- +1
FFmpeg AI 推理+图形渲染的可定制 GPU 管线
编者按:FFmpeg作为业界广泛使用的转码平台,提供了丰富高效的视频处理能力。LiveVideoStackCon2022上海站大会我们邀请到了英伟达GPU计算专家 王晓伟老师,结合具体项目实践为大家详细介绍如何在FFmpeg中开发一个包含AI推理+图形的完整GPU转码管线。
文/王晓伟
整理/LiveVideoStack
大家好,首先自我介绍一下,我是王晓伟,来自英伟达GPU计算专家团队。我们团队长期支持业界头部厂商在GPU上进行转码和计算的开发及优化,主要包括GPU的计算加速,涉及推理、计算和编解码。本次主要跟大家分享下如何在FFmpeg中定制一个在GPU上的包含AI推理和图形渲染的pipeline。
在正式分享之前,我们先来回顾下使用GPU转码的历史进程。
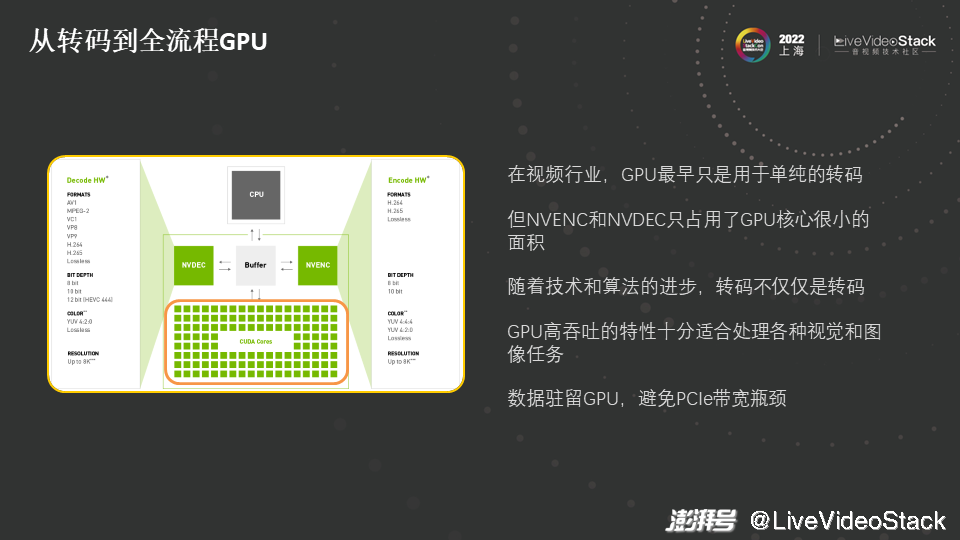
最初,在视频行业或互联网行业GPU只是用于单纯的转码,记得在五、六年前,一些业界的头部厂商购买了很多GPU来做转码。如图所示,NVENC和NVDEC是GPU的硬件,用于解码和编码的芯片,硬件编解码的好处有成本低、吞吐高和延迟低。但现在GPU越做越大,安培架构的GPU有几百平方毫米的核心,NVENC和NVDEC这两个硬件的编解码芯片只占用了GPU核心很小的部分。这时单独买一块价格昂贵的卡仅用于做转码很不划算。
另一方面,业务内容、技术和算法在变化,此时我们所熟知的转码不再是指转码这一个单一行为(也就是不只是把A格式转到B格式,或者把A的码流转到某些分发的格式),而是加入了很多的处理,比如推理、画质的提升或计算。
视频是由连续的图片组成的,对视频做计算就是对连续的图片做计算。如果图片的分辨率较高,如720p、1080p、4K和8K等,那么对算力的要求就会很高,而GPU作为高吞吐、高带宽、高算力的硬件,可以更为方便地处理视觉和图像任务。最近两年,大家越来越多地使用GPU来做转码和计算,这里就有一个经验或趋势,称之为全流程GPU,即数据驻留在GPU上,不会在CPU和GPU间来回地拷贝。PCIe的带宽和GPU显存的带宽有数量级的差异,即PCIe的带宽不高,来回地拷贝会造成额外的延迟甚至额外的吞吐上的损失,因此建议数据驻留GPU,避免来回地拷贝,使得所有的计算尽量在GPU上进行。

回顾完历史,接下来介绍我们本次分享内容的背景。
首先,我们注意到视频云渲染在数据中心中受到越来越多的关注。云渲染这个词听起来很宽泛,大家可以把它和业界的一些具体应用联系起来,比如现在很火的云特效,数字人和虚拟主播等等,这些都是很多厂商努力开拓的新领域。云渲染涉及的技术栈较为复杂,它包括AI推理、图形、图形渲染、计算和转码等,虽然GPU可以实现这些内容,但难点是如何将这些内容有机地结合起来。这时,一条业务线可能就会很复杂,比如做一个数字人或者虚拟主播的业务,既需要推理和渲染,又需要转码,同时对性能、延时有很高要求,因此我们需要考虑如何把这些技术合理地组织起来。
我们在和部分业界的头部客户交流时了解到,他们通常是会通过十几个部门间的合作来实现云渲染的流水线。其中包含做转码的部门、做渲染的部门、做AI算法的部门,以及做CV的部门等等,开会时就需要十几个部门同时参加会议,因此沟通的成本非常巨大。同时,他们也缺少参考实现,是在靠自己摸索实现,这个过程中就会遇到很多问题。
因此,我们想将之前的一些经验总结出来,跟大家分享一下我们所遇到过的“坑”,这样就可以为大家提供一个类似的参考实现。这个参考实现可能看起来非常简单,但它提供的是一个清晰的流程,然后再从简单到复杂,一步步地将其开发出来。即使这个参考实现无法支撑大家直接做出一个产品,但起码可以做一个demo出来,并且可以在内部进行测试和评估。
目前,这项工作已经开源,仓库地址如图中所示,名称为“FFmpeg-GPU-Demo”,这是一个针对GPU修改过的FFmpeg的实现,后期我们会继续迭代这个仓库,会有大的版本升级,大家可以关注下。

介绍完整体背景,接下来看一下我们对场景的假设。
因为要根据具体的场景来做流水线,假设要做的是虚拟主播、数字人,那么我们需要哪些组件呢?首先,我们需要面部的追踪和建模,因为要针对人脸进行渲染,但由于数字人不是真人,就要把人脸的表情和动作retarget过去;然后,还需要特效渲染、视频增强(比如超分、去噪等),需要用绿幕进行抠图、视频转码等等。每一个组件需要由不同的团队负责,每个团队有自己所属的专业领域,可能对其他方向的内容了解得并不多。
此外,大家所使用的底层的技术也不一样,例如转码团队希望继续使用FFmpeg,因为他们可能对FFmpeg更熟悉。而特效团队有自己的渲染器(自己写的OpenGL Shader或商用的UE、Unity),AI算法团队(可能不会C语言或C++)直接使用PyTorch中训练好的模型。以上这些都是需要考虑到的问题。

带着这些问题,我们来介绍一下本次分享的具体内容。首先,会跟大家介绍下我们的pipeline是如何设计的。之后会详细讲解为了做这个pipeline或设计,需要做哪些工作和步骤,有哪些需要注意的点。最后,会介绍我们现有的一些工作以及性能分析,探讨我们所看到的行业内部的发展趋势并对云渲染的未来进行展望。
01 FFmpeg推理+渲染管线

首先,介绍下我们的pipeline是如何设计的。

首先,我们要确定具体的目标场景,即要做什么。我们想找一个典型的,不太复杂和庞大的场景,因此我们这里选定的场景是人脸渲染。人脸渲染是数字人、虚拟主播的一个子集。
如图为大家展示下我们的pipeline用FFmpeg实际跑出来的效果,其中涉及两个关键点:由于要将口罩画在人脸上,首先要对视频中的人脸做实时的姿态估计,因此采用了深度学习的模型;然后要采用超分改善图像的性能,我们希望只在720P上做推理(这样可以减小对算力的需求),并将图像超分到2K,保证图像的质量。
这里要说明的是该项目并不是一个开箱即用的产品,我们并不追求漂亮的成品效果,只是希望借此项目向大家展示如何定制一个类似的管线,分享开发的经验。

如之前所说,我们希望遵守全GPU流程的准则,避免PCIe数据的拷贝,将计算和数据都留在GPU上,避免拷贝带来的开销。因此,我们可以确定两点:首先,要基于FFmpeg进行开发;其次,要使用GPU进行编解码,这样能保证延迟和吞吐。
为了实现刚刚给大家展示的效果,要使用两个深度学习的模型。首先要做Face Alignment,即对面部的姿态进行估计,将得到的结果在OpenGL里进行绘制。另一个深度学习模型是超分,超分的效果类似DLSS,后面会进行详细地介绍。

这是管线设计的第二部分,就是从垂直的角度来看它涉及到哪些栈。
首先,介绍一下为什么要用FFmpeg,原因是“无他,唯用的人多尔”,我们了解到的客户大多都使用FFmpeg,尤其在直播和短视频领域,大家很多都是基于FFmpeg进行转码。大家之所以都用FFmpeg,是因为FFmpeg比较“亲民”,比较简单,没有太多复杂的机制。但简单的同时也带来一些限制,这个后面会再进行说明。同时,这也说明了“技术之间没有好坏,只有合不合适”。
大家对FFmpeg了解得比较多,垂直来看若要做一条链路,底层是硬件,GPU做了“重活”。然后中间有一些软件,底层的软件有CUDA、OpenGL和NVIDIA的Codec SDK(硬件编解码),上层的软件有Pytorch、ONNX和TensorRT(推理),还有其它的一些未列出来的软件。
FFmpeg使用avfilter来处理解码后的帧,做全流程的GPU处理实际就是要实现若干FFmpeg GPU filter。我们要调用中间软件的能力在libav层做开发,最后在ffmpeg binary调用libav,比如使用ffmpeg的命令行直接调用做好的filter进行转码。理想情况,做两个filter就够了,TensorRT filter用于推理,OpenGL filter用于渲染,硬件编解码是现成的。
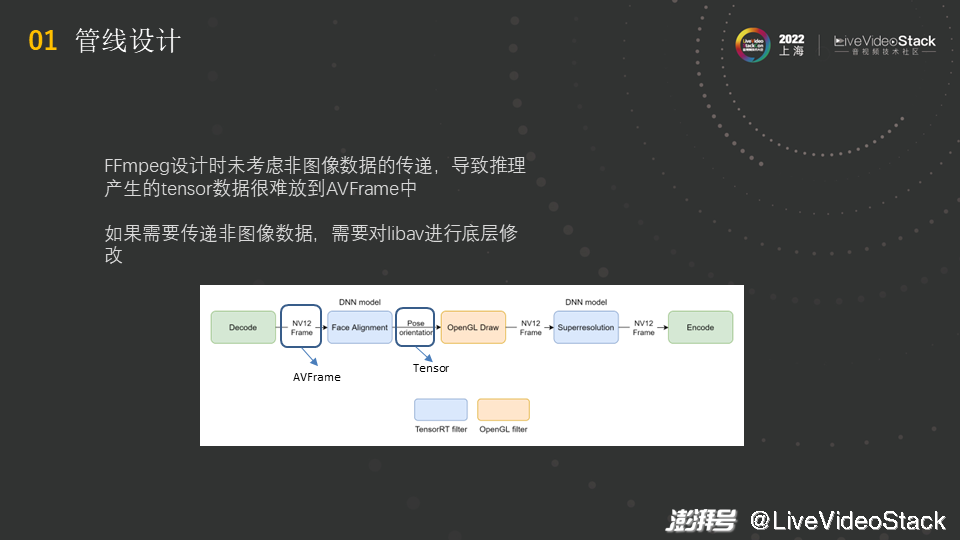
但实际上这样是不行的,为什么呢?Gstreamer的能力很强,全模块化的设计给它带来了非常灵活的优势,但问题是FFmpeg设计时只为视频设计,没有考虑过在各种element之间传递非图像数据。推理一般产生的数据是tensor数据,它可能是高维的,有不同的精度(int8, half, FP32)。FFmpeg 的filter间传送的是AVFrame,但很难将tensor数据放到AVFrame中,比如维度信息就很难装入其中。如果想要传递非图像数据,业界中有些选择直接对libav进行底层修改,添加一条新的data path,即在此之间可以传递任意格式的数据。但这个工作非常底层,很多业界大厂、头部客户不愿意做这个工作,因为即使不考虑开发的工程量,底层的修改涉及到整个FFmpeg,牵扯面太大,要做大量的测试保证线上的稳定性。并且在修改时,可能会出现在A处做了更改,结果B处发生了问题的现象,就如量子力学一样,某个地方的变化影响了其他地方的改变。因此,很多人并不愿意进行底层的修改。
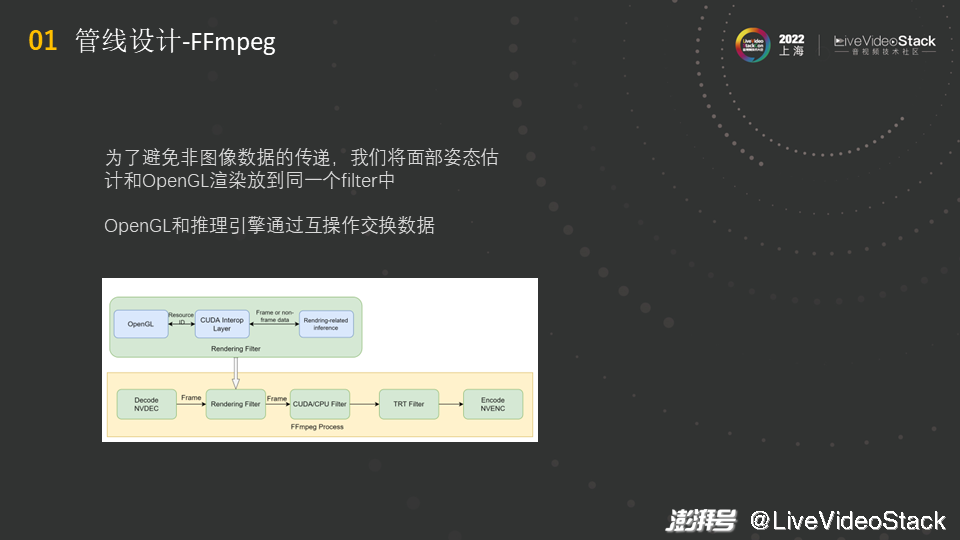
对此,我们想了一个简单点的方法。不传递非图像数据,在既有渲染又有推理的场景下,若渲染和推理是紧密结合的,就将这两者放到同一个filter中。在一个filter中的处理就比较方便了,推理出来的数据通过互操作直接传给OpenGL,不经过CPU而是直接在GPU上交换数据,然后在一个filter中完成操作后,OpenGL将所需绘画的内容画好并直接将内容传给后续的filter,这样输入和输出的都是图像数据,就不会有之前的问题。
但相对来说,这种情况下的渲染的filter就会比较复杂,如图中的结构所示,进入以后要先做渲染相关的推理,推理的结果要通过互操作传给OpenGL做渲染,然后再输出帧,再进行后面的操作,后面可以接其他的GPU的filter或者TRT的推理。
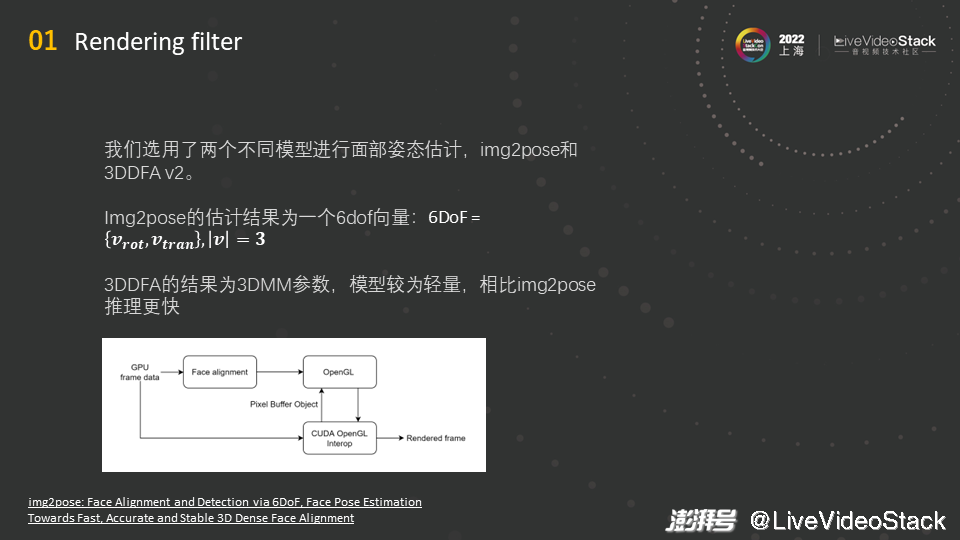
接下来具体介绍一下Rendering filter。我们选用了两个不同模型进行面部姿态估计,这两个模型不太一样,各自具有代表性。
两个模型分别是img2pose和3DDFA v2,这两个都是开源的项目,开源的仓库地址已经给出,大家有兴趣的话可以去了解一下。之前看到的演示视频里的内容是用img2pose生成的,它的模型是Faster R-CNN类型的模型,这适合大规模的人脸检测,若会场里有50个人,这个模型检测一个人的时间和检测50个人的时间是没有区别的,后面会给大家展示具体的性能数据。
但由于img2pose模型是Faster R-CNN类型的模型,对算力的要求就很高。3DDFA v2是一个轻量模型,它的结果为3DMM参数,根据这个参数可以重建出人脸的模型,这个模型是一个Mesh,由于模型较为轻量,因此推理更快。但该模型不适合于大规模的人脸检测,最适用的场景是只有一两张人脸,当人数过多时,性能就会线性下降。渲染filter的结构如图所示,将经过Face alignment处理后的数据传给OpenGL,然后渲染输出。

除了渲染模型,还有一个超分模型,这个模型是用TensorRT filter去实现的。TensorRT filter的实现没有太多麻烦的地方,可直接根据TensorRT的例子开发一个filter,然后将其包起来放进去就可以了。其中有一点要注意的是,TensorRT对数据格式有要求,它只支持NCHW数据,不支持NHWC数据,映射到视频图片方面就是,它只支持planar RGB,不支持packed RGB。但在FFmpeg中只能看到packed RGB,排序方式是“RGB RGB RGB...”,而不是“RRR...GGG...BBB...”,因此FFmpeg中没有这种格式,而且FFmpeg也不支持float32,即没有planar RGB float32格式。
针对上述情况,我们在FFmpeg中添加了一种新的pixel format,称为rgbpf32(planar RGB float32),并且实现了一个新的forma_cuda filter,就是用cuda写了一个kernel,来支持在GPU上nv12和rgbpf32之间的转换。在FFmpeg中调用上述内容的命令如图中所示,前面部分是为了保证能使用GPU的编解码并使得数据驻留在GPU上,然后是输入文件的命令,接着是使用GPU上scale filter的命令,使用format_cuda转成rgbpf32的命令,使用TensorRT模型的命令,再是转回nv12的命令,最后是nvenc编码输出的命令。图中展示了上述命令的流程。
02 定制FFmpeg GPU Filter

介绍完整个pipeline的设计后,接下来讲解一些具体的技术,即如何在FFmpeg中定制一个GPU Filter。这方面的资料其实比较少,文档中可以看到如何去写一个filter,但大部分是讲解怎么做CPU上的filter,这与GPU上的filter不太一样,即与涉及异构硬件加速的filter不太一样。对此,我们总结了一些经验。
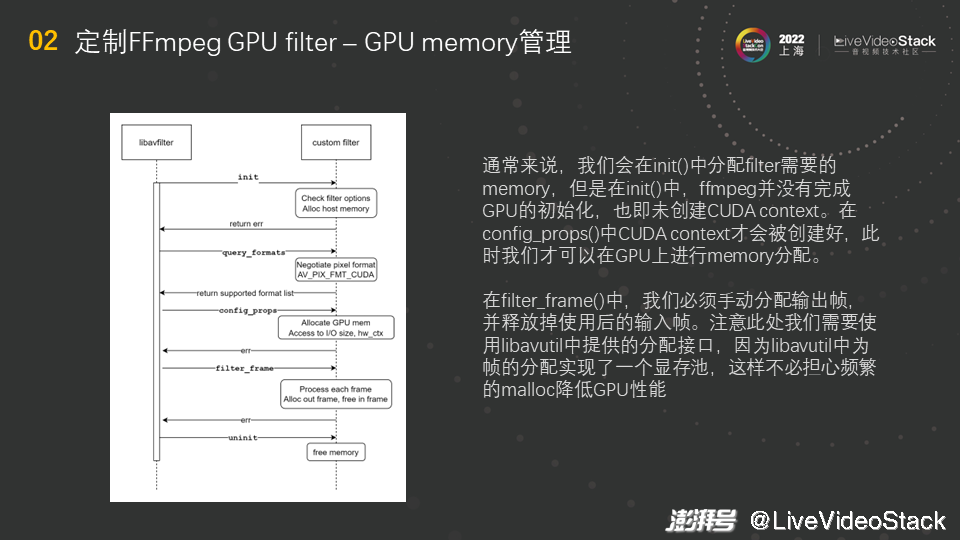
首先是GPU的显存管理。FFmpeg中的filter大概可分为几步,如图中所示(这里只展示简单的路径,还有其他的更高级复杂的路径),先是init,然后是query_formats(协商格式),接着是初始化,中间进行一些信息的配置,比如根据输入输出大小分配memory,然后是filter_frame,这是filter逻辑实际发生的地方,每来一帧就会调用filter_frame来处理图片,并实现输入输出,最后释放资源。
通常来说,做CPU开发时,会在init()中分配filter需要的memory。但是在init()中,FFmpeg并没有完成GPU的初始化,只有当创建CUDA context后才能完成FFmpeg的初始化,因为任何一个GPU程序都需要一个CUDA context。创建过程可能是透明的或者显式的,即不一定要手动创建,比如使用CUDA Runtime API时,我们不需要管CUDA context,因为Runtime会自动维护CUDA context。那CUDA context到底是什么呢?可以把它和CPU上进程的上下文做类比,GPU显存的地址空间和设备等信息都保存在CUDA context中。
总之,完成GPU的初始化就是要创建CUDA context。那么在init()中,由于没有创建CUDA context,就没有完成GPU的初始化,因此不能对GPU进行操作,不能分配和拷贝显存,且发起API调用时会报错。那CUDA context什么时候才能被创建呢?在协商的第二步,即config_props()中CUDA context会被创建,然后就可进行显存的分配、拷贝,而且在config_props()中可以知道输入输出的大小,因此可以分配一个缓存buffer,其与帧的大小有关。
在filter_frame()中,我们必须手动分配输出帧,然后释放当前filter中的输入帧,即filter_frame()既要负责释放输入,又要负责分配输出。这意味着,每来一帧就要分配一次memory,free一次memory。在GPU上频繁地malloc和free显存是非常昂贵的,因为每在GPU上做一次memory分配,就要做一次GPU全局的同步,这会带来性能上的损失。大家要注意的是,此处需要使用libavutil中提供的分配接口(大家可以去我们的仓库代码里看具体的接口,里面有具体的示例展示如何对其进行使用),因为libavutil中为帧的分配实现了一个显存池。FFmpeg中有buffer pool,GPU中也实现了buffer pool,在初始化GPU时,会预先分配一大块显存,之后再需要显存时直接从显存池里获取,而不是去调用malloc。直接从显存池里获取显存是一个简单的操作,复杂度为O(1),这样就不必担心频繁的malloc降低GPU性能。
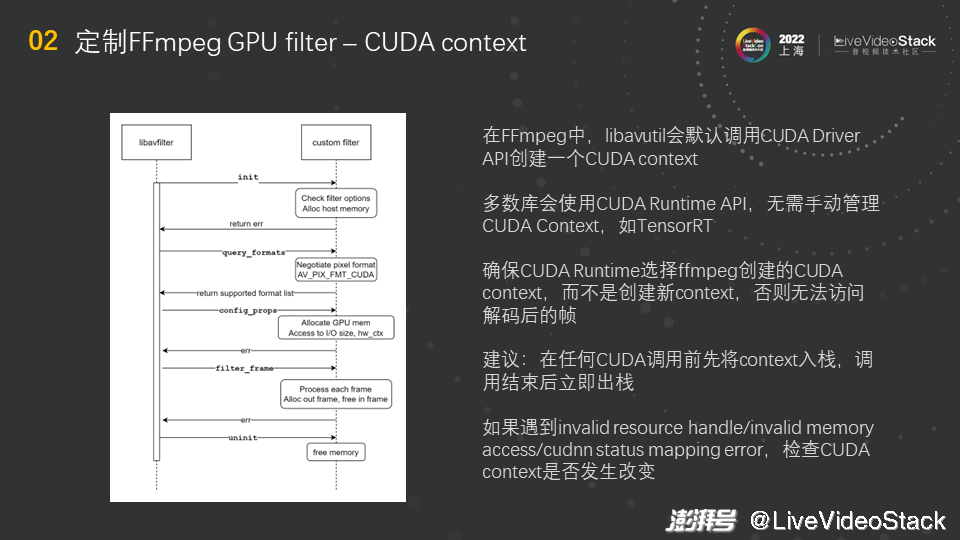
大家可能对刚才提到的CUDA context还有疑问,我再给大家解释一下。之前提到,不是所有的情况下都需要手动管理CUDA context,那怎么来区分这个情况呢?是看使用的哪种CUDA API。若使用的是CUDA Driver API,这个API更底层,若使用它则需要手动管理CUDA context;若使用的是CUDA Runtime API,这个API更高层,若使用它则不需要手动管理CUDA context。手动管理CUDA context不是一件特别有意义的事情,所以我们一般建议大家使用CUDA Runtime API,让其管理CUDA context,这既不会出错也不会影响性能。
目前,多数库会使用CUDA Runtime API,比如TensorRT。但FFmpeg使用的是Driver API,这是无法改变的,我们只能遵守其规则。我们建议大家在开发filter或自己写filter代码时,使用Runtime API,因为Runtime API和Driver API是可以共存的。Runtime API使用起来更方便,比如做CUDA memory copy时,Driver API更“啰嗦”一些,Runtime API相对更简洁。因此我们推荐使用Runtime API,但使用其的前提是管理好CUDA context。也就是说,FFmpeg创建一个CUDA context,Runtime启动时会识别当前线程是否有可用的CUDA context,若有则直接使用当前的CUDA context,若没有则先创建一个CUDA context。因此需要注意的是,一定要将FFmpeg创建的CUDA context设置为当前线程可用的context,这样CUDA Runtime不会创建新的context而是直接使用FFmpeg创建的CUDA context。设置的过程就是一个入栈的过程,接口叫做cuCtxPushCurrent,可将当前的CUDA context给push到线程中,即入栈,然后就可以使用了。
这里给大家一个建议,在任何CUDA调用前先将CUDA context入栈,调用结束后立即出栈,这样就是一个干净的CUDA context管理,不容易发生错误。若CUDA context出错,就不能访问memory,因为使用FFmpeg的硬件解码器得到的帧将存在GPU的显存里,这个显存是在FFmpeg分配的CUDA context下获取的,而CUDA有一个规定,即在B context下不能访问在A context下分配的memory,这时候强行访问就会报错,因此若Runtime创建了一个CUDA context,在该context下就不能再访问解码得到的帧。因此一定要管理好CUDA context。
另外,如果大家遇到图中展示的错误,比如invalid resource handle、invalid memory access和cudnn status mapping error等,可以检查CUDA context是否发生改变。CUDA有接口可以打印当前的CUDA context内容,大家可以获取该内容观察filter运行过程中CUDA context是否发生改变,若改变则可能出现问题。
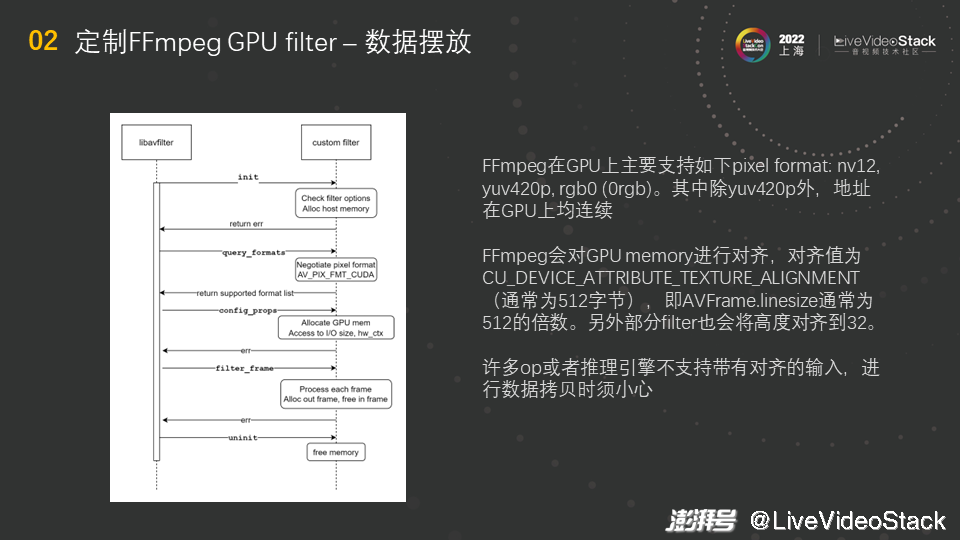
最后,给大家介绍一下数据摆放。FFmpeg在GPU上支持的pixel format不太多,基本上是nv12、yuv420p和rgb0(0rgb)三种。其中除yuv420p外,nv12和rgb0的地址在GPU上均连续,此处的连续指的是不同的channel,比如nv12的Y通道和UV通道是连续的,是一整个显存,这个显存被切分使用而已。
另一个很重要的点是,FFmpeg会对GPU memory进行对齐,对齐值为一个设备的属性,名称是CU_DEVICE_ATTRIBUTE_TEXTURE_ALIGNMENT,可以通过CUDA的接口查询该值。这个值通常为512字节,即AVFrame.linesize通常为512的倍数,但实际上帧大小可能不是512的倍数,这时会做padding,将其补齐到512的倍数。另外部分filter也会将高度对齐到32,但是实际上高度可能不是32的倍数。此时许多op或者推理引擎不支持带有padding/对齐的输入,比如TensorRT、PyTorch。如果将带有padding的数据(帧的右边和下边带有黑边)输入进去做推理,得到的推理结果可能有问题,比如可能由于黑边导致精度有问题。因此大家处理时需要小心,若推理引擎不支持对齐的输入,要裁切掉黑边,即做一次数据拷贝。
03 CUDA OpenGL互操作

接下来介绍CUDA 和OpenGL的互操作。

首先,介绍什么是CUDA和OpenGL的互操作。刚才提到,我们既要推理又要渲染,渲染取决于推理的结果,因此我们需要用OpenGL在GPU解码的图片帧上进行绘制,那么就需要OpenGL可以访问到CUDA memory。虽然从硬件上来看,OpenGL和CUDA memory都是用的GPU的显存,但从软件上来讲,这二者是不相通的,存在一定的隔阂,具体原因如下:CUDA使用和C一样的malloc/free管理机制,它使用指针来管理显存,但OpenGL是一个基于状态的API,使用和C语言不同的机制,它里面的内容和数据存在buffer object当中,buffer object的类型是有限的,这些类型是预定义好的,需要使用时就分配给某一种buffer object,而不是采用指针的方式,不能对其进行拷贝或malloc操作,故我们无法将一块CUDA memory直接拷贝到OpenGL的buffer object中。
面对上述情况,我们可以做的是CUDA和OpenGL的互操作,可以将OpenGL的buffer object映射到CUDA地址空间并得到对应的指针,这个指针指向buffer object实际使用的物理显存,故得到这个指针后二者就处于同一地址空间,此时就可以方便地实现拷贝。互操作有两种实现路径,一种是直接映射texture,即直接将纹理映射过去变成CUDA Array,Array与指针不同,使用起来不是很直观。因此我们推荐另一种路径,即使用Pixel Buffer Object将图片进行中转,中转后得到的是指针,这样使用起来就较为直观。
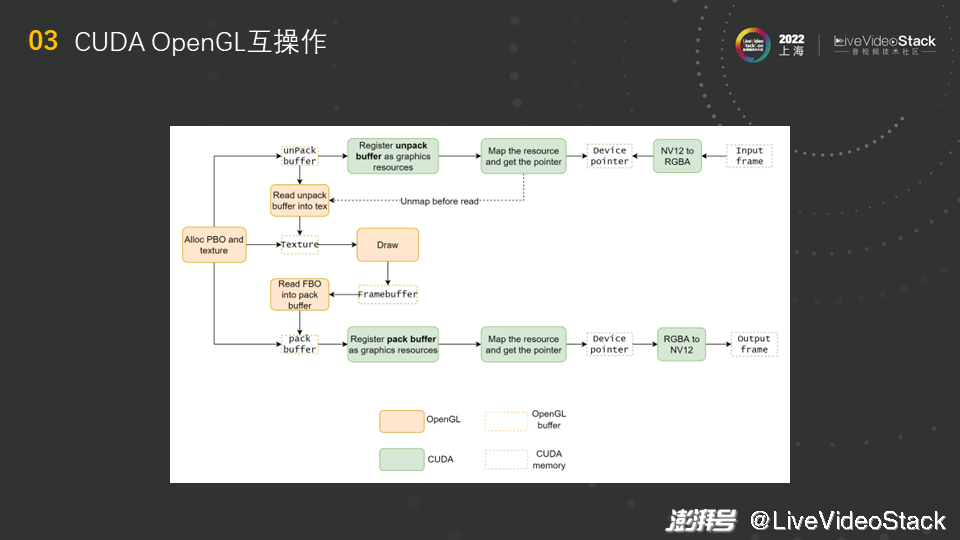
给大家展示一下具体的流程。CUDA和OpenGL的互操作是从分配OpenGL的buffer开始的,图中与OpenGL相关的内容用橙色方框表示,与CUDA相关的内容用绿色方框表示。如图所示,首先要分配一个PBO(Pixel Buffer Object),共有两种PBO,一个是pack另一个是unpack,向OpenGL里传输内容时需要unpack,从OpenGL里往外传输内容时需要pack。分配好后,在CUDA里注册unpack buffer,得到graphics resources数据结构,对该数据结构进行map即可得到指针,然后可在我们写的CUDA kernel里直接访问内容,并对NV12解码得到的帧做一次RGBA转换,因为OpenGL里不支持yuv数据格式,将转换后的结果存在得到的指针里。
然后,对之前得到的resource进行unmap操作,保证CUDA里的操作都已结束,若不进行unmap操作而直接执行OpenGL的操作,就会出现问题。执行完unmap操作后,经过RGBA转换的数据已存在于unpack buffer里,使用相应的接口将unpack buffer里的内容读到Texture中,就可在Texture上根据之前推理的结果进行相应的绘制,比如之前展示的绘制的口罩。画完后的结果会存于Framebuffer中,然后将Framebuffer的内容读到CPU或者pack buffer(另外一种PBO)中,pack buffer在GPU上。若将Framebuffer的内容读到CPU中会有一个问题,比如我们之前有个客户不知道互操作,他将内容读到CPU进行中转,然后将内容从CPU拷贝到CUDA的地址空间,这样的来回中转会导致延迟的增长和吞吐的下降。相反地,将内容读到PBO中,在GPU上做显存的拷贝,这时的带宽很高且速度很快。得到pack buffer后,对其进行注册、映射,得到指针,再用GPU上的kernel将其转为NV12,最后得到输出帧。

最后总结一下流程。首先在OpenGL里进行分配,然后映射、写入数据、创建texture,接着绘制,读出framebuffer里的内容并将其映射到CUDA地址空间中,最后将地址中的内容写到输出帧中。
04 FFmpeg OpenCV GPU filter

目前已经基本介绍完我们的pipeline涉及的点,接下来介绍一下我们其他的工作。

其实,GPU在FFmpeg上的生态不是很好,FFmpeg提供的GPU filter数目有限,目前仅有5个GPU filter,其中有两个filter的功能一样,只不过是实现方式不同,这5个filter的具体功能分别是:scale_npp和scale_cuda用于缩放,yadif_cuda用于解上下场,overlay_cuda用于打水印,thumbnail_cuda用于缩略图。不少客户会因为需要的操作没有GPU实现而转用CPU filter。转用CPU filter会有一个问题,目前GPU的密度越来越高,单机四卡和单机八卡都很常见,单机八卡里可能有两个CPU,两个CPU大概共有八十个核,那么它既要调度八个GPU,又要运行filter,那么吞吐可能就跟不上,并且因为filter都由软件实现,这会带来延迟的增加。
DevTech里有一个CV-CUDA的项目,里面提供了GPU加速后的常见的图像处理op,包括OpenCV、DALI和torchvision,这使得性能得到了保障。同时,项目还支持batch。在制作这个展示的PPT时,项目可提供46个op,而现在项目可支持五十多个op。项目即将在GitHub开源(估计在本月就会上线)。图中右半部分列出了部分op,其中有较常见的op,比如cvtColor、resize。resize的功能和scale的功能是相同的,在深度学习训练中会用到OpenCV里的resize,但在推理时若使用其他缩放的filter,输出的数据可能不是比特/像素对齐的,那么和训练时相比,模型在线上运行时的精度是有波动的。而我们会做到像素对齐的结果,保证线上的精度。

我们计划逐步将合适的OpenCV op开发为FFmpeg GPU filter,丰富GPU在FFmpeg上的生态。目前,我们正在开发vf_format_gpu。众所周知,format filter可以在常见的pixel format间来回转换,操作非常方便,所以我们的目标是基于cvtColor支持在GPU上进行pix_fmt转换。同时,FFmpeg里有个组件叫libswscale,这个组件非常强大,可以实现各种格式间的转换,还可以做图片的缩放和数据格式的转换,甚至在FFmpeg的两个filter大小不一致或pixel format不一致的情况下,可以自动实现缩放。因此,我们在考虑是否有可能参照libswscale实现libgpuscale,这样就可以在GPU上方便地使用filter,还可支持各种格式的转变,帮助解决问题。
05 性能分析

接下来介绍一下pipeline的性能。

最关键的性能是异步性,尤其对于异构计算、硬件加速来说,异步性是最重要的。异步性保证GPU可以一直处于忙碌的状态,不会有空闲时刻,让GPU得到了充分的利用。在我们的pipeline中,有异步执行的部分,如下所示。首先是CUDA kernel发起和执行,其只有异步而没有同步的方式,但可以通过调用API进行手动同步。然后是TRT推理,其本质是CUDA kernel的发起和执行,所以它也是异步的,当然它也有同步的接口,可在CUDA kernel执行完后进行手动同步。除了一些必须要同步的命令以外,OpenGL的渲染命令在GPU上基本也是异步的。GPU视频的编码和解码也基本上是异步的。但同时,pipeline中也有同步的部分,即OpenGL的互操作,在映射或者Unmap OpenGL graphics resources时,就会同步一次。这与OpenGL的机制有关,将resource map出来后,要保证在CUDA操作完成后,再unmap回去,所以要进行同步,若不同步,直接将其unmap回去,此时若CUDA操作只完成了一半,那么传回去的图片只有一半。总之,每处理一帧图像都存在一次同步操作。
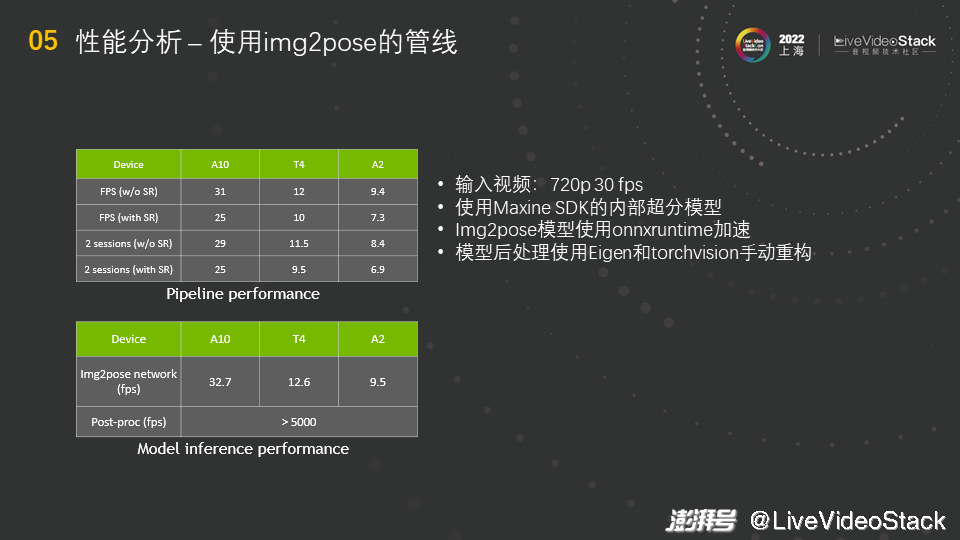
接着看一下具体的性能数据,这个性能数据是从常见的推理使用的数据中心的卡上测得的。输入视频是720p 30帧,使用Maxine SDK的内部超分模型,使用TRT运行。Img2pose模型使用onnxruntime加速,由于Img2pose模型的后处理涉及矩阵的乘和一些小矩阵(4×4或8×8)的乘,所以使用了Eigen进行重构,而对于一些后处理的op,使用了C++的torchvision进行了手动重构。
我们先来分析图中下方表格的性能数据,这显示了Img2pose模型本身的性能。将Img2pose模型分为两个部分来看,首先是网络的性能,在A10上大概是32fps,差不多是一路实时的效果;但重构完后的后处理可以跑到5000fps以上,所以后处理占用的算力或者时间是很少的,主要的问题还是在网络上。然后来看图中上方的表格,即整体的pipeline的性能数据。将pipeline放到FFmpeg上运行,若不跑超分模型,在A10上大概是31fps,和之前的数据很相似,说明主要的性能瓶颈就在Img2pose的网络上。若跑超分模型,由于超分模型速度很快,所以性能下降不算多,只下降了6fps,说明超分不是很大的负担。然后我们尝试跑两路流水线,观察是否会对GPU有进一步的性能压榨,结果是否定的,性能基本没有改变,A10和T4的前后数据基本相同,说明一路流水线已经比较充分地使用了资源。
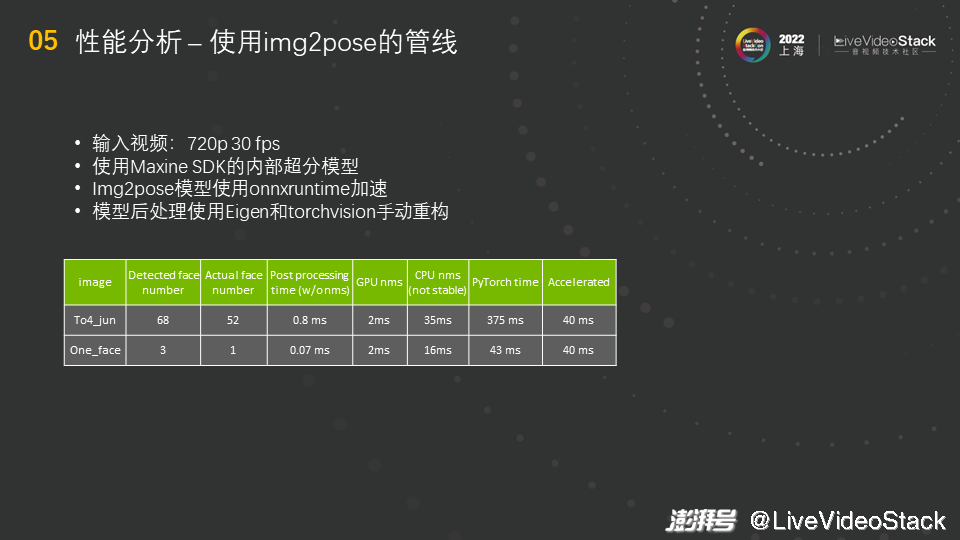
既然Img2pose的网络是最大的性能瓶颈,那我们来对其进行进一步的分析。测试的环境与之前相同,我们选用了两张照片,其中一张是大合影,里面有52张人脸,另一张是自拍,里面只有一张人脸。做完NMS后得到的值如表格中所示,后处理不包括NMS,可以看到后处理是很快的,基本可以被忽略。NMS就稍微慢一些,最初,原作者在PyTorch的代码里使用的是CPU上的NMS,但这个数据测出来不稳定,表格中展示的是最好情况的数据,有时候数据可能会增长到五十多或六十多,并且在人脸较多的情况下,还会变得更慢,这个问题就很严重。在GPU上的NMS的时间就很稳定,都为2ms。另外,使用原作者的PyTorch的代码跑52张人脸需要三百多毫秒,与跑单张人脸所需时间相比,性能慢了很多,但经过我们的一系列加速后,二者最后都稳定在了40ms。我们也测试了其他照片,无论照片中有多少张人脸,时间基本都为40ms,这也符合我们对算法、模型的预期。
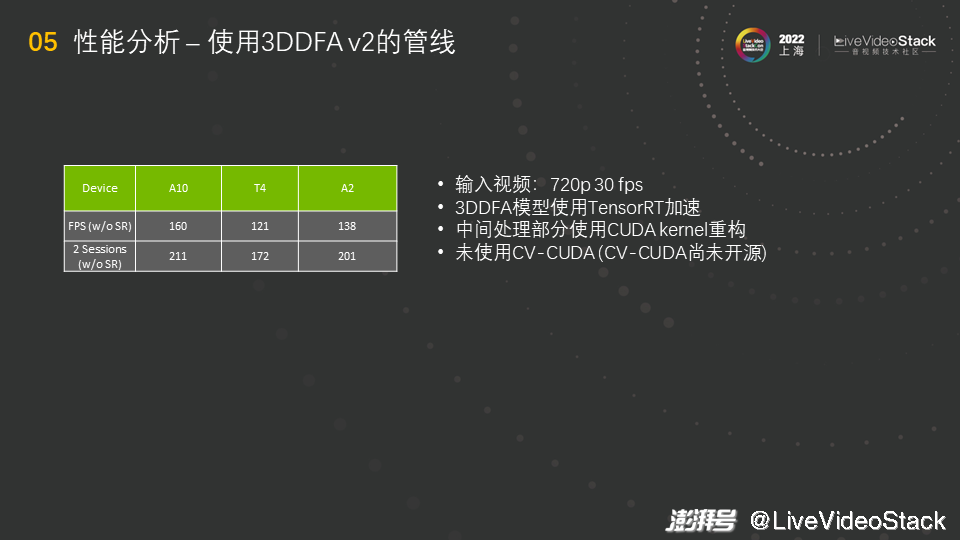
另外一个模型是3DDFA,这个模型比较简单,对其的分析也比较简单。测试的环境与之前大致相同,不一样的是3DDFA模型使用TensorRT加速,TensorRT直接就能跑onnx。中间处理部分(使用的是python代码)使用CUDA kernel重构,使其能跑在GPU上。另外,里面还有OpenCV的操作,OpenCV的操作是在CPU上的,但我们展示的是没有使用CV-CUDA下的性能,这是因为目前CV-CUDA尚未开源,在GitHub上开源的3DDFA管线是未使用CV-CUDA的版本,所以OpenCV的操作并没有经过GPU加速,还是CPU的版本。
观察图中表格,当不跑超分模型时,性能比img2pose快很多,A10上能跑到160。但有个奇怪的地方是,A2理论上只有T4的一半,但结果却是A2跑得比T4还快。这其实与CPU有关,如刚才所说,很多OpenCV的操作在CPU上,A2这个服务器的CPU比较好,所以它跑得比较快,这也说明这个模型目前的瓶颈完全不在GPU上,必须赶快把CPU上的操作移植出去,才能更充分地利用GPU。同时也可以看到,跑两路会有一个更好的效果,这也说明此时并没有把GPU用完。
06 未来展望

现在已经介绍完设计和性能分析的内容,最后跟大家分享一下我们现在正在做的工作和未来展望。

我们目前做的一个工作叫做自由流水线,它跳出了FFmpeg框架。因为我们意识到FFmpeg框架有很多的限制,业界的一些客户也对此很不满,所以他们会自己写转码的框架或进程,这样就不需要遵循FFmpeg的条条框框,调用推理、cv的op就会很方便。FFmpeg专业且强大,但在云渲染场景存在限制,比如有些客户跟我们提到,他们的视频来源很单一,可以完全控制视频格式的数量(比如只有264和265),且分辨率和码率也是有限的组合。那么,由于无需应对很多转码格式,就不需要非常复杂的处理转码的能力,可以直接调用FFmpeg的API,而不是使用FFmpeg的binary,故即使客户自己写的转码的APP不是非常专业,但也能满足需求。
另外,FFmpeg还有其他的限制。当前通过启用多个FFmpeg进程来跑多路,即跑一路转码就启用一个FFmpeg进程,这样若某一路转码失败,其他的转码还能继续跑,彼此间不会相互影响,但这在GPU上会造成限制,具体原因如下:CUDA Context是按进程计算的,只有打开MPS时,多个进程才能共享一个CUDA Context,若不打开MPS,那每个进程会有一个自己的CUDA Context,一个系统内就会有多个CUDA Context共存,若多个CUDA Context都指向同一个GPU,多个CUDA Context只能对GPU时分复用(这种情况和一个单核心单物理线程的CPU一样,多线程只能时分复用,每个线程都分别跑一个时间片),假设我要跑60路转码、推理,过程就是第一路上去跑一会儿再下来,然后第二路上去跑一会儿再下来,依此类推,虽然单纯的转码或硬件转码器不会受到CUDA Context的限制,但计算和渲染会受到影响,因为计算“来回跑”的方式没有办法实现真正的任务级并行的效果,而是在时分复用,这是串行而不是并行。
此外,虽然大家觉得FFmpeg简单一些,但FFmpeg GPU filter开发流程比较复杂,这从之前的介绍内容就可以看出,我们实际在做的时候也踩了不少“坑”,关键是文档少信息少,遇到问题时只能自己调试、摸索。
综上所述,我们想做自由流水线,是想将我们团队这些年在编解码、图像处理、AI推理领域积累的内容整合成一个框架并对外开源(这个就是我之前提到的要做的大的版本更新),这个框架是一个op的合集和不同场景下的sample合集,大家可以根据这些op快速搭建出进程或程序。此外,我们也会提供python的binding,大家可以直接在python里调用框架来快速做一个流水线、demo。具体地,这个框架包含视频/图片编解码,常见cv算子,以及经典场景的示例。

我们已经使用新的框架加速了3DDFA v2模型,整体的感受就是其更加灵活、限制更少,这是因为无需封装进libavfilter。其次,打batch更方便,在FFmpeg中filter打batch非常麻烦,需要自己攒帧,比如要打成batch等于4,就需要来一帧攒一帧,直到攒够四帧才能进行一次推理或渲染,因此在FFmpeg中打batch是不够方便的,但在自己写的程序里可以随便拼接数据,所以更方便。然后,我们使用了CV-CUDA做加速,在A10上单路720p视频吞吐可达220fps,之前单路只可达160fps,性能得到了很大的提升。

刚才提到了场景的sample,我们现在还在做GPU的HEIF/HEIC图片编解码。HEIF格式是一个图片的容器,将图片或图片序列使用H.265(HEVC)编码,并将其装入HEIF容器。H.265的压缩率优于JPEG,而且其可做图片序列,可做动图,支持无损。由于是硬件编码,故其吞吐高,在图灵上实测编码1080p静态HEIF图像吞吐可达400fps(包括了容器打包的时间)。另外,由于是单独的硬件加速,故不占用CUDA core,减少了图片编码对推理或渲染的影响。
我们还做了视频抽帧。在审核等其他场景下无法也无需做到对视频逐帧推理,只需根据某种固定的时间间隔抽取视频中的某些帧,然后只处理这些有代表性的帧即可。间隔可以是时间间隔也可以是帧数间隔,比如一秒钟抽取两帧或者隔三帧抽取一帧。此外,可将抽出的帧编码为HEIF/JPEG落盘。

最后和大家谈一下未来的展望,跟大家探讨一下我们看到的东西。未来AI+Graphics的场景会十分多样且定制化,我们今天介绍的开发内容大部分都是定制化的,尤其是渲染的filter,需要根据实际内容思考如何做软件。之前提到,基于FFmpeg很难满足所有场景,所以我们在探索新的形式。
另外,GPU的利用存在门槛,软件不够丰富,我们希望进一步提供更加丰富的工具和软件生态,让大家在各种层次上更加便捷地利用GPU。
同时,我们还遇到了一些问题,比如数字人的数字资产在商业的引擎里,渲染也全在UE里完成,但UE不是库,所以不能直接被调用,UE执行分发时,其打包好的内容是独立的可执行文件,那么推理如何和打包好的渲染的程序交互呢?一般是通过跨进程、跨节点通信完成的,但实现起来会存在一些问题,并且有些客户自研的引擎针对的是渲染场景,没有图形接口,与我们之前探讨的内容不一样,针对这些问题我们正在探索解决。
此外,未来ARM在数据中心的占比会越来越高,因为ARM会提供更高的计算性价比,若想做高质量的渲染或编码,那么CPU软件编码要比硬件编码好,各个厂家都有非常厉害的CPU软件编码的实现,所以在对渲染和编码的质量要求极高的场景下,我们考虑实现GPU计算/渲染与CPU软件编码的组合。
最后,现在的模型越做越大,芯片之间需要互相通信,互相传输数据。有些客户希望渲染和计算部署到不同的节点,我们之前的形式就满足不了这样的要求,因为我们将计算和渲染放在了同一个filter,难以实现跨节点的要求。客户期望的这种方式的好处是,管理、调度方便,这对运维是有益的,但对技术实现有更高的要求,需要更灵活的部署和伸缩能力。

未来,我们会持续开发项目,添加更多的目标场景和功能,继续开发生态,欢迎大家积极参与讨论和建设!
以上就是本次分享的所有内容,谢谢大家!
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

