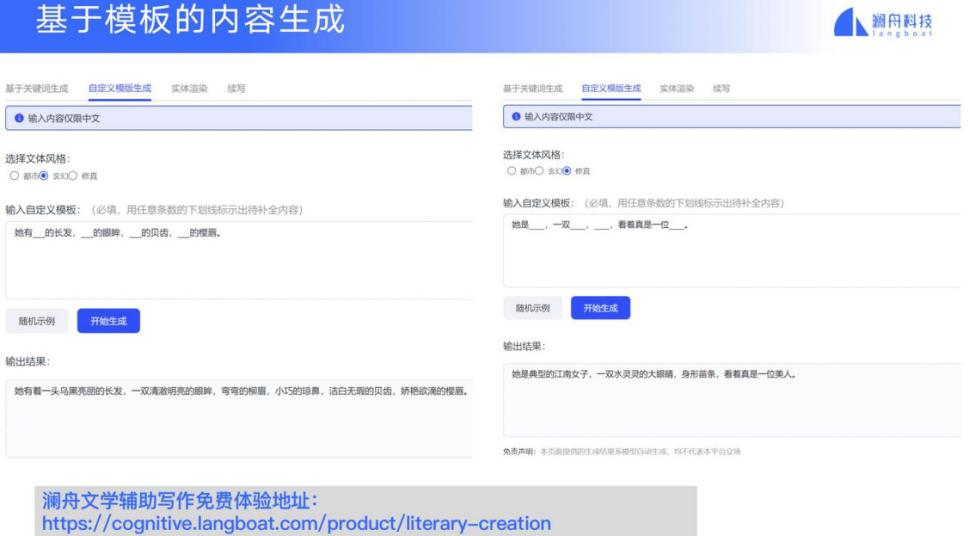
有些网文写手有自己的写作模板,我们接受他的模板,就可以生成更加丰富的句子。
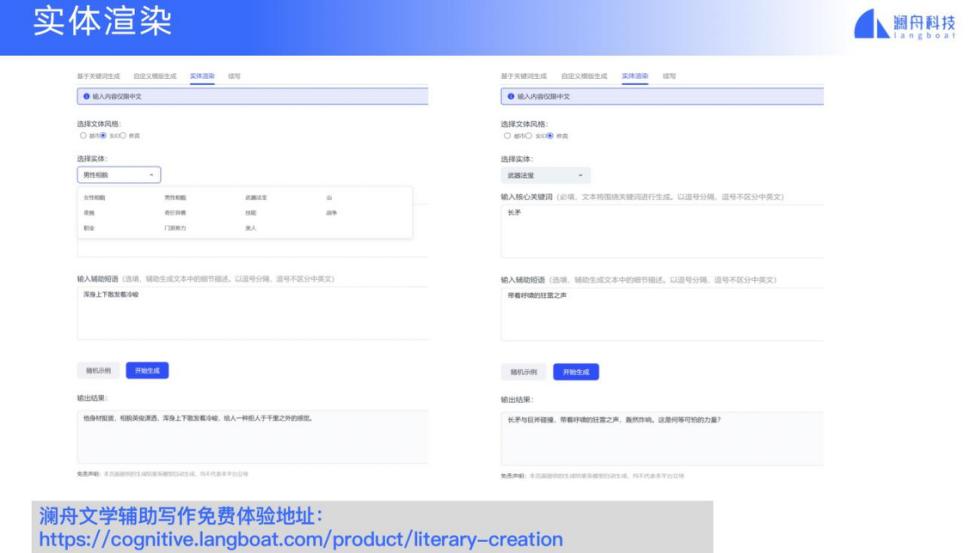
有的网文写手需要对某些实体进行渲染,比如武士、美女等,这就需要网文写手写入一些关键词,然后平台会根据他的思路,把句子生成得更漂亮,供他参考。
我们也提供了续写功能,用户可以输入自己写的一句话或一段话,电脑自动往下续写,生成 n 个可供选择的输出结果供写手挑选。
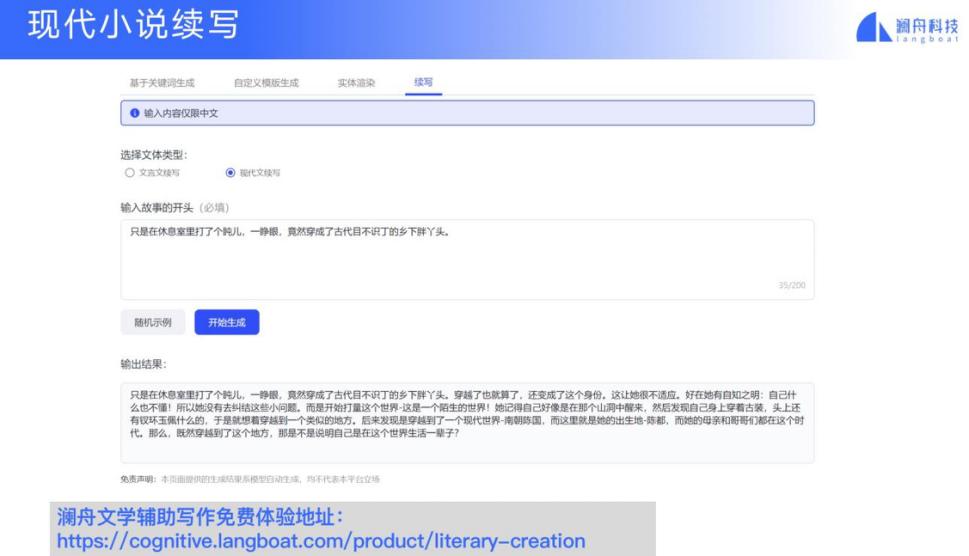
我们的平台也可以做风格迁移(style transfer),例如从现代文 transfer 到文言文,也可以续写文言文。
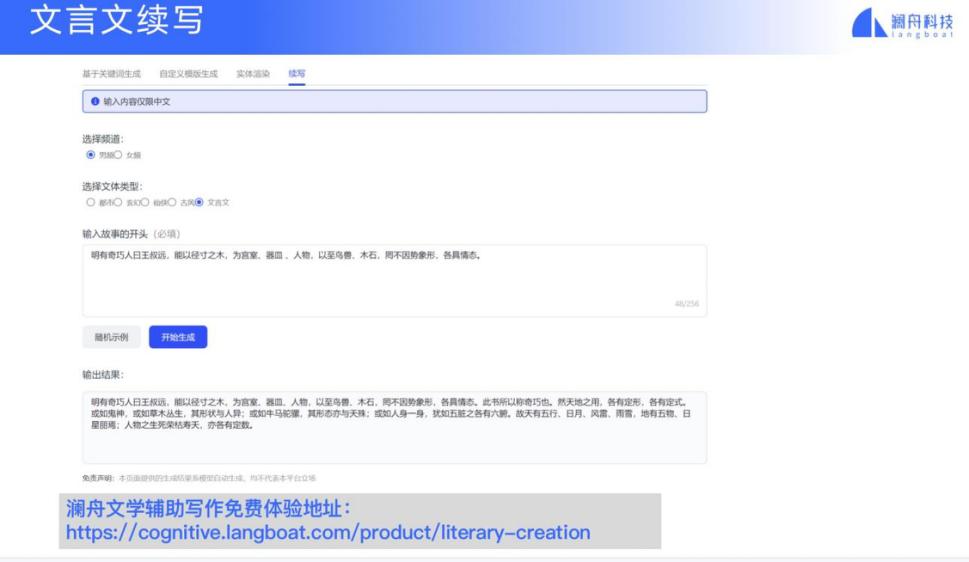
我们也将文本生成的技术用于营销文案生成。营销文案原来都是请写手去写的,成本比较高,也比较费时。利用自动写作营销文案的方式,就可以快速生成多样化的营销文案。
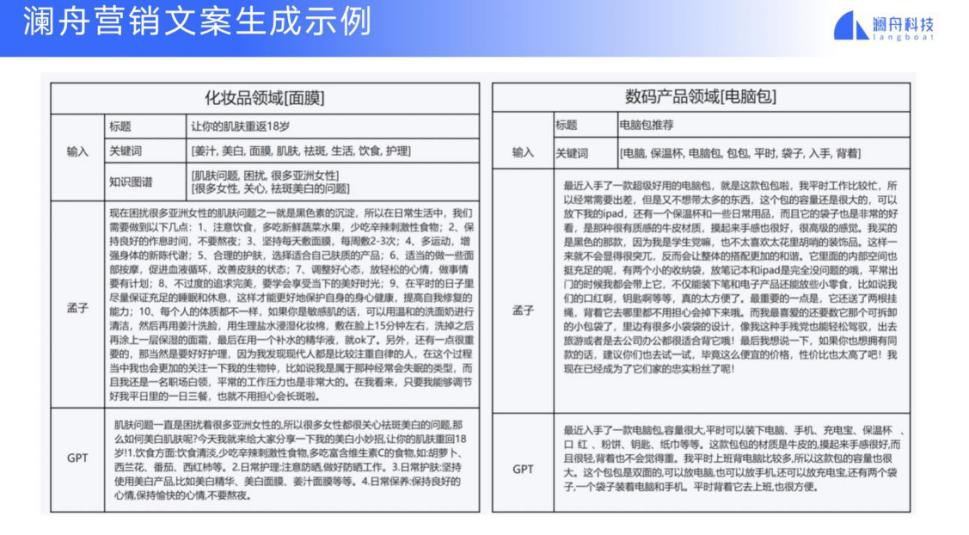
例如对于化妆品领域的用户,可以输入标题「让你的肌肤重返 18 岁」,也可以输入一些关键词,比如姜汁、美白,或者输入一些知识图谱,我们的文本生成系统(孟子模型)就可以生成一篇丰富多彩、前后连贯的营销文案。
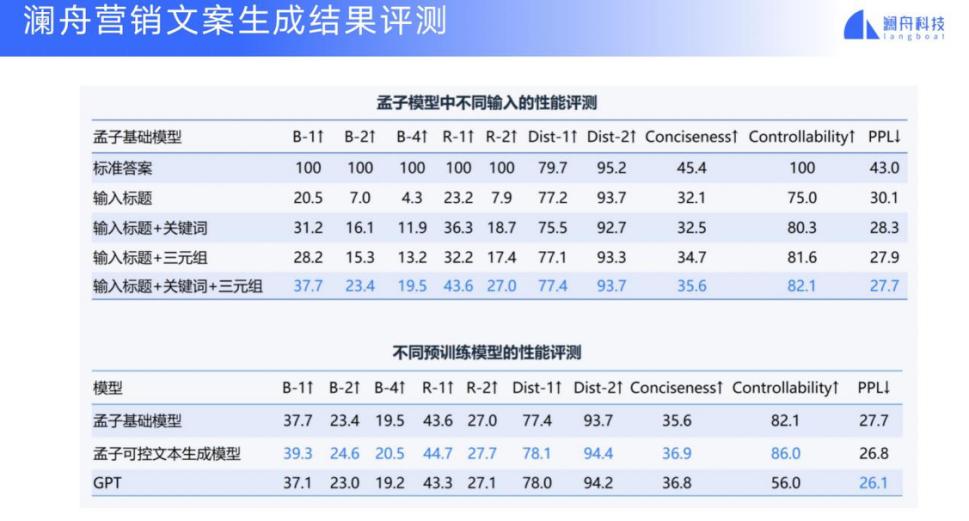
我们也做了一些可控文本生成的评测,探究只输入标题、关键词,或者加上三元组,模型生成文本的可控能力是否有所改进。
2021 年,我们与合作伙伴数说故事一起合作,打造了一款自动化写作产品 contentnote。

使用这款产品,用户可以选择协作的模板,提供产品的名字和若干关键词,就可以得到一篇营销文案。
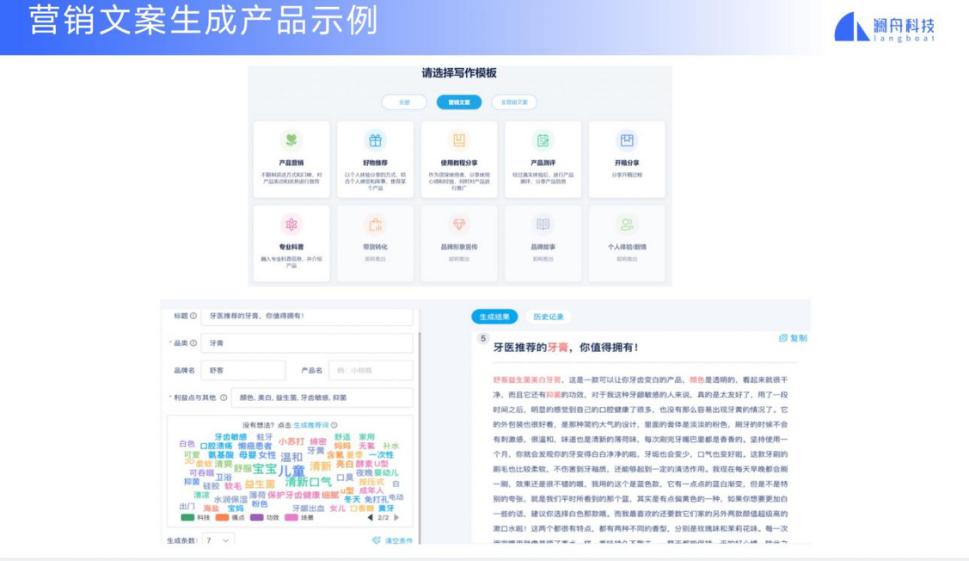
由于我们利用了一些多语言技术,因此也可以生成多语言的营销文案,包括中文、英文、日文和葡萄牙语等等。

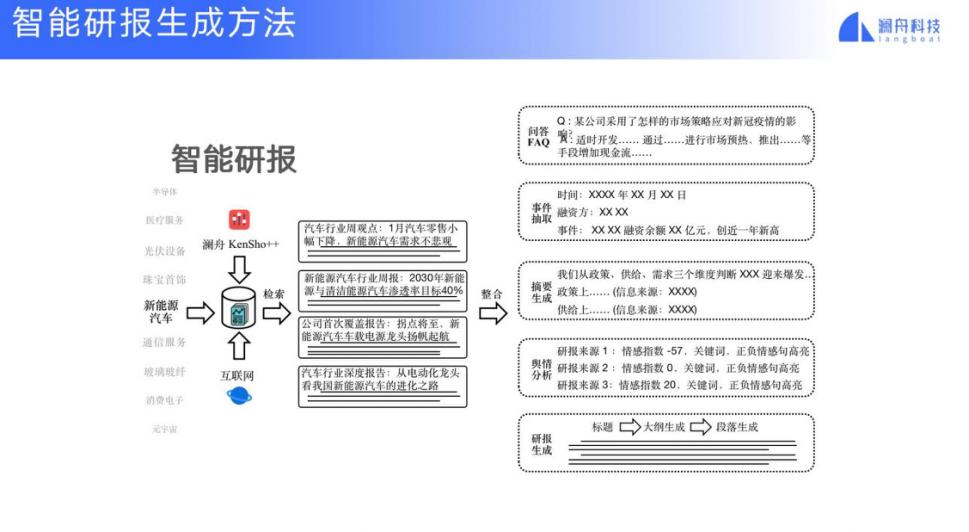
基于我们的技术,我们也在做智能研报生成的应用。所谓智能研报,就是指用户想写某一个主题的研报,我们的系统会自动从互联网和用户提交的数据中,抽取重要的材料,基于这些材料,生成问答对、事件摘要、舆情分析,基于这些要素就可以得到一个研报的生成结果 —— 是由标题到大纲到段落生成,并填充上一步生成的要素。
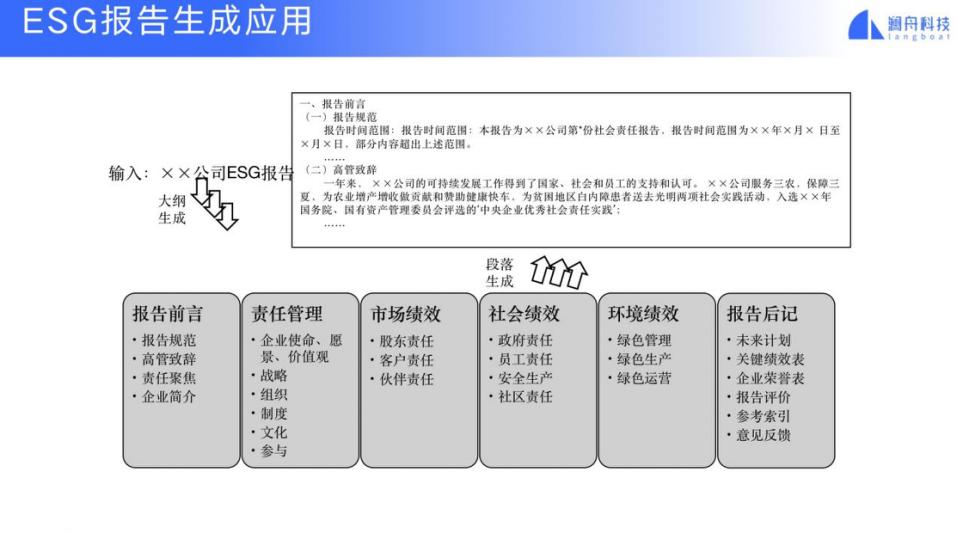
我们还尝试了 ESG 报告生成,根据用户的输入生成该公司的 ESG 报告。ESG 报告是现在很多企业都需要提交的一个综合报告,它体现了一个企业的治理能力。ESC 报告基本包含几大要素,每大要素又有一些要点。我们根据文本生成技术和信息抽取技术,就可以抽取重要信息并最终生成一个完整的报告。
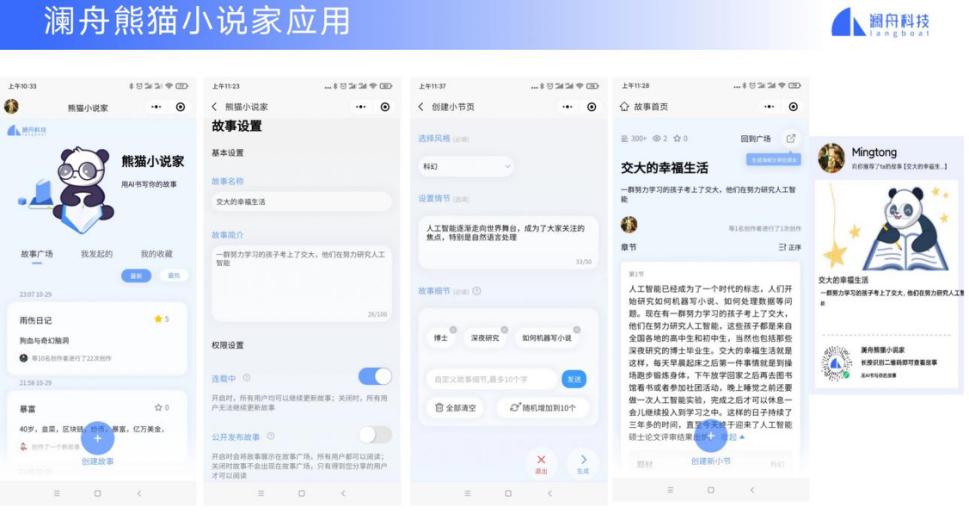
我们基于澜舟的文本生成技术,也做了一些 ToC 的应用,目前做了熊猫小说家微信小程序的应用。用户注册使用并与朋友分享,就可以写成一系列的小说接龙。如下图所示,用户设置人设、故事梗概、主题,添加一些关键词,就可以创造一段小说。分享给朋友之后就可以用接龙的方式生成下一段小说。
基于这样的技术,我们也做了专业论文生成写作的尝试 —— 用户提交若干关键词,系统可以进行扩写,生成包含用户期望信息的推荐例句。澜舟论文助写(Langboat Paper Assistant 简称 LPA)提供了组句和续写功能。
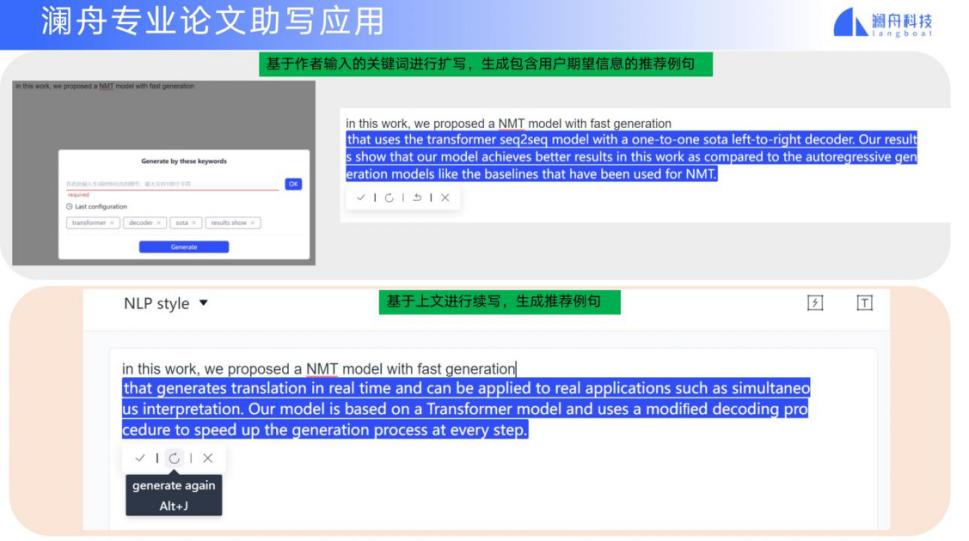
下面的视频演示了澜舟论文助写应用的组句和续写功能:
此外,我们也做了一些文图生成,因为今天我的演讲主题是文本生成,所以我就简单说一下我们关于文图生成的工作。当前,Stable Diffusion 模型是针对英文信息、在英文大数据上学习的,对中文的一些要素(比如雷锋、长城、黄山),Stable Diffusion 模型的生成效果并不好。所以我们对数据进行了新的整理,另外加入了一些中文的界面,加入了一些中国人常见的风格选择。用户输入一些中文信息,就可以得到一个有中文色彩的画面。

我今天的演讲主要介绍了文本生成的一些关键技术,又介绍了澜舟科技在文本生成领域的一些实践。由于时间关系,我的演讲就到这里,请大家多多指正,谢谢大家。© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《AIGC的浪潮下,文本生成发展得怎么样了?》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

