- +1
图像预处理库CV-CUDA开源了,打破预处理瓶颈
原创 Synced 机器之心
机器之心原创
作者:思
当 CPU 图像预处理成为视觉任务的瓶颈,最新开源的CV-CUDA,将为图像预处理算子提速百倍。
在如今信息化时代中,图像或者说视觉内容早已成为日常生活中承载信息最主要的载体,深度学习模型凭借着对视觉内容强大的理解能力,能对其进行各种处理与优化。
然而在以往的视觉模型开发与应用中,我们更关注模型本身的优化,提升其速度与效果。相反,对于图像的预处理与后处理阶段,很少认真思考如何去优化它们。所以,当模型计算效率越来越高,反观图像的预处理与后处理,没想到它们竟成了整个图像任务的瓶颈。
为了解决这样的瓶颈,NVIDIA 携手字节跳动机器学习团队开源众多图像预处理算子库CV-CUDA,它们能高效地运行在 GPU 上,算子速度能达到 OpenCV(运行在 CPU)的百倍左右。如果我们使用 CV-CUDA 作为后端替换OpenCV 和 TorchVision,整个推理的吞吐量能达到原来的二十多倍。此外,不仅是速度的提升,同时在效果上 CV-CUDA 在计算精度上已经对齐了OpenCV,因此训练推理能无缝衔接,大大降低工程师的工作量。
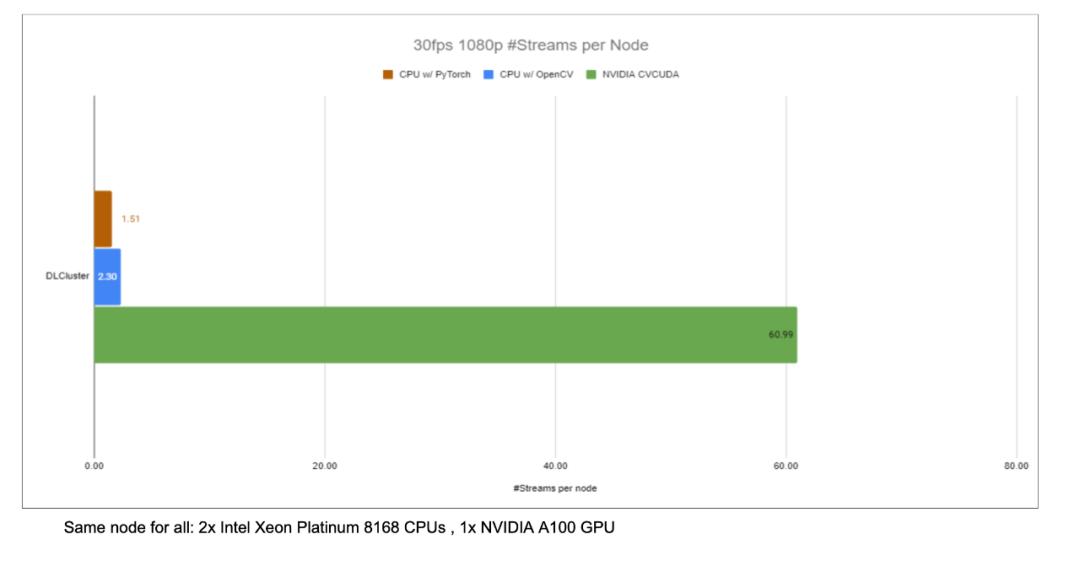
以图像背景模糊算法为例,将CV-CUDA替换 OpenCV作为图像预/后处理的后端,整个推理过程吞吐量能加20 多倍。
如果小伙伴们想试试更快、更好用的视觉预处理库,可以试试这一开源工具。
开源地址:https://github.com/CVCUDA/CV-CUDA
图像预/后处理已成为 CV 瓶颈
很多涉及到工程与产品的算法工程师都知道,虽然我们常常只讨论模型结构和训练任务这类「前沿研究」,但实际要做成一个可靠的产品,中间会遇到很多工程问题,反而模型训练是最轻松的一环了。
图像预处理就是这样的工程难题,我们也许在实验或者训练中只是简单地调用一些API 对图像进行几何变换、滤波、色彩变换等等,很可能并不是特别在意。但是当我们重新思考整个推理流程时会发现,图像预处理已经成为了性能瓶颈,尤其是对于预处理过程复杂的视觉任务。
这样的性能瓶颈,主要体现在 CPU 上。一般而言,对于常规的图像处理流程,我们都会先在CPU 上进行预处理,再放到 GPU 运行模型,最后又会回到 CPU,并可能需要做一些后处理。
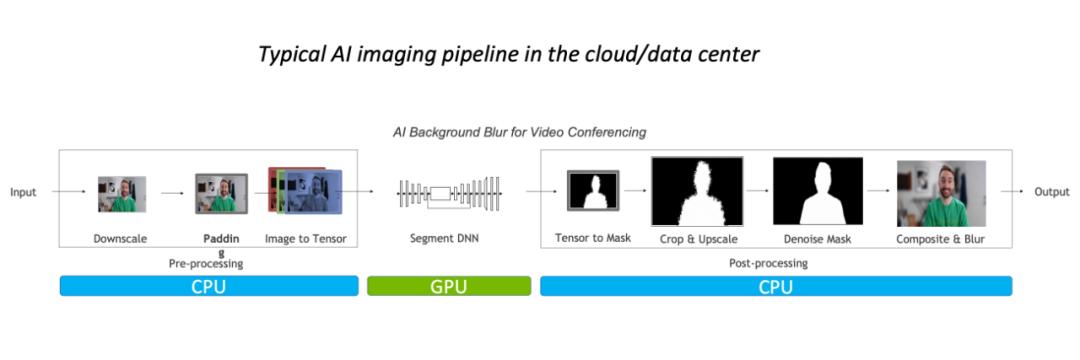
以图像背景模糊算法为例,常规的图像处理流程中预\后处理主要在 CPU 完成,占据整体 90% 的工作负载,其已经成为该任务的瓶颈。
因此对于视频应用,或者 3D 图像建模等复杂场景,因为图像帧的数量或者图像信息足够大,预处理过程足够复杂,并且延迟要求足够低,优化预/后处理算子就已经迫在眉睫了。一个更好地做法,当然是替换掉 OpenCV,使用更快的解决方案。
为什么 OpenCV 仍不够好?
在 CV 中,应用最广泛的图像处理库当然就是长久维护的OpenCV 了,它拥有非常广泛的图像处理操作,基本能满足各种视觉任务的预/后处理所需。但是随着图像任务负载的加大,它的速度已经有点慢慢跟不上了,因为OpenCV 绝大多数图像操作都是 CPU 实现,缺少 GPU 实现,或者 GPU 实现本来就存在一些问题。
在NVIDIA与字节跳动算法同学的研发经验中,他们发现OpenCV 中那些少数有 GPU 实现的算子存在三大问题:
部分算子的 CPU 和 GPU 结果精度无法对齐;
部分算子 GPU 性能比 CPU 性能还弱;
同时存在各种CPU算子与各种 GPU 算子,当处理流程需要同时使用两种,就额外增加了内存与显存中的空间申请与数据迁移/数据拷贝;
比如说第一个问题结果精度无法对齐,NVIDIA与字节跳动算法同学会发现,当我们在训练时OpenCV 某个算子使用了 CPU,但是推理阶段考虑到性能问题,换而使用OpenCV对应的GPU 算子,也许CPU 和 GPU 结果精度无法对齐,导致整个推理过程出现精度上的异常。当出现这样的问题,要么换回 CPU 实现,要么需要费很多精力才有可能重新对齐精度,是个不好处理的难题。
既然 OpenCV 仍不够好,可能有读者会问,那Torchvision 呢?它其实会面临和 OpenCV 一样的问题,除此之外,工程师部署模型为了效率更可能使用 C++实现推理过程,因此将没办法使用Torchvision而需要转向 OpenCV 这样的 C++ 视觉库,这不就带来了另一个难题:对齐Torchvision与OpenCV的精度。
总的来说,目前视觉任务在 CPU 上的预/后处理已经成为了瓶颈,然而当前OpenCV 之类的传统工具也没办法很好地处理。因此,将操作迁移到GPU 上,完全基于CUDA实现的高效图像处理算子库 CV-CUDA,就成为了新的解决方案。
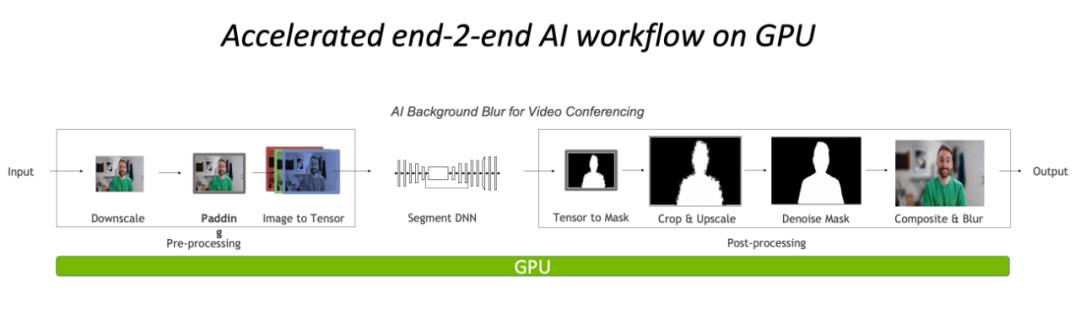
完全在 GPU 上进行预处理与后处理,将大大降低图像处理部分的CPU 瓶颈。
GPU 图像处理加速库: CV-CUDA
作为基于 CUDA 的预/后处理算子库,算法工程师可能最期待的是三点:足够快、足够通用、足够易用。NVIDIA 和字节跳动的机器学习团队联合开发的 CV-CUDA 正好能满足这三点,利用 GPU 并行计算能力提升算子速度,对齐OpenCV 操作结果足够通用,对接 C++/Python 接口足够易用。
CV-CUDA的速度
CV-CUDA的快,首先体现在高效的算子实现,毕竟是NVIDIA 写的,CUDA 并行计算代码肯定经过大量的优化的。其次是它支持批量操作,这就能充分利用GPU设备的计算能力,相比 CPU 上一张张图像串行执行,批量操作肯定是要快很多的。最后,还得益于CV-CUDA 适配的 Volta、Turing、Ampere 等 GPU 架构,在各 GPU 的 CUDA kernel 层面进行了性能上的高度优化,从而获得最好的效果。也就是说,用的 GPU 卡越好,其加速能力越夸张。
正如前文的背景模糊吞吐量加速比图,如果采用CV-CUDA 替代 OpenCV 和 TorchVision 的前后处理后,整个推理流程的吞吐率提升20 多倍。其中预处理对图像做 Resize、Padding、Image2Tensor 等操作,后处理对预测结果做的Tensor2Mask、Crop、Resize、Denoise 等操作。
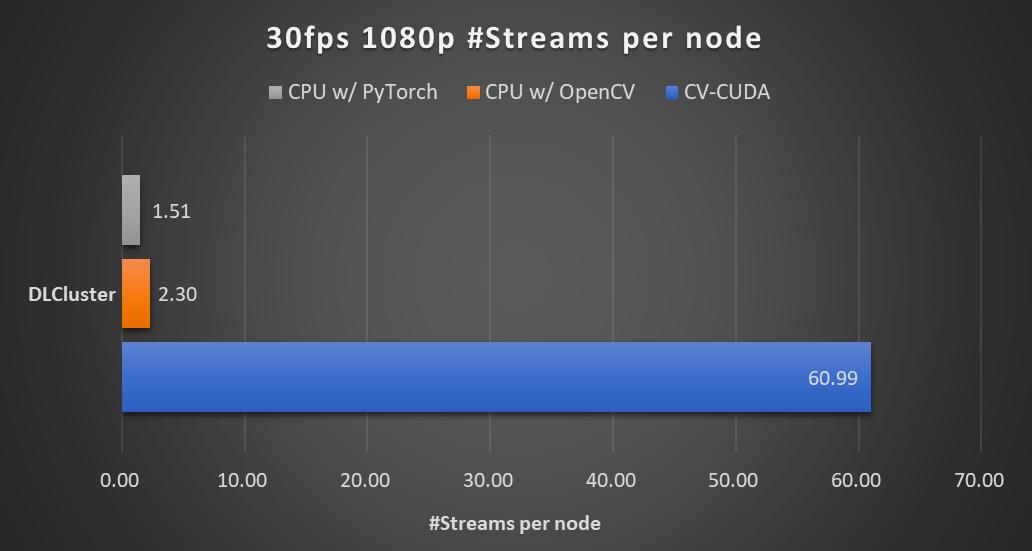
在同一个计算节点上(2x Intel Xeon Platinum 8168 CPUs,1x NVIDIA A100 GPU),以 30fps 的帧率处理 1080p 视频,采用不同 CV 库所能支持的最大的并行流数。测试采用了 4 个进程,每个进程 batchSize 为 64。
对于单个算子的性能,NVIDIA和字节跳动的小伙伴也做了性能测试,很多算子在GPU 上的吞吐量能达到 CPU 的百倍。
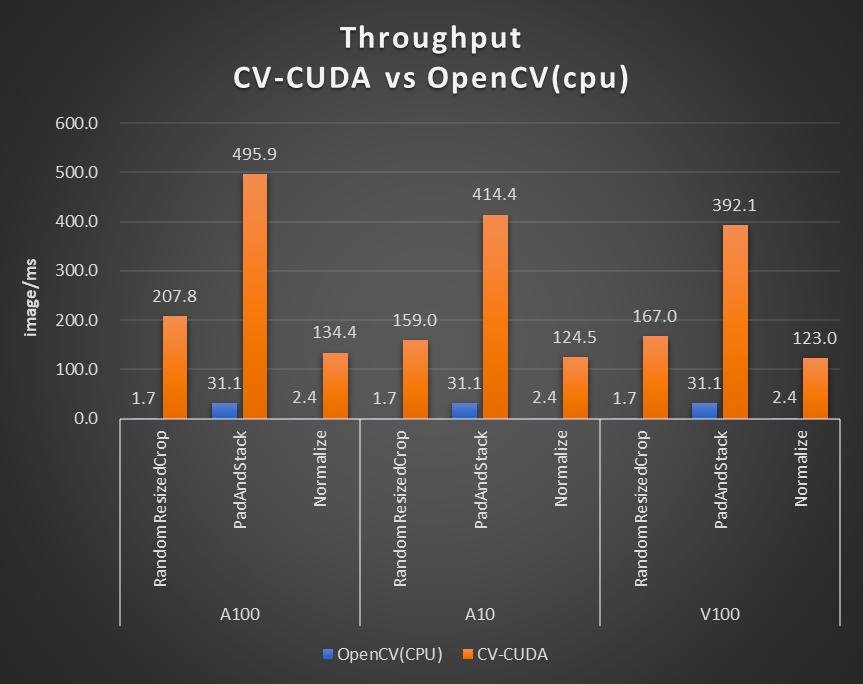
图片大小为 480*360,CPU 选择为 Intel(R) Core(TM) i9-7900X,BatchSize 大小为 1,进程数为 1
尽管预/后处理算子很多都不是单纯的矩阵乘法等运算,为了达到上述高效的性能,CV-CUDA 其实做了很多算子层面的优化。例如采用大量的 kernel 融合策略,减少了 kernel launch 和 global memory 的访问时间;优化访存以提升数据读写效率;所有算子均采用异步处理的方式,以减少同步等待的耗时等等。
CV-CUDA的通用与灵活
运算结果的稳定,对于实际的工程可太重要了,就比如常见的 Resize 操作,OpenCV、OpenCV-gpu 以及 Torchvision 的实现方式都不一样,那从训练到部署,就会多很多工作量以对齐结果。
CV-CUDA在设计之初,就考虑到当前图像处理库中,很多工程师习惯使用 OpenCV 的 CPU 版本,因此在设计算子时,不管是函数参数还是图像处理结果上,尽可能对齐 OpenCV CPU 版本的算子。因此从OpenCV 迁移到 CV-CUDA,只需要少量改动就能获得一致的运算结果,模型也就不必要重新训练。
此外,CV-CUDA是从算子层面设计的,因此不论模型的预/后处理流程是什么样的,其都能自由组合,具有很高的灵活性。
字节跳动机器学习团队表示,在企业内部训练的模型多,需要的预处理逻辑也多种多样有许多定制的预处理逻辑需求。CV-CUDA 的灵活性能保证每个 OP 都支持 stream 对象和显存对象(Buffer和Tensor类,内部存储了显存指针)的传入,从而能更加灵活地配置相应的 GPU 资源。每个 op 设计开发时,既兼顾了通用性,也能按需提供定制化接口,能够覆盖图片类预处理的各种需求。
CV-CUDA的易用
可能很多工程师会想着,CV-CUDA 涉及到底层 CUDA 算子,那用起来应该比较费劲?但其实不然,即使不依赖更上层的 API,CV-CUDA本身底层也会提供 Image 等结构体,提供Allocator 类,这样在 C++上调起来也不麻烦。此外,往更上层,CV-CUDA 提供了 PyTorch、OpenCV 和 Pillow 的数据转化接口,工程师能快速地以之前熟悉的方式进行算子替换与调用。
此外,因为CV-CUDA同时拥有 C++接口与 Python 接口,它能同时用于训练与服务部署场景,在训练时用Python 接口跟快速地验证模型能力,在部署时利用C++接口进行更高效地预测。CV-CUDA免于繁琐的预处理结果对齐过程,提高了整体流程的效率。
CV-CUDA进行 Resize 的 C++接口
实战,CV-CUDA怎么用
如果我们在训练过程中使用CV-CUDA的 Python 接口,那其实使用起来就会很简单,只需要简单几步就能将原本在 CPU 上的预处理操作都迁移到 GPU 上。
以图片分类为例,基本上我们在预处理阶段需要将图片解码为张量,并进行裁切以符合模型输入大小,裁切完后还要将像素值转化为浮点数据类型并做归一化,之后传到深度学习模型就能进行前向传播了。下面我们将从一些简单的代码块,体验一下CV-CUDA 是如何对图片进行预处理,如何与Pytorch进行交互。

常规图像识别的预处理流程,使用CV-CUDA将会把预处理过程与模型计算都统一放在GPU 上运行。
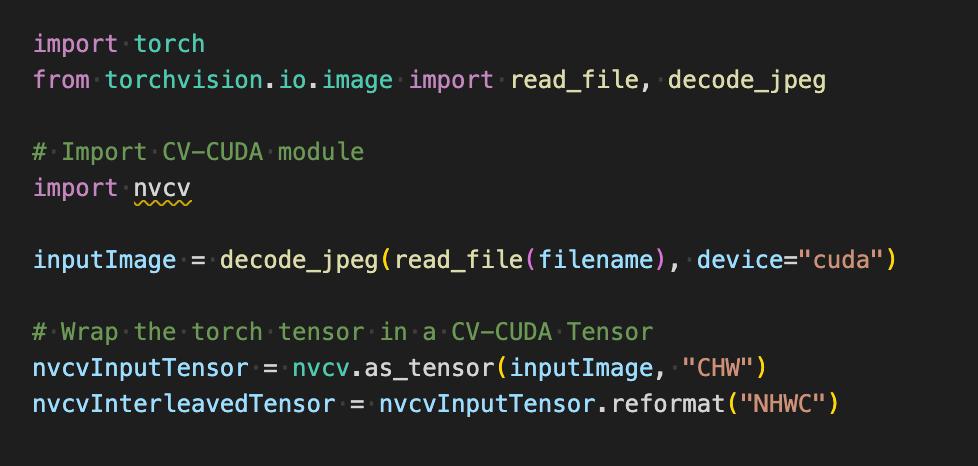
如下在使用 torchvision 的 API 加载图片到 GPU之后,Torch Tensor 类型能直接通过 as_tensor 转化为CV-CUDA 对象 nvcvInputTensor,这样就能直接调用CV-CUDA 预处理操作的 API,在 GPU 中完成对图像的各种变换。
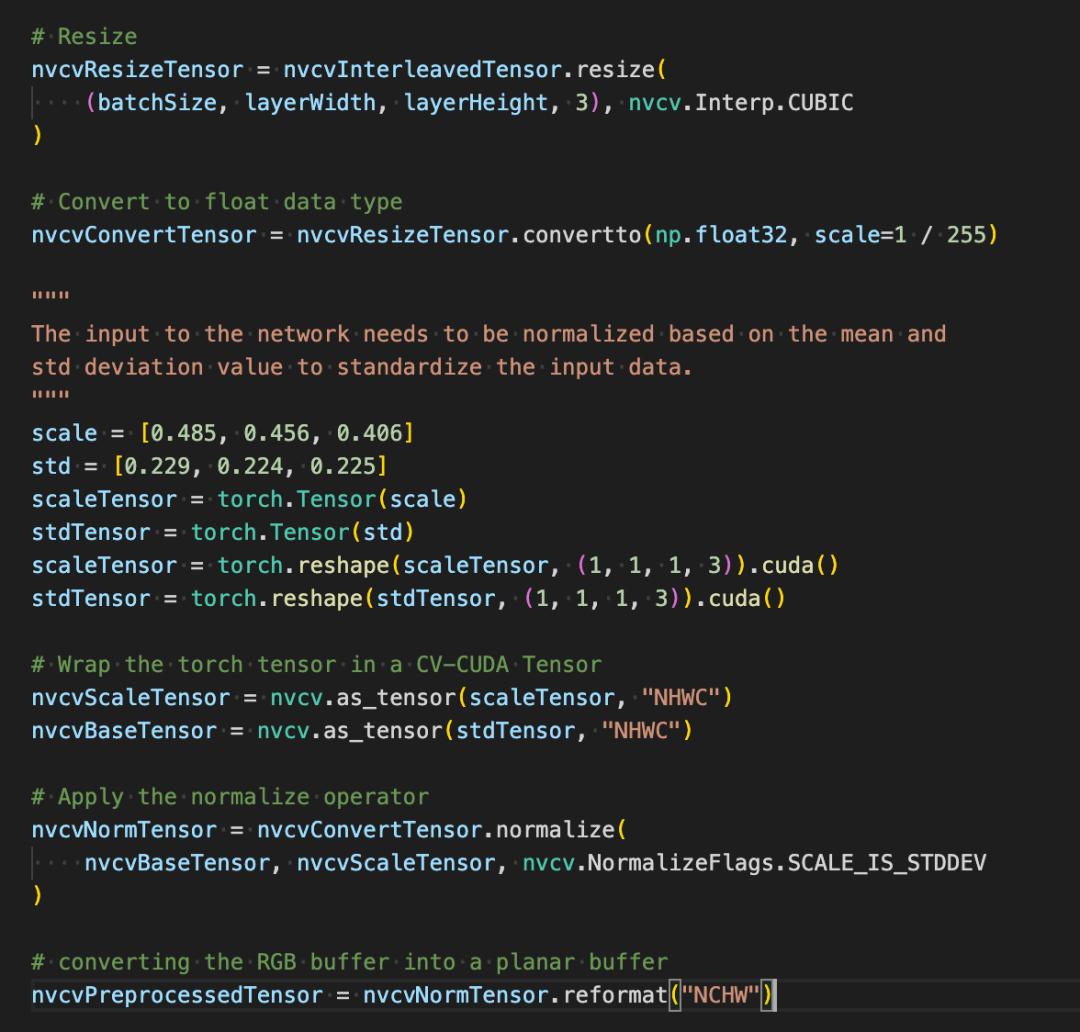
如下几行代码将借助 CV-CUDA 在 GPU 中完成图像识别的预处理过程:裁剪图像并对像素进行归一化。其中resize() 将图像张量转化为模型的输入张量尺寸;convertto()将像素值转化为单精度浮点值;normalize()将归一化像素值,以令取值范围更适合模型进行训练。
CV-CUDA 各种预处理操作的使用与 OpenCV 或 Torchvision中的不会有太大区别,只不过简单调个方法,其背后就已经在 GPU 上完成运算了。
现在借助借助 CV-CUDA 的各种 API,图像分类任务的预处理已经都做完了,其能高效地在GPU 上完成并行计算,并很方便地融合到PyTorch 这类主流深度学习框架的建模流程中。剩下的,只需要将CV-CUDA对象nvcvPreprocessedTensor 转化为Torch Tensor 类型就能馈送到模型了,这一步同样很简单,转换只需一行代码:
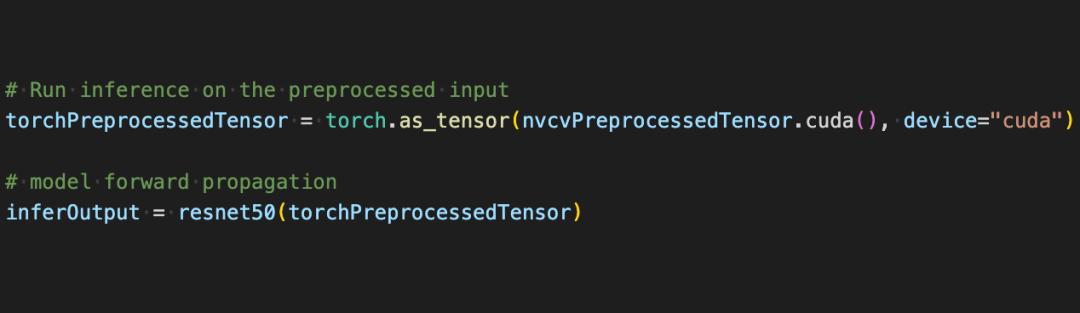
通过这个简单的例子,很容易发现CV-CUDA 确实很容易就嵌入到正常的模型训练逻辑中。如果读者希望了解更多的使用细节,还是可以查阅前文CV-CUDA的开源地址。
CV-CUDA对实际业务的提升
CV-CUDA实际上已经经过了实际业务上的检验。在视觉任务,尤其是图像有比较复杂的预处理过程的任务,利用 GPU 庞大的算力进行预处理,能有效提神模型训练与推理的效率。CV-CUDA 目前在抖音集团内部的多个线上线下场景得到了应用,比如搜索多模态,图片分类等。
字节跳动机器学习团队表示,CV-CUDA 在内部的使用能显著提升训练与推理的性能。例如在训练方面,字节跳动一个视频相关的多模态任务,其预处理部分既有多帧视频的解码,也有很多的数据增强,导致这部分逻辑很复杂。复杂的预处理逻辑导致 CPU 多核性能在训练时仍然跟不上,因此采用CV-CUDA将所有 CPU 上的预处理逻辑迁移到 GPU,整体训练速度上获得了 90%的加速。注意这可是整体训练速度上的提升,而不只是预处理部分的提速。
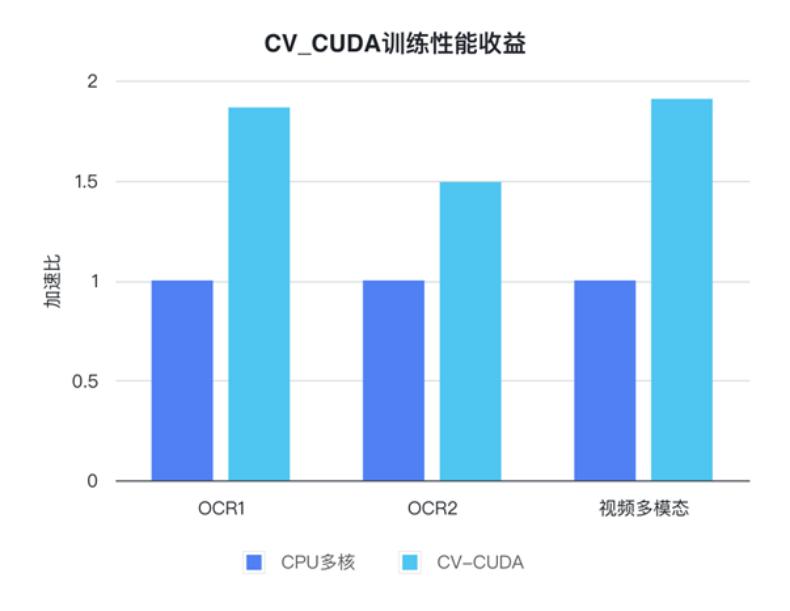
在字节跳动 OCR 与视频多模态任务上,通过使用CV-CUDA,整体训练速度能提升 1 到 2 倍(注意:是模型整体训练速度的提升)
在推理过程也一样,字节跳动机器学习团队表示,在一个搜索多模态任务中使用 CV-CUDA 后,整体的上线吞吐量相比于用 CPU 做预处理时有了 2 倍多的提升。值得注意的是,这里的 CPU基线结果本来就经过多核高度优化,并且该任务涉及到的预处理逻辑较简单,但使用 CV-CUDA 之后加速效果依然非常明显。
速度上足够高效以打破视觉任务中的预处理瓶颈,再加上使用也简单灵活,CV-CUDA 已经证明了在实际应用场景中能很大程度地提升模型推理与训练效果,所以要是读者们的视觉任务同样受限于预处理效率,那就试试最新开源的CV-CUDA吧。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《图像预处理库CV-CUDA开源了,打破预处理瓶颈,提升推理吞吐量20多倍》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

