- +1
新一代视频编码标准VVC的芯片设计思考

编者按: VVC是新一代刚发布的视频编码标准,其中集成了当前最先进的视频压缩技术,相比上一代标准HEVC,可以提升将近50%的视频压缩率。但同时,VVC也带来了更复杂的预测方式、块划分等,其编码计算量暴增10倍以上。LiveVideoStackCon 2022 上海站大会邀请到了复旦大学微电子学院的范益波老师和和大家一同探讨了针对新一代视频编码标准VVC的芯片设计和思考。
文/范益波
整理/LiveVideoStack

大家好,本次我分享的主题是新一代视频编码标准VVC的芯片设计思考。

内容主要分为六个部分:VVC标准简介;Cmodel-硬件架构设计的算法模型;预测器模块(帧内预测和帧间预测);重建环路模块(RDO、变换量化);输出模块(ILF滤波、熵编码);总结与展望。
1、VVC标准简介
1.1标准发展历程
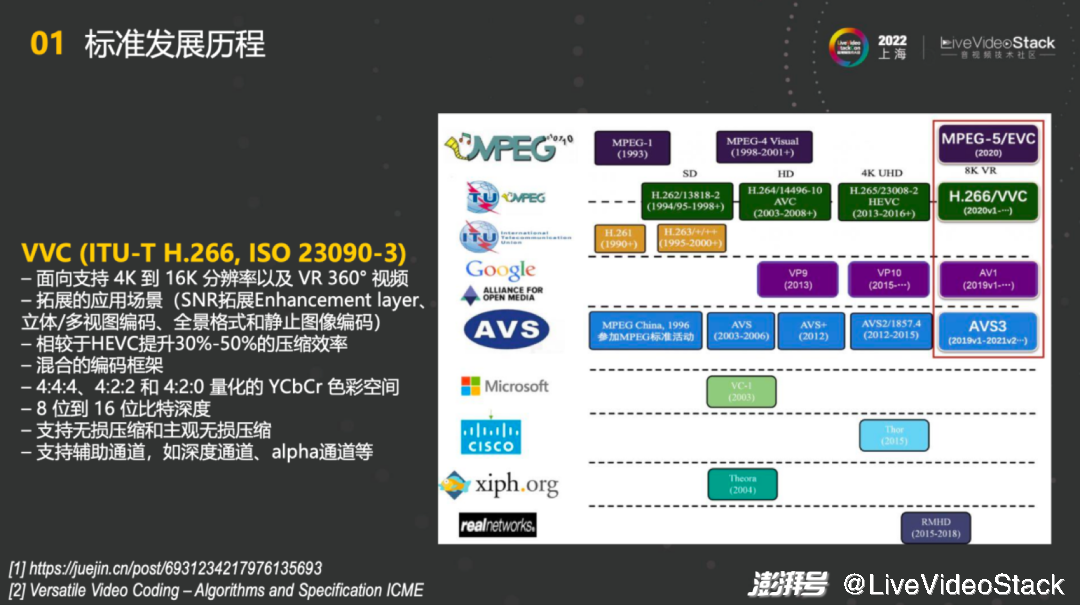
首先简单介绍下VVC标准。VVC是视频领域最新一代的标准,由两大国际组织ITU和ISO共同打造的标准。我国许多知名厂商也有很多专利,也是下一代视频应用非常重要的标准,在高分辨率以及VR领域能够发挥很大的作用。比如说能够面向支持4K到16K的分辨率以及VR 360°视频,并且有很多拓展的应用场景,包括SNR拓展Enhancement layer、立体/多视图编码、全景格式和静止图像编码。整体效率相较于HEVC提升了30-50%的压缩效率,也仍然采用了混合的编码框架。此外视频也能支持4:4:4、4:2:2和4:2:0视频格式,YCbCr色彩空间和8位到16位比特深度。同时也支持无损压缩和主观无损压缩,支持辅助通道,如深度通道、alpha通道等。
1.2VVC标准引入的新特性
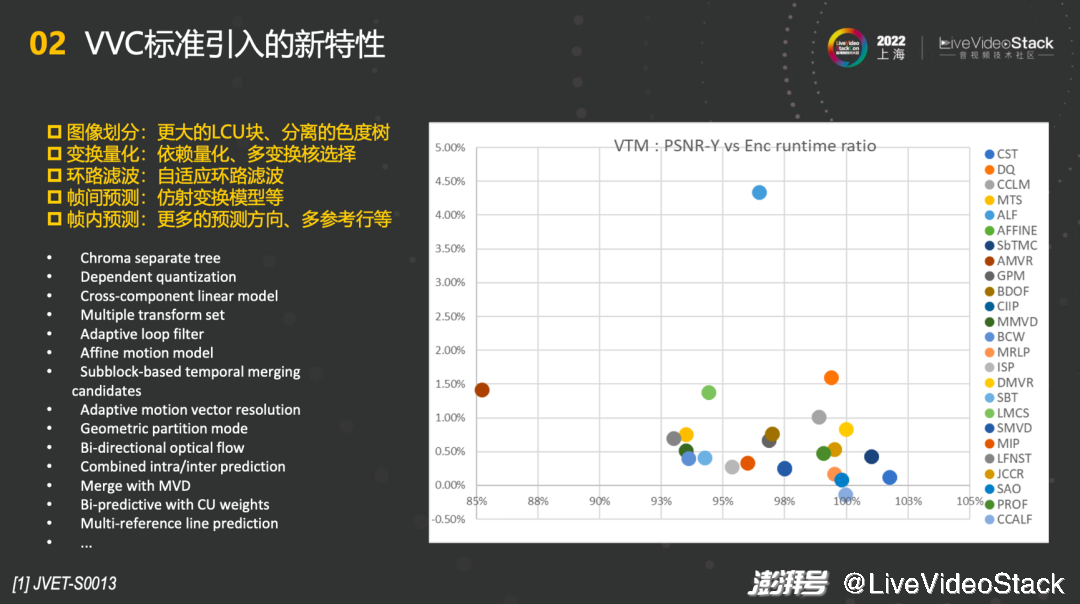
右边这张表列出了VVC标准引入的一些新特性以及每一个特性所能取得的收益。比如最高的色度分离树能够达到接近4.50%的收益,其余的比如DQ也能达到1.50%的收益,大部分的编码工具收益在1%以下。如果将这些新特性分类的话,能够分成图像划分、变换量化、环路滤波、帧间预测、帧内预测。图像划分有更大的LCU块、分离的色度树;变换量化有依赖量化、多变换核选择;环路滤波能支持自适应环路滤波;帧间预测上增加了仿射变换模型,这也是第一次被采用;在帧内预测中有更多的预测方向、多参考行等。
2、C-Model硬件架构设计的算法模型
一般做硬件时会涉及到C-Model,接下来简单介绍下C-Model。
2.1什么是C-Model?
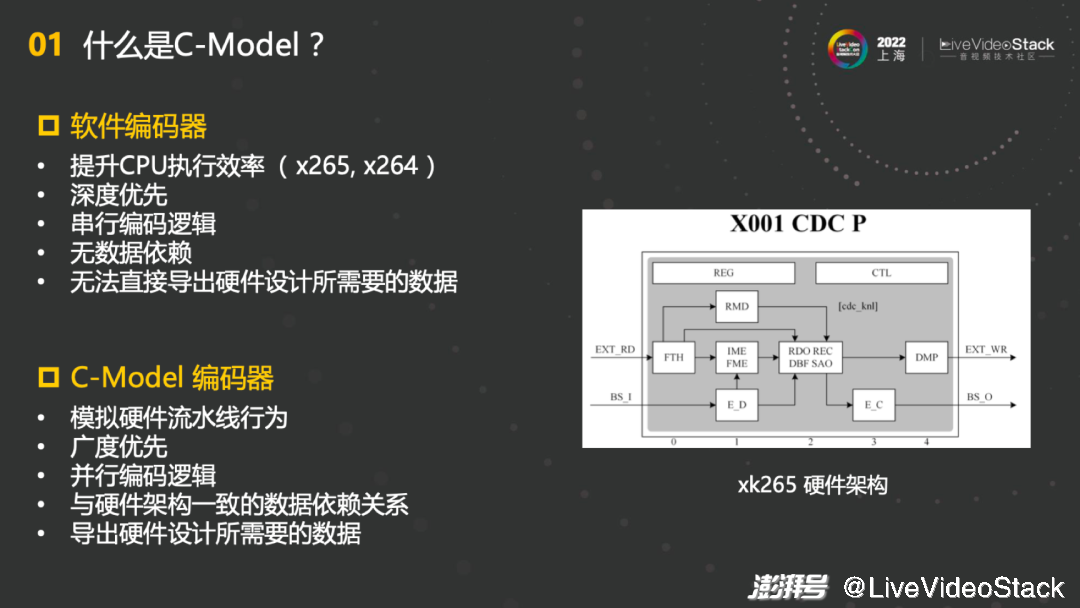
软件编码器的主要目的是提升CPU执行效率,因此在写程序的时候更多是一种深度优先的模式,遵循的是串行编码逻辑,因此不是很需要考虑数据的依赖。因为CPU在执行过程中都是串行的逻辑,它的数据依赖关系没有太多地被考虑。所以直接基于软件编码器设计并行编码器不是非常适合,在行为有很大差异的基础上还无法直接导出硬件设计所需要的数据。
C-Model编码器就是在这个情况下被设计出来的,按照模拟硬件的模块架构和流水线行为进行设计,如右图xk265的硬件架构。首先C-Model编码器需要模拟硬件流水线行为,并且广度优先。所谓的广度优先,就是将硬件对应的模块变成一个独立的函数,保证其流水线前后的数据依赖和硬件的完全一样。并且C-Model编码器遵循并行编码逻辑,实现与硬件架构一致的数据依赖关系,不仅能够提高压缩的效率,更重要的是能导出硬件设计所需要的数据,确保软件和硬件相一致,能够起到非常大的作用。
2.2如何构建高效的C-Model?
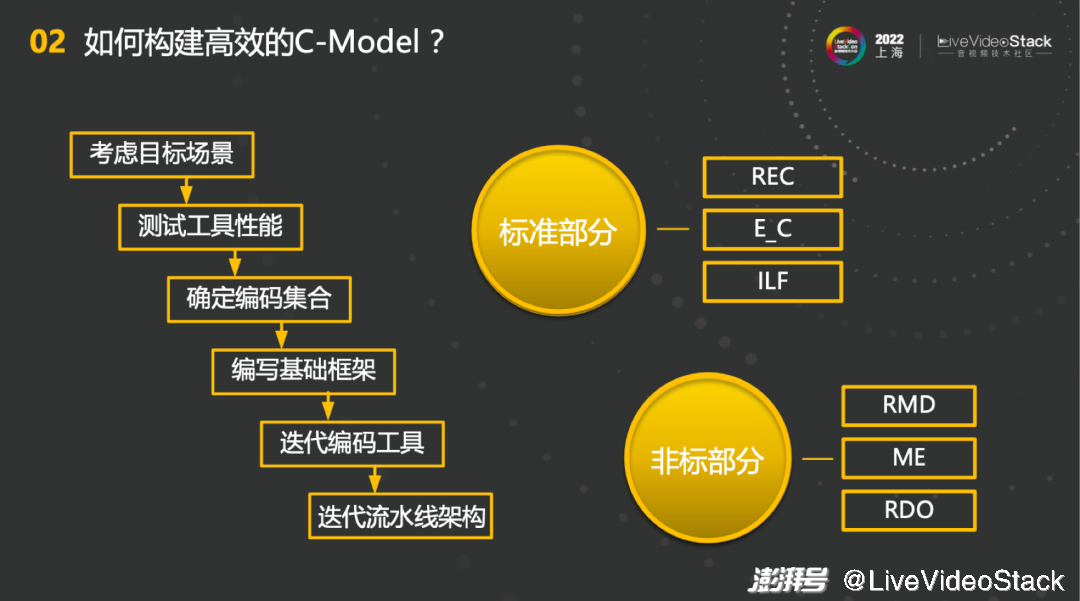
那么如何构建高效的C-Model?首先,编码对于不同场景有很多不同的优化,所以会基于特定的目标场景下构建相应的C-Model。第二步是要测试工具性能,编码器本身含有非常多工具,哪些工具适合,哪些工具不适合都是要进行性能测试的,最终根据场景和其他因素确定目标编码器采用的工具集。基于此编写基础框架,和软件做一些数据对比迭代,保证编码的正确性。最后是非常重要的一步,迭代流水线架构。不同流水线架构有不同的数据依赖关系,也会取得不同的压缩和计算性能。如何在C-Model上体现流水线架构这个问题是对硬件最大的指导。
其中C-Model包含了2个部分,标准部分和非标部分。标准部分就是要完全满足标准的需求,例如REC、E_C、ILF都是标准规定的,需要和标准一模一样,非标部分相当于是可以自由探索的部分,包括RMD、ME、RDO。
3、预测器模块(帧内预测、帧间预测)
第三部分主要是预测器模块。预测器主要分为帧内预测和帧间预测。
3.1帧内预测-新增工具
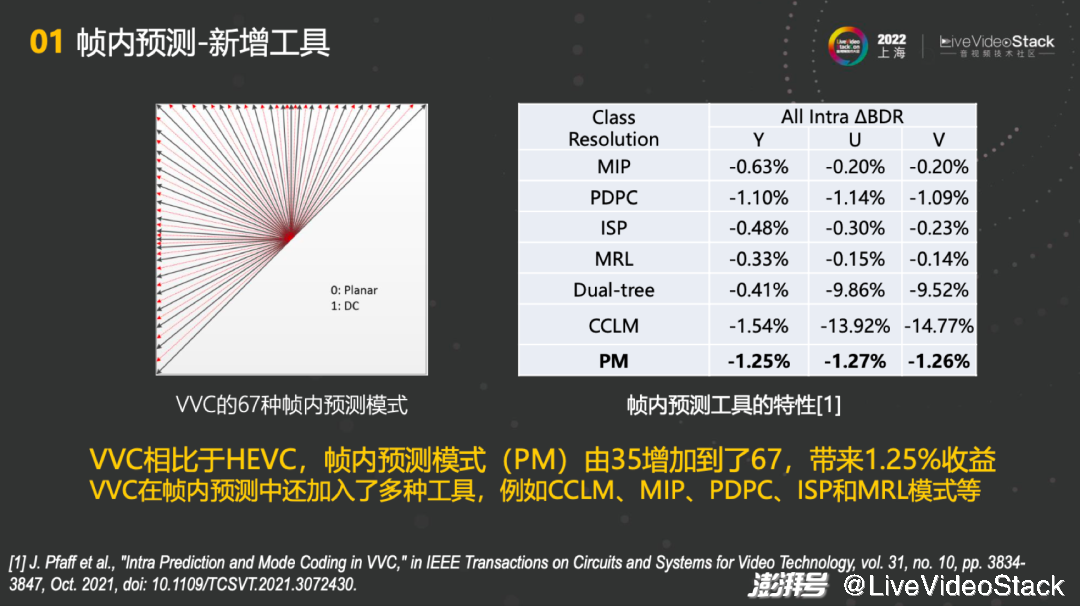
在VVC中,帧内预测的工具做了非常大的更新。首先帧内预测模式由35增加到了67。相比较于HEVC,能够带来1.25%的收益。另外,VVC在帧内预测中还加入了多种工具,例如CCLM、MIP、PDPC、ISP、MRL等。每一个部分都能体现非常好的收益。
3.2帧内预测-硬件设计挑战
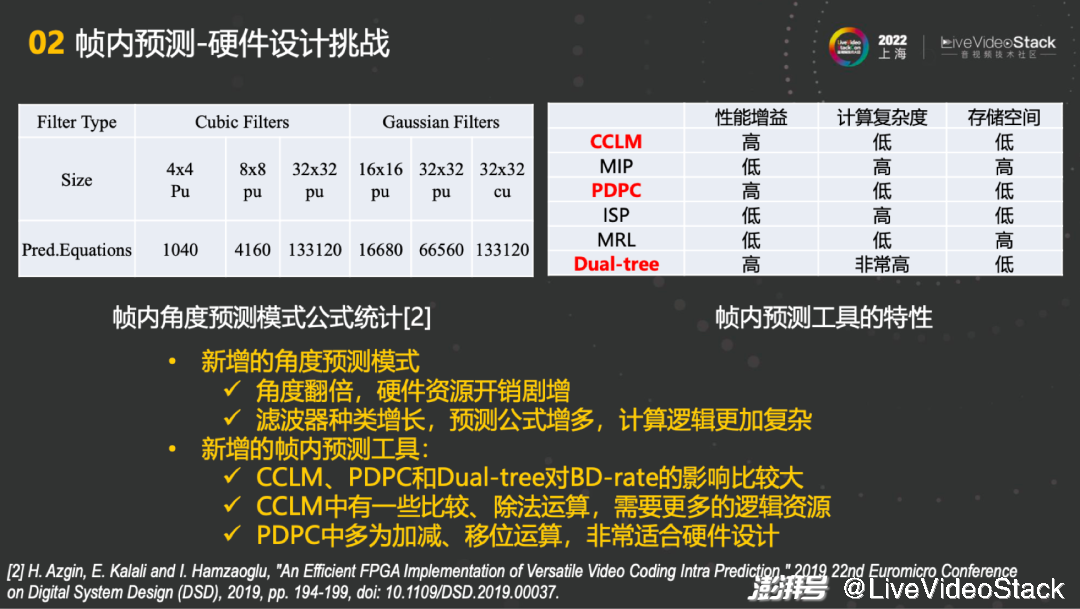
但同时也会对硬件设计带来挑战。模式增多了,也意味着新工具的增加。首先新增的角度预测模式,角度翻倍的同时,硬件资源开销剧增;第二点是预测器的滤波器种类增长非常多,如上左图所示,4×4Pu有1040个公式,而32×32cu有133120个公式,滤波也是同样程度的增长。预测公式增多,计算逻辑更加复杂。
根据上右图,我们也详细分析了CCLM、MIP、PDPC、ISP、MRL、Dual-tree在性能增益、计算复杂度、存储空间的特性。不同工具对不同特性的要求不同,有些对存储空间的要求比较高,因此我们对这些工具的性能增益、计算复杂度和存储空间都做了总结。
3.3帧内预测-现有论文

在论文方面我们也做了大量的调研,帧内预测的现有论文都是针对VVC的。比如2022TMM这篇论文的主要思想就是滤除可能性较小的IBC和ISP,通过重新排列普通预测模式,提升候选项成为最优模式的可能,并且也采用了神经网络的一些方法。其优点在于将VVC中新加入的帧内模式工具都考虑进来了,也能达到性能的一些提升。第二篇2022 ISCAS这篇论文,其主要思想是利用HOG算法剪枝预测,也能取得不错的性能,提升了36.61%。这样做的优点是非常适合硬件的算法,但缺点在于BDBR损失较大。第三篇2019 DSD也是比较类似的做法,采用数据复用的方法,减少预测的公式数目。这样的优点是逻辑资源占用少,但吞吐率相对较低。第四篇是一篇博士毕业论文,同样是在HOG算法基础之上,在AV1标准上进行一些操作,也能有一定的借鉴意义。
3.4帧间预测-新增工具
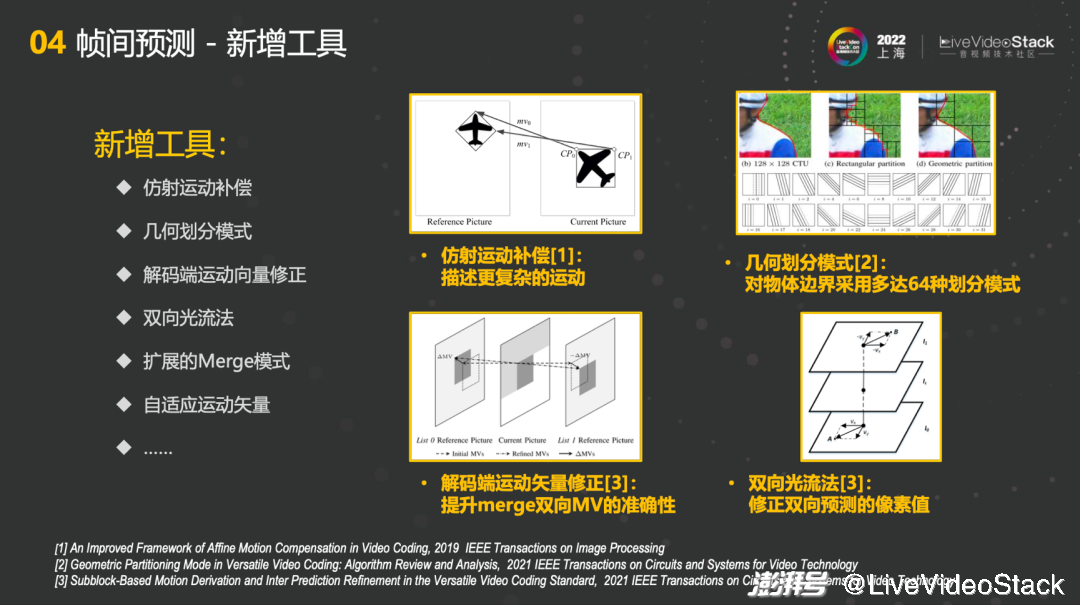
第二部分是帧间预测的新增工具,例如仿射运动补偿、几何划分模式、解码端运动向量修正、双向光流法、扩展的Merge模式、自适应运动矢量等工具,具体举例了四个比较重要的点。第一个是仿射运动补偿,相比较传统的模型,它能够描述更复杂的运动,例如旋转、缩放的操作。第二个是几何划分模式,在传统的划分模式基础之上对物体边界采用多达64种划分模式,能够让匹配更加准确。第三点是解码端运动矢量修正,能够提升merge双向MV准确性,实现更好的匹配。第四个是双向光流法,做运动估计时能够修正双向预测的像素值,其结果也能提供非常好的信息。
3.5帧间预测-硬件设计挑战
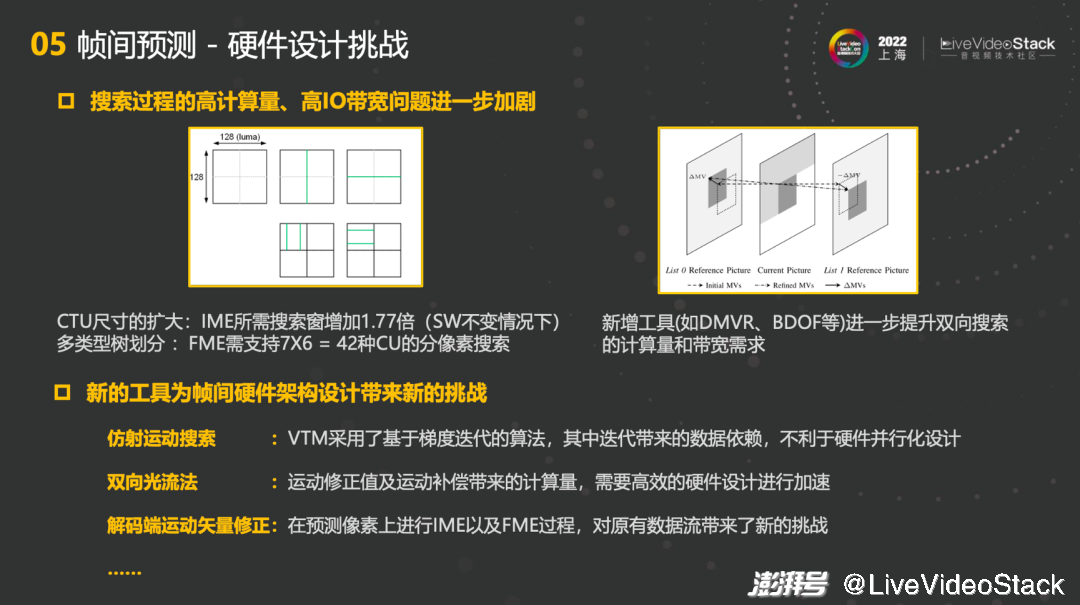
但同时也会碰到一定的挑战。首先,如果不考虑新工具,仅仅考虑传统的模式,VVC会带来搜索过程的高计算量,高IO带宽问题进一步加剧。VVC的CTU尺寸扩大最大至128x128,在SW不变情况下,IME所需搜索窗增加1.77倍。但如果同时增加的话,整体计算量会非常大。第二个是多类型树划分中的FME,需要支持7x6=42种CU的分像素搜索,也会带来非常大的开销。另外,新增工具比如DMVR、BDOF进一步提升双向搜索的计算量和带宽需求,以上这些都是比较传统的。
新的工具为帧间硬件架构设计也带来了新的挑战,例如仿射运动搜索,VTM采用了基于梯度迭代的算法,其中迭代带来的数据依赖,不利于硬件并行化设计;双向光流法中,运动修正值及运动补偿带来的计算量,需要更加高效的硬件设计进行加速;解码端运动矢量修正,在预测像素上增加了IME和FME的过程,对原有数据流带来了新的挑战。
3.6帧间预测-现有论文
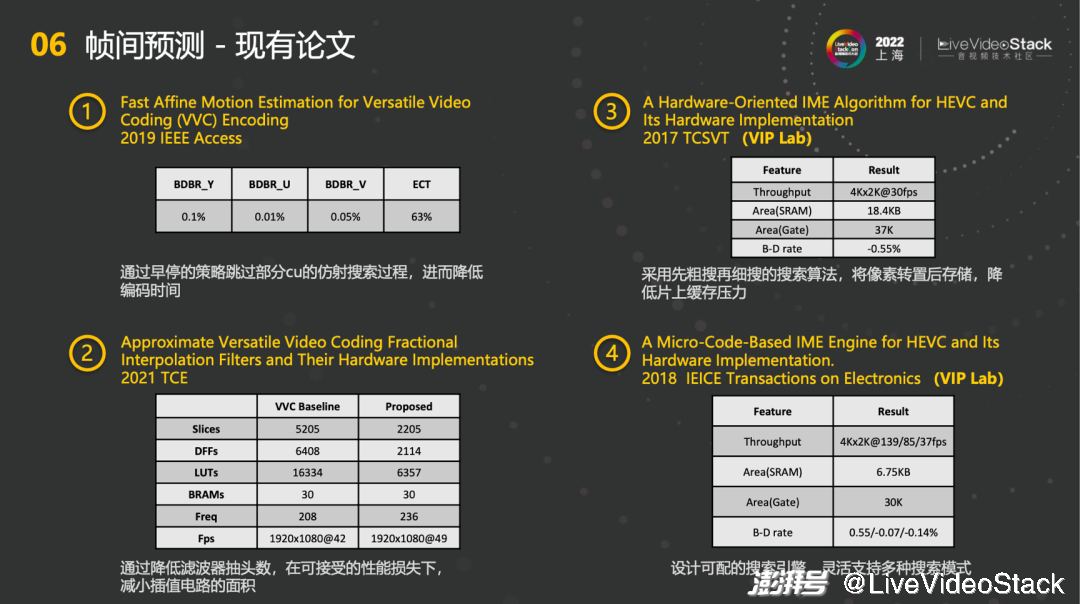
针对帧间预测也有一些论文。第一篇2019 IEEE Access通过早停的策略跳过部分cu的仿射搜索过程,进而降低编码时间,在ECT降低63%的基础上,视频损失质量不会很高。第二篇2021 TCE,主要是针对FME的搜索过程,通过降低滤波器抽头数,在可接受的性能损失下,减小插值电路的面积,降低硬件的开销。第三篇是2017 TCSVT,主要是在像素上进行一些操作,采用先粗细再细搜的搜索算法,将像素转置后存储,降低片上缓存压力。这样的好处是在搜索路径上不受限制,既可以横向也可以纵向。第四篇是 2018 IEICE Transactions on Electronics的可编程的编码引擎,希望能增强IME的可编程性,设计可配的搜索引擎,后期灵活支持多种搜索模式。
4、重建环路模块(RDO、变换量化)
第四部分是重建环路模块。
4.1 RDO-简介
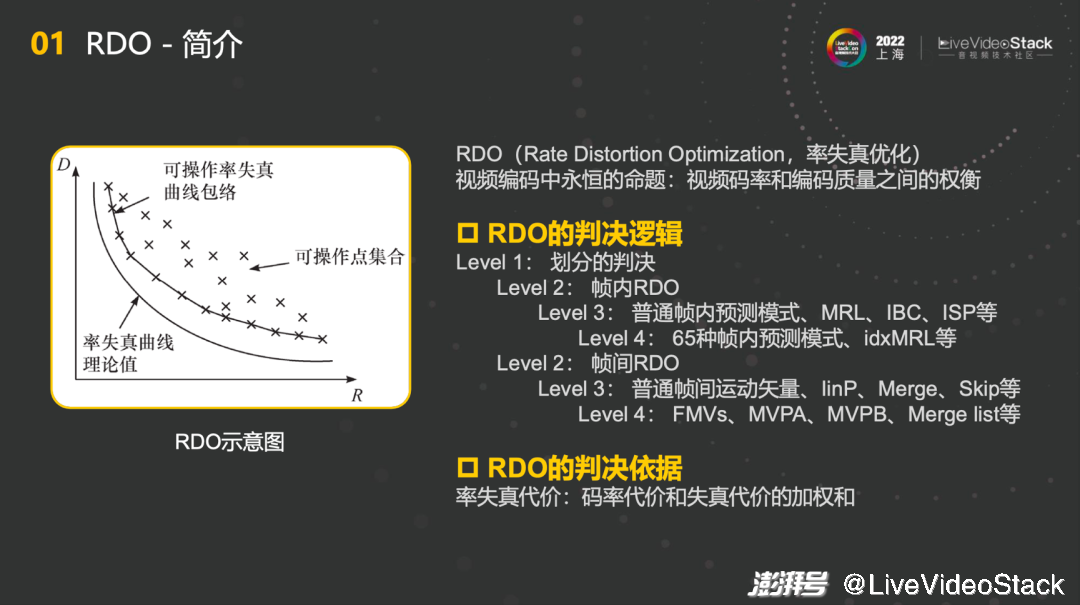
首先RDO是Rate Distortion Optimization的简写,其判决逻辑可以分成以下几个level,首先level1进行划分的判决,level2要根据帧内和帧外做RDO。如果是帧内预测模式,level3就需要决定采用MRL、IBC、ISP等方式,level4就是在65种帧内预测模式中判断使用哪种方式。如果是帧间ROD,level3需要判断普通帧间运动矢量,例如linP、Merge、Skip等,最底层的level4则需要关注FMVs、MVPA、MVPB、Merge list等。总体来说,RDO的判决依据是率失真代价,精准地做出码率代价和失真代价的加权和,找到最优解。
4.2 RDO-硬件设计挑战
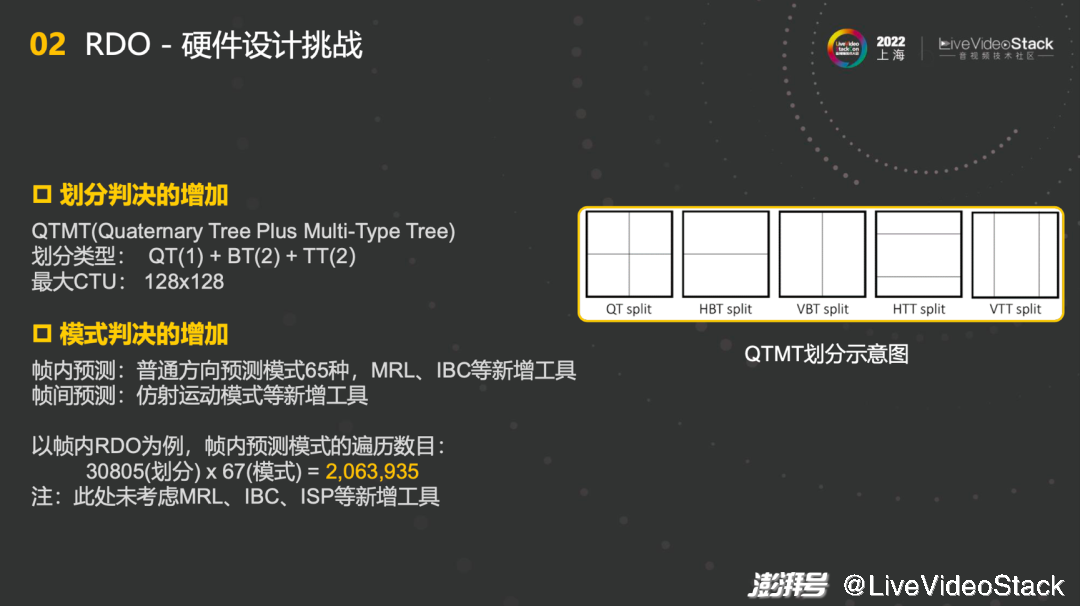
在RDO硬件设计中遇到的第一个挑战就是划分判决的增加。QTMT的划分类型非常多,最大CTU也达到了128x128,形成了不小的挑战。第二个挑战是模式判决的增加,无论是帧内还是帧间。以帧内RDO为例,帧内预测模式的遍历数目乘起来能达到2063935。RDO的引擎需要在非常短时间内在在这些模式中选择出一种最佳最适合的模式。所以,整个计算量和过程还是比较复杂的。
4.3 RDO-现有论文情况

我们也做了关于RDO现有论文的调研,这些论文也各有优缺点。第一篇2022 TMM的主要思想是滤除可能性较小的IBC和ISP,重新排列普通预测模式,提升候选项成为最优模式的可能。第二篇2020 Access利用了方差和Sobel算子进行划分判决,帮助我们实现计算量的减少,保证图片质量。第三篇2022 TCSVT主要是充分利用了有效信息,包括纹理特性、编码信息、上下文信息等实现软件测试性能SOTA。第四篇2020 ICIP利用了NN网络进行后续辅助的判决,提升运算性能。
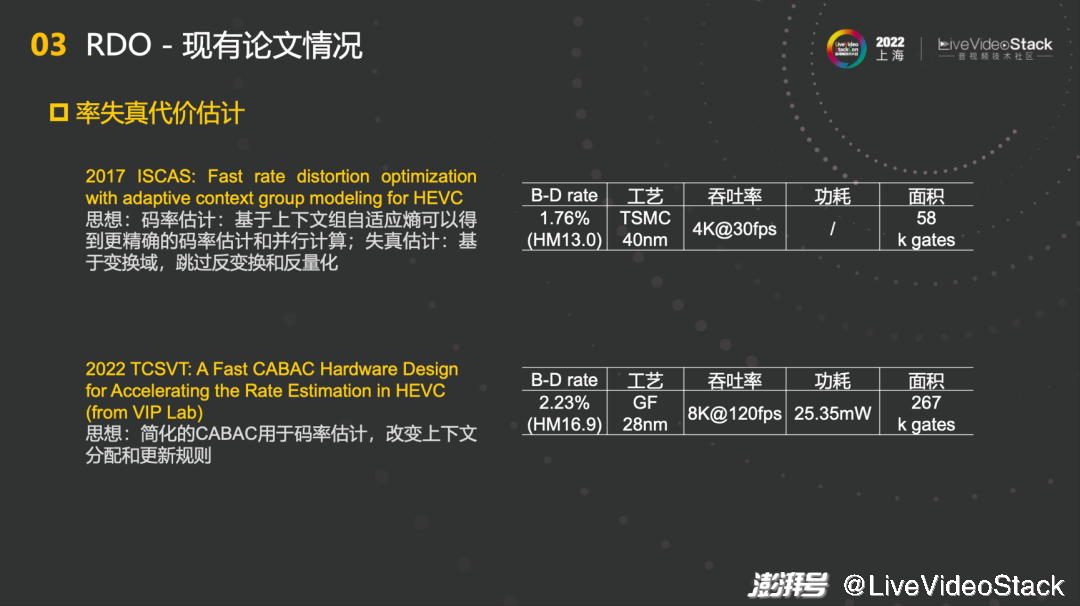
关于率失真代价估计也有现有论文的调研,告诉我们如何去预估rate和distortion。2022 TCSVT这篇告诉我们如何去设计Fast CABAC Hardware,帮助我们迅速地进行码率估计,从而更优地判决RDO,改变上下文分配和更新规则。
4.4 变换-简介
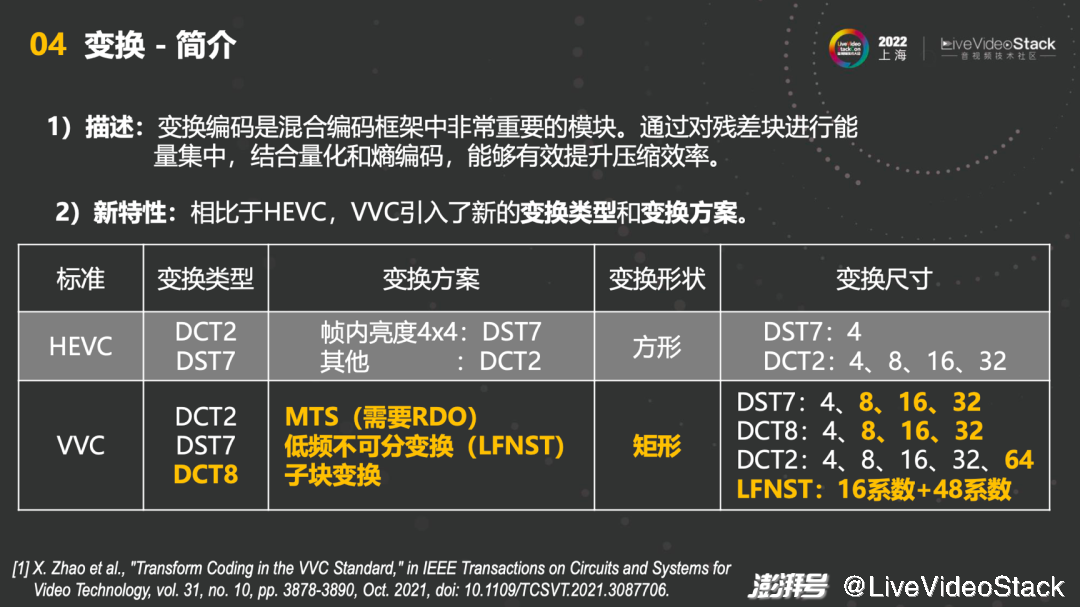
第三块是变换,变换编码是混合编码框架中非常重要的模块。VVC中的变换引入了新的变换类型和变换方案。首先能看到对比,HEVC中的变换类型只有DCT2和DST7,并且大部分的变换都是通过DCT2来做的,DST7只有非常小的一部分。但VVC的变换类型有DCT2、DST7和DCT8,并且每一个都是MTS,选一个最佳的作为最终的变换,因此需要RDO。此外,VVC的变换形状也是矩形,变换尺寸也更加全面,可以看到上图黄色字部分都是VVC中新增的。
4.5 变换-硬件设计挑战
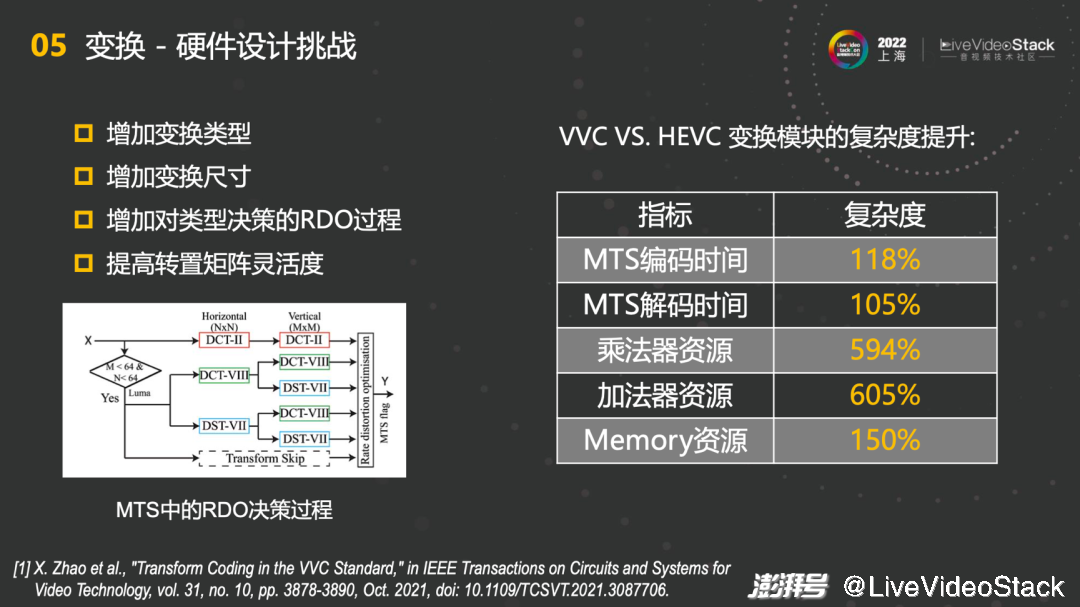
变换中也会遇到很多硬件设计挑战,例如增加变换类型、增加变换尺寸、增加对类型决策的RDO过程、提高转置矩阵灵活度。MTS中的RDO决策过程意味着要么花费五倍时间每个都计算一遍,找到最优解,要么花费五倍的硬件并行走一遍,因此对硬件设计都有更高的要求。右图表格是VVC VS. HEVC变换模块的复杂度提升,在这里不考虑并行,只考虑实现一种。首先MTS编码时间和MTS解码时间复杂度提升了118%和105%,乘法器资源和加法器资源有将近6倍的提升,memory资源提升了150%,因此总结整体硬件代价会有6倍左右的提升。
4.6变换-现有论文情况

针对变换也做了现有论文的调研。首先单类变换的优化设计中,针对DCT2主要是通过合理的数据重排,提高蝶形变换过程的电路复用率,以减少模块面积。针对DST7和DCT8,通过分析两种类型变换矩阵的共同特征,使用常系数乘法的优化方法,减少核心计算单元的使用,以减少面积。相比较分别实现的方法,可以节省73.1%的资源。

其次对所有变换类型的统一设计中,今年2022 ISCAS的论文通过分析所有类型变换矩阵的共同特征,设计统一计算单元,实现单一架构完成所有变换类型功能,吞吐率能达到8K@90fps,相比较前人工作也能节省大量资源。针对近似变换,主要也是运用在码率估计,通过探索不同类型变换矩阵的关系,使用稀疏的调整矩阵,以很小的代价完成从DCT2到DST7/DCT8的结果近似。
5、输出模块(ILF滤波、熵编码)
第五部分是输出模块,主要是ILF滤波和熵编码。
5.1 环路滤波-简介
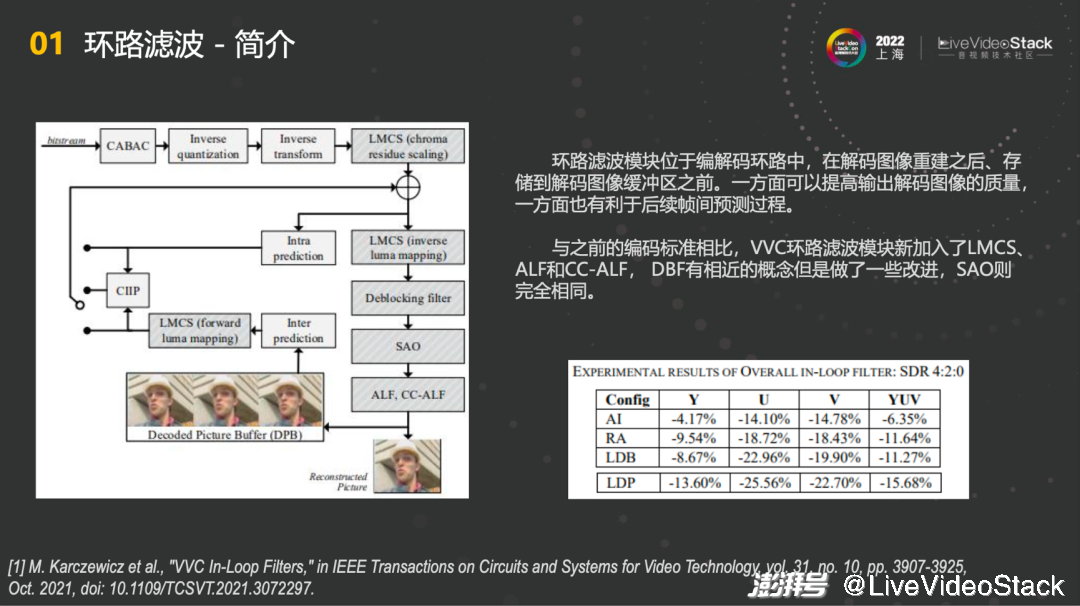
与之前的编码标准相比,VVC环路滤波模块新加入了LMCS、ALF、CC-ALF,DBF有相近的概念但是做了一些改进,SAO则完全相同,整体实现了不错的性能提升。
5.2 环路滤波-硬件设计挑战
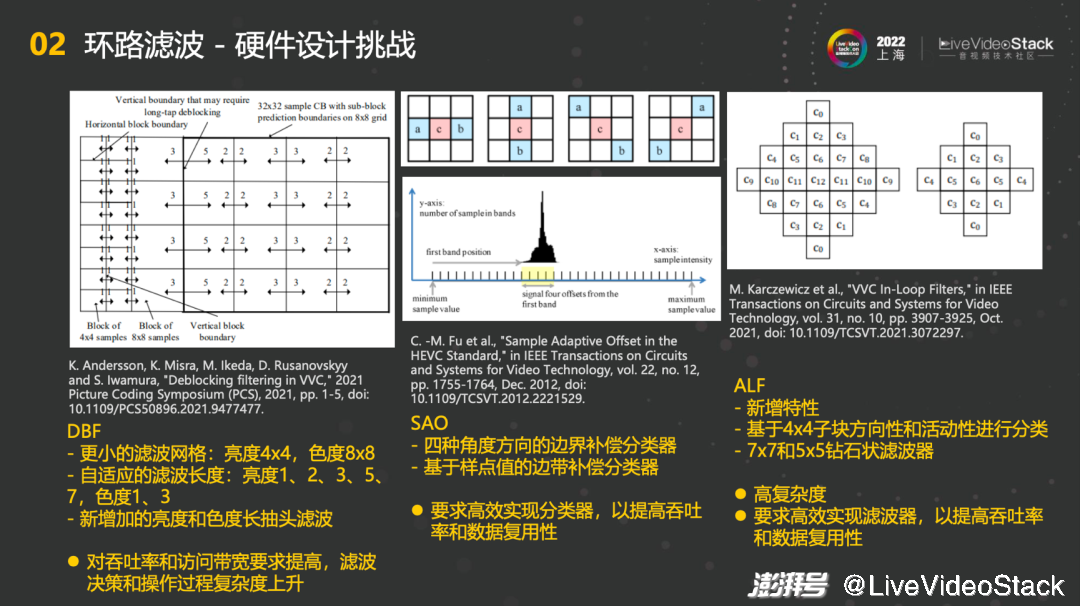
环路滤波中也会遇到一些硬件设计挑战。在DBF这块,首先更小的滤波网格造成了更大的计算量,因为需要针对小细节上的滤波。其次新增了自适应的滤波长度和新增加的亮度和色度长抽头滤波,最终对吞吐率和访问带宽要求提高,滤波决策和操作过程复杂度也会上升。在SAO这块,基本上保持一致,没有什么太大的差别。在ALF这块,有新增的特性,基于4×4子块方向性和活动性进行分类。此外还采用了7×7和5×5两种钻石状滤波器,带带来了高复杂度和高计算量,因此要求高效实现滤波器,以提高吞吐率和数据复用性。
5.3 环路滤波-现有论文情况

针对DBF和SAO列了一些比较经典的论文。第一篇2008 TSCVT的主要思想是如何解决AVC DBF的数据依赖和数据复用关系,提高吞吐率的同时也减小存储需求。第二篇2017 TSCVT和第一篇比较类似,都是解决数据依赖和数据复用关系的问题。第三篇2016 TMM主要是解决DBF和SAO的架构相融合,能够实现DBF和SAO的编解码,提高吞吐率的同时也减小存储需求。针对ALF的论文,2021 ASICON的主要思想是通过10×10参考块的组织形式实现子块的分类和滤波,能够实现ALF的解码,提高吞吐率、减小存储需求和节省硬件资源。
5.4 熵编码-简介
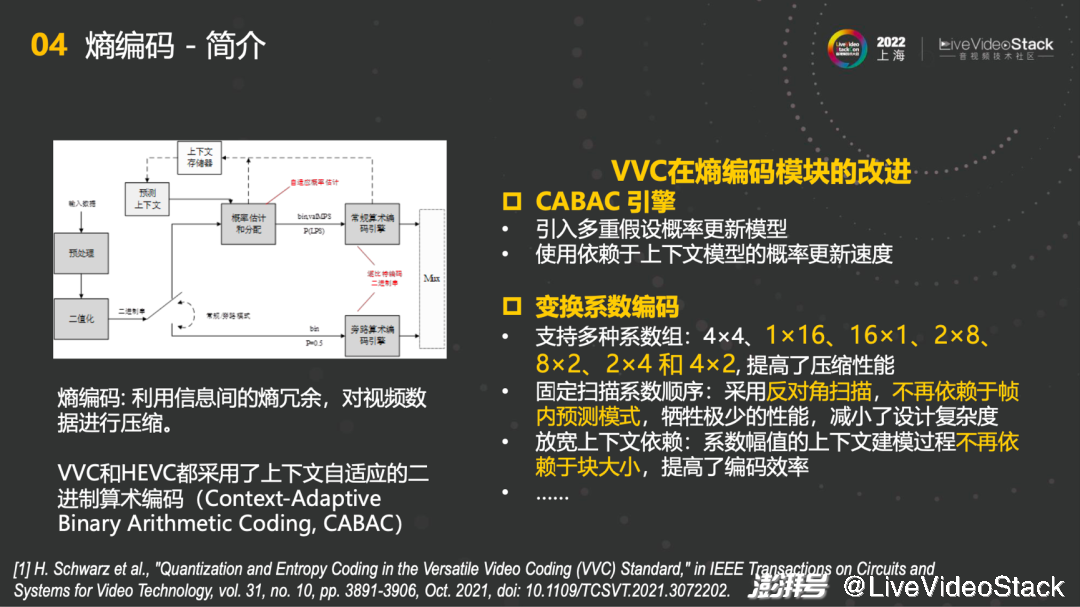
第四块是熵编码,利用上下文信息间的熵冗余,对视频数据进行压缩。VVC在熵编码模块上做的第一个改进是CABAC引擎,引入了多重假设概率更新模型和使用依赖于上下文模型的概率更新速度,使得整体更加灵活。第二个改进是变换系数编码,支持多种系数组,4×4、1×16、16×1、2×8等等,配合VVC的块划分的同时提高了压缩性能了;第二个在固定扫描系数顺序中采用了反对角扫描,不再依赖于帧内预测模式;第三个放宽上下文依赖,不再依赖于块大小,提高了编码效率。
5.5熵编码-硬件设计挑战
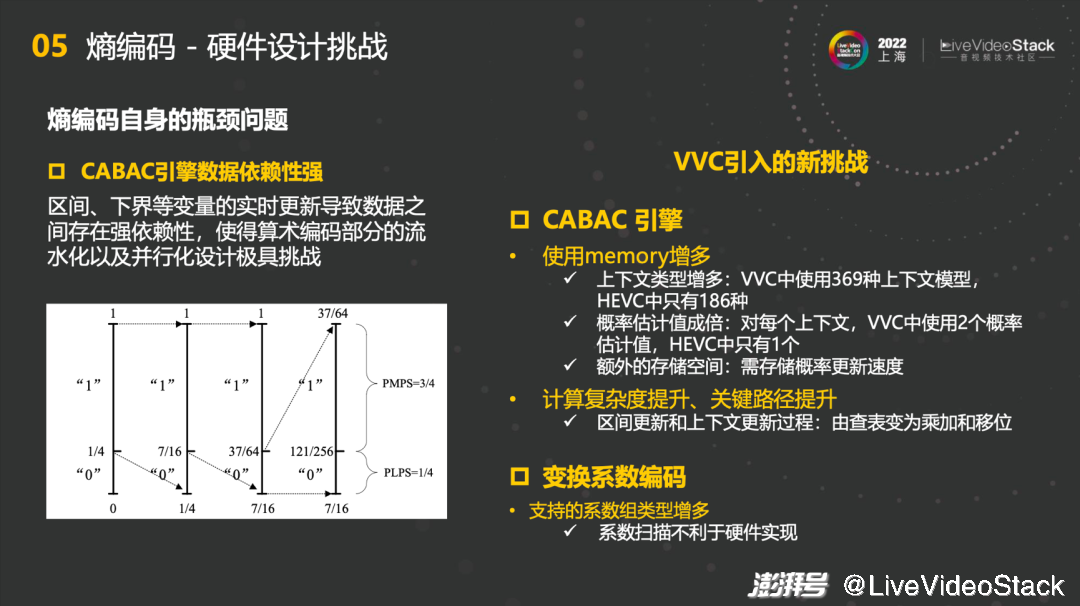
熵编码中遇到的硬件设计挑战,首先是熵编码自身的瓶颈问题,CABAC引擎数据依赖性强,不适合硬件并行实现,串行使得算术编码部分的流水化以及并行化设计极具挑战。VVC在这个基础上又引入了新的挑战,第一个是CABAC引擎中使用memory增多,上下文类型增多,VVC中使用369种上下文模型,HEVC中只有186种。其次概率估计值成倍,对每个上下文,VVC中使用2个概率估计值,HEVC中只有1个。最后是额外的存储空间,需要存储概率更新速度。第二个是计算复杂度和关键路径的提升,区间更新和上下文更新过程中,由查表变为乘加和移位。
此外,变换系数编码中支持的系数组类型增多,扫描方式不一样的话,系数扫描不利于硬件实现。
5.6熵编码-现有论文

关于熵编码也有些论文的调研,关于VVC暂无硬件设计论文,主要都是早期针对HEVC的论文。第一篇2015 TCSVT提出了很多很好的技术及其效果。第二篇2018 ISCAS提出了在多重旁路模式并行处理,提升了吞吐率且不影响关键路径。第三篇2018 ICSICT也在之前的基础上不断提升。
6、总结与展望
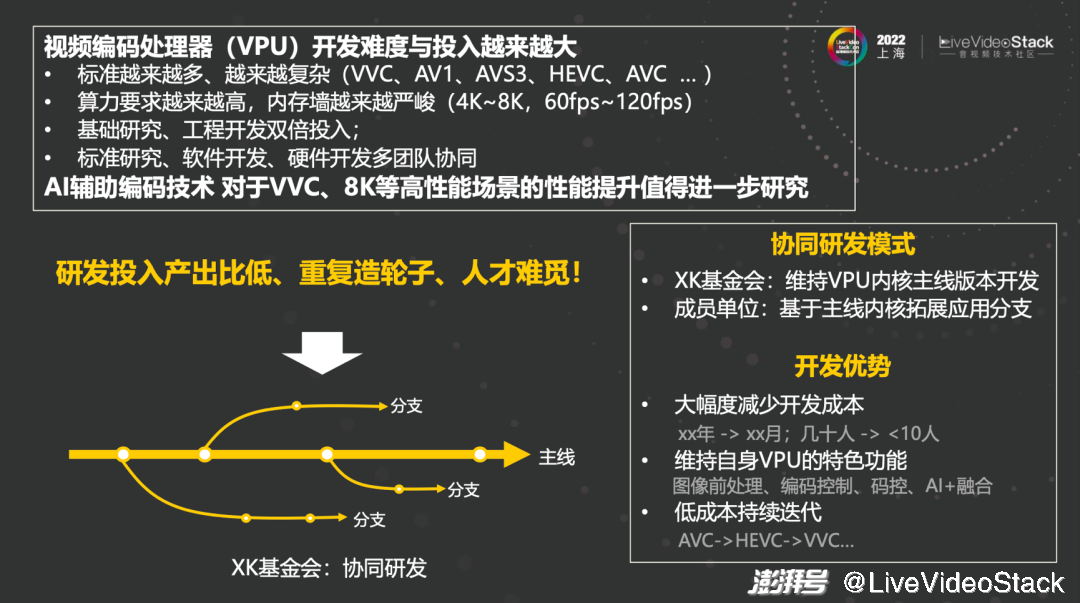
首先视频编码处理器开发难度与投入越来越大,标准越来越多、越来越复杂。一般来说,实现VVC编码器的硬件面积是HEVC的五倍左右,新标准的层出不穷使得难度大大提高,算力要求越来越高,内存墙越来越严峻,需要基础研究、工程开发双倍投入,同时也需要标准研究、软件开发、硬件开发多团队的协同。
其次AI辅助编码技术,面向VVC、8K等高性能场景的性能提升值得进一步研究。这点我们也在继续探索,如何能在其繁多的模式中又快又准地找到一个最优解是我们研究的命题。传统的做法可能都没有办法达到,在未来我们也希望协同研发的模式能够实现。
最后介绍一下我们的芯开基金会,我们目标是构建一个视频编解码处理器的标准技术平台,减少重复造轮子的工作,让产业界可以共享我们的处理器研究成果。芯开基金会负责维护处理器的主线版本,相关产业合作方可以基于我们的主线版本扩展处理器分支,添加其独特性。这样产业界可以实现最小人力投入实现其专有视频编解码处理器的特性,大大提升产业的生产效率和降低创新的成本。我们非常欢迎产业界的合作伙伴与我们联系,共同推进视频编解码VPU处理器的开发。
谢谢大家!
(全文完)
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

