- +1
声网3D在线互动场景空间音频的实时渲染——如何把“声临其境”推向极致
编者按: 千人有千耳,不同的人耳对于声音方位的适应已形成习惯,但在Meta RTC场景中如何让不同人也能畅想“身临其境”的感觉?3D在线互动场景空间音频的实时渲染又有哪些应用?LiveVideoStackCon 2022音视频技术大会上海站邀请到了声网音频策划负责人冯建元,为我们分享3D在线互动场景空间音频的实时渲染。
文/冯建元
整理/LiveVideoStack

大家下午好,我是来自声网的冯建元。
今天给大家主要分享一下声网在RTC 3D互动场景中是如何操作空间音频的渲染。让人在虚拟的场景里感受现实生活中一样声临其境的感觉。

我在声网的主要负责音频算法的开发,之前也做过语音的增强、音效,包括音频的编解码的工作,也发布过基于AI的声网Silver之类的编解码器等,也开过一些介绍音频的课程,包括《搞定音频技术》等等。

今天主要是围绕Meta RTC,探讨如何实现声临其境,需要哪些渲染的方法,以及不同的声音的渲染方法,是如何通过端云结合的形式去实现的,这会涉及算力成本、怎样部署更合理、低延迟等等。最后介绍空间音频在行业有些怎样的应用,是如何重塑我们在游戏以及社交行业的不同音频体验。
1、在Meta RTC场景中如何实现“身临其境”?

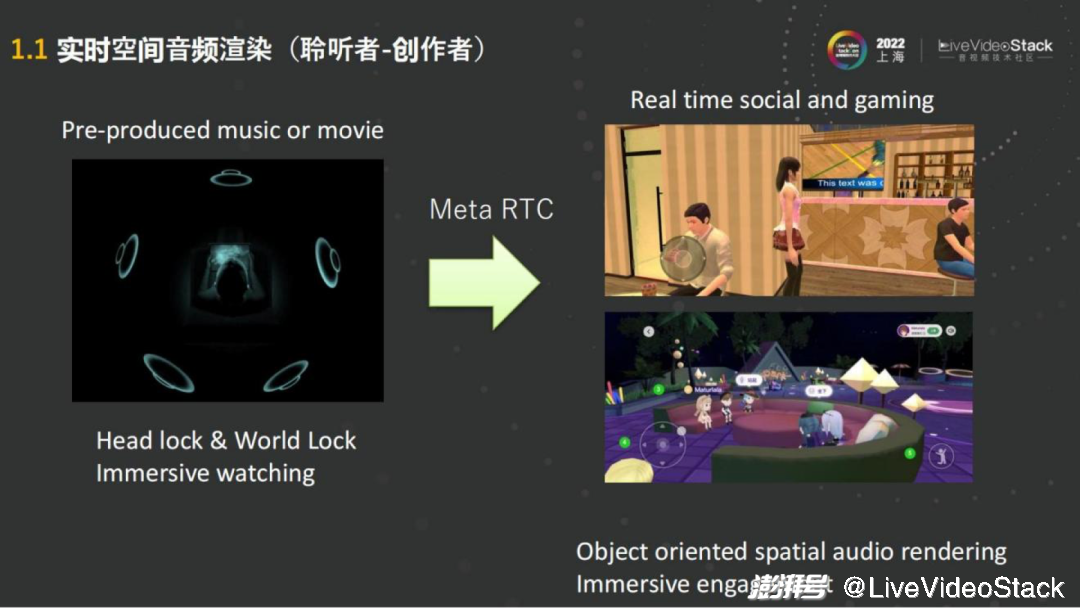
去年苹果发布了AirPods能够支持空间音频之后,空间音频迎来了一个小的高潮。主要的技术是基于杜比Atmos、DTS这些音频的制作,来实现沉浸式的多声道的播放。
例如通过苹果的AirPods听空间音频的音乐,通过使用者头部的转动,会发现声音可以根据手机和头部的位置实时移动。这些音源多数是需要预先制作的,在RTC的场景中每一个人就是内容的生产者,可以理解为使用者在虚拟的世界里去演一部电影,需要去听周围的任何一个音源的声音,会有空间的感知,相对的在远端进行互动的人也同样需要在这种环境里体验沉浸式的音频。
其实在Real time social或者gaming的场景里面,加入了位置信息,比如不同的朝向、距离等,就可以对声场中的人或者音源去进行渲染。这些大部分都是基于目标的渲染,就比如人们作为一个听音者,在下面听我说话,我在有些人的左边,也在有些人的右边,但声音会通过现场的扬声器播放,会有一个整体的声场。这些都可以通过针对这些无论是说话人还是扬声器的音源来进行渲染。
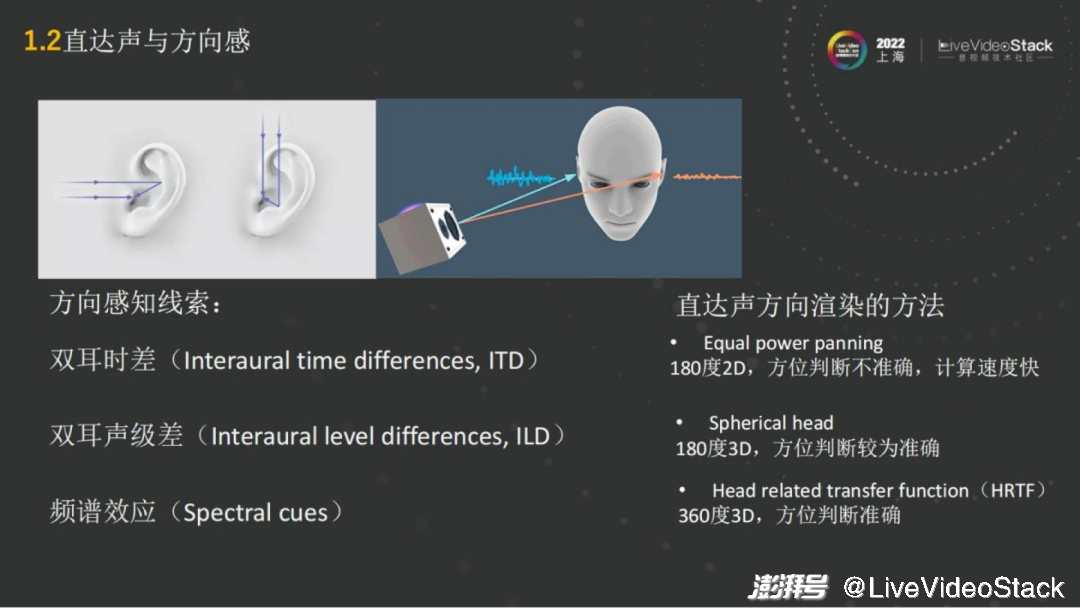
从具体的技术角度而言,如何去实现空间音频的渲染呢?首先我们把它分成直达声和混响。直达声就是发出的声波直接传到人的耳朵,人的两只耳朵是听音辨位的一个前提条件,因为两只耳朵会有双耳差的音源的线索,这样就能通过线索来进行声音的位置判断。
主要的方向感的线索,比如双耳的时间差。就像在人的右边说话,右耳是最先接收到声波信号的,左耳就会有跨越头部的延迟。通过延迟就能大致了解声音大概是在哪边。
第二个就是双耳的音量也会有所差异,因为声音在传播的时候会有所衰减,左右耳就会有不同的音量,这个比较显而易见。
第三个就在于每个人的耳朵耳廓是有朝向的,有些人的耳廓比较朝前,像招风耳,那他对前面声音的感知会比较明显。耳廓信息,它会对人感知到的声音,不同的频段的响度,都会有频谱的效应。所以每个人耳朵听到的音色都是不一样的,根据耳廓和声音传播的方向都会有所区别。
通过这三个不同的感知线索,就可以很清楚地分别空间中声音的位置了。为了去渲染音源,找到它所在的位置,同时会利用这三个线索。
例如简单的方法,左右耳去做一个panning,即做一个音量的区别,就能简单的实现2D空间的180度只能区分左右的panning算法。这种算法的优点就是只需要控制耳机左右耳的音量,几乎没有什么算力。同时缺点也很明显,它只控制了左右耳的音量,如果音源是在正中间,无论是上下还是前后,都是无法去通过音量来调整的,所以就只能实现180度的2D。如果再精确一点,那就会用到头部模型,例如 Spherical head——把头模拟成纺锤形状。能将左右耳、音级差进行模拟,获得180度的3D的渲染。但这依然很难模拟人耳完整的信息,前后的信息更多是靠耳朵的形状做音色上的区分。
那么最精准的是什么?最精准的渲染方法就是Head Related Transfer Function(HRTF),基于HRTF的渲染。
这是目前空间音频基于 Object渲染的方法中最常用的一种,能够实现360度每一个3D的角度都准确地判断。
具体实现讲解:

在几十年前HRTF技术就产生了。在人耳朵的不同的方向放一个声源,例如放一个音箱,然后通过去测量每一个方向音箱到人耳传递方程的冲击响应,就能得到球面的双耳的冲击响应,这就是HRIR。
如上左图,几乎所有的方向都会测量一遍,就会得到一个离散的冲击响应,可以通过差值的方法把它变成连续的整个球面各个方向的冲击响应,当有一个单声道的声音过来的时候,就可以“告诉”它人耳在这个位置,去卷积这个方向的冲击响应,就可以得到双耳渲染道的音频。
目前看来这个方法可以说是最准确的,它是真人在全消实验室中进行实验、采集得到的。
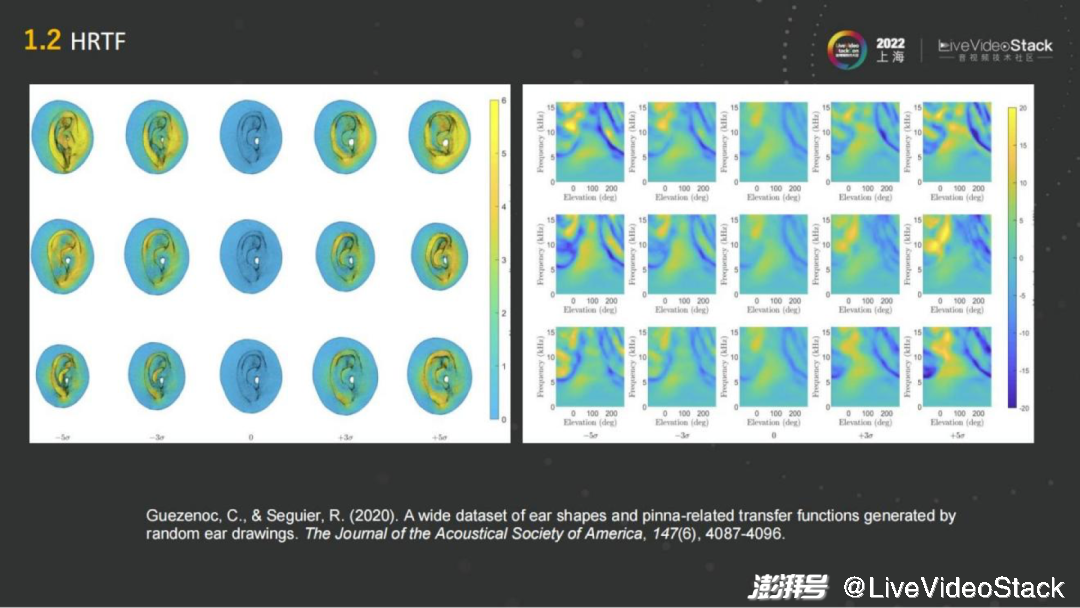
正常人的耳朵虽然都差不多但还是有区别的,每个人的耳朵无论是朝向还是形状都不太一样,都相当于一个滤波器,所听到的声音虽然左右都能区分,但是其实一个人听到的声音跟其他人听到的声音是不一样的。那我们要如何判断声音的方向或者是空间的感知呢?
它其实是一个长期记忆的过程,在长期的生活中,人们通过听不同的方向声音,就像是训练大脑一样,长期的训练就能比较准确判断声音出现在哪个方位。不同的耳朵对于自身而言已经有了适应性,大脑已经被训练好了。因而缺点也比较显而易见,当一个人在操作虚拟环境的渲染的时候,用的HRTF可能是一个通用的HRTF, 它可能是一个人工头的HRTF,也可能是别人的耳朵的HRTF,跟现实生活中的音色的体验就会有差异。

基于此我们就继续看能不能把它再做得极致些,能够让使用者有一个性化的体验。这就是个性化HRTF,大概经历了10多年的发展,通过研究怎样通过建模的方法以人的耳朵或者头部为基础,得到个性化的空间音频渲染的方法。
在这里面我主要罗列了一些近些年比较常见的方法,例如最简单的通过测量耳朵的生理结构,包括20多种不同的结构例如、长、宽、深度、耳道的大小等等。通过量取这些数据,然后把它们进行 HRTF的建模,把通用的HRTF调整成符合不同耳朵的参数,来达到个性化。这种方法还是比较有难度的,只能提取较少的一个信息去操作,准确率也不是很高。
随着AI的模型的引用,包括现在有很多技术也是基于AI的模型去做的。最新的像Meta 发布的一个方案,通过扫描整个人的3D头部模型,用3D扫描信息作为输入,然后用AI的模型去生成个性化HRTF,目前已经能达到频谱的差异小于1DB,很接近真实的 HRTF测量。
但最准确的测量(Golden standard)还是在实验室里,每一个方向测一遍。目前通过AI模型和头部扫描,基本上能够实现和Golden standard差不多的水平。
例如iOS16,因为iPhone是有深度摄像头的,也有扫描的功能。通过扫描人左右耳朵,可以生成个性化的HRTF。基于此再去做空间音频渲染的时候,就能得到个性化的最自然的空间音频渲染。

刚才主要是聊如何做听音辨位和渲染。另外,人耳都有远近的感知,离得远和凑近讲话听到的声音也是不一样的,针对此比较简单的方法是调整音量。其实人对位置的感知是相对感知,不是绝对感知,即通过距离的由远到近,慢慢地声音变大,或者是由近到远,声音慢慢变小,人能感知到它是在远离还是靠近,但是在某个音量下想要知道它到底离人有多远,是很难通过绝对感知。
这个过程里有很多可以做的。首先音量是在空气中传播的,不同的频段的衰减是不一样的,高频衰减更快,低频衰减更慢。在距离比较远的时候,会觉得发声人的声音除了声音小之外,还变“闷”了,这也是基于人的主观感知。
那么,只做音量和做了空气吸收/不同频响的均衡,有什么样的区别?
示例中的两条音乐,声音都是从25到100米,但能明显听到后者的声音在比较远的时候已经开始变“闷”了,给人的一种更遥远的感觉会更加逼真,这也是距离感知上可以做的一点
这样的衰减如果程度更多一点,例如模拟水下的衰减场景,在水里面说话的咕噜咕噜的感觉,也能够靠这种方式模拟出来。
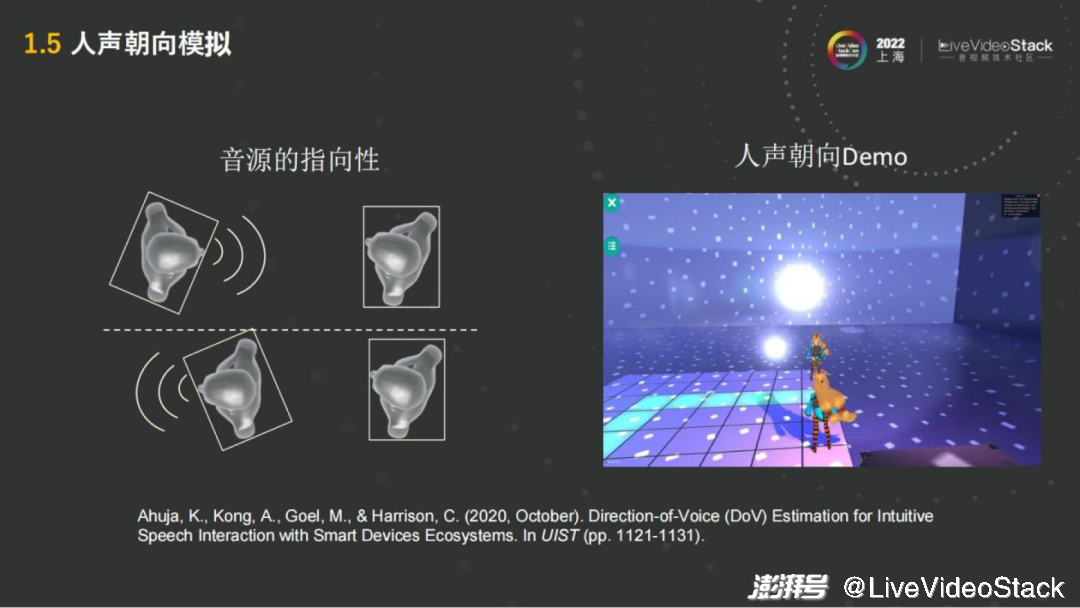
除了距离之外,还有很重要的一点——朝向,正对人说话和背对人说话的声音是不一样的。正对人说话是直接从嘴到另一人的耳朵,中间没有什么障碍,但背对着则声音需要跨过头和身躯,在进入另一人的耳朵,这个过程声音会有衰减。
这也说明音源是有指向性的。无论是人还是音箱,模拟的时候都会有这种指向性的模拟。指向性的模拟来就是在不同的方向,需要对它的不同的频响去做出调整,这也是在空间音频的模拟中比较重要的一点。
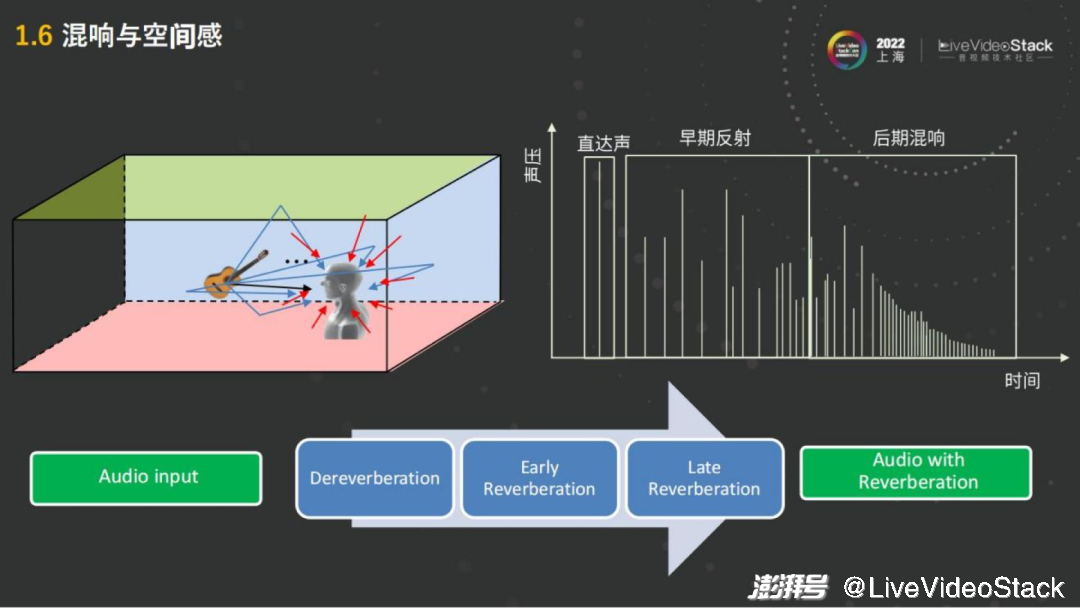
以上所说都是直达声的渲染,一人的嘴到另一人的耳朵,中间没有经过其他物品的反射。在声音的产生过程中人要感受,例如这个房间是大房间还是小房间,它装修的材质是玻璃房还是木板房铺地毯,不同材质也会有区别。
右图而言第一个是模拟直达声,第一个声波过来,会有早期的反射,就像我的声音通过木板、房顶。例如地毯的吸收的能力比较强,反射比较少。
这些反射的声音,会混到人的直达声之中,跟它混接在一起,这样的话人就能感受到所处的空间大概是怎样反射的延迟以及整个反射空间是否密集,就会得到一个混响。混响也分早期的反射,例如第一次反射或者第二次反射。也包括后期的混响,后期混响反射还可以再反射,很多反射的叠加之后就会得到一个比较密集的后期混响。后期混响在玻璃的房间,或者是在混响延迟比较长的大的空间会多一点。
人对空间的感知,空间、装修材质、大小,主要是通过混响来提供的。所以在空间音频的渲染中会起到比较大的作用。如果只有直达声,人就相当于在一个全消实验室,没有任何混响,人的声音会听上去非常的“干”,这个声音就叫干声,如果有混响就比较“湿”,这种叫湿音。
操作渲染并不简单,不能直接的去加一个混响,原因在于在实时RTC的过程中,例如在一个会议室、玻璃房里,本身它就有混响,如果是在混响之上再叠加混响,它就变糊了,人就听不清楚了。在营造一个比较好的统一的混响的环境,或者统一的虚拟房间的环境时,第一步需要先做解混响,把人的声音先再从湿音变成干声,这就是第一步Dereverberation解混响。然后再加入早期的反射,Early Reverberation或是加入后期的混响。早期后期的这些混响可以通过镜面法或者早期的反射,后期的混响可以通过 Feed forward或者Feedback delay这种方式去做。
其实整体的算力来说它比直达声高些,因为整个混响包括很多个声波的模拟,可以提供比较好的空间感,空间感在空间音频中也是比较重要的一点。

在整个声音中有了直达声、有了混响基本上也就齐了,人能听到的声音都有。但在元场景Meta RTC中,它是源于现实但是又超越于现实的,例如你在现实中参加演唱会、鸡尾酒会,周围有很多的人很嘈杂,但是你却想听乐队的声音。这个时候还是挺麻烦的,如果买的座位不是在第一排,可能听不清,听到全是旁边的欢呼声和唱歌的声音。
这种情况需要有一个氛围,就是周边人在说话的同时不会干扰到你对于自己目标的这样听取。这就可以通过人声模糊的方法,把周围的人的声音进行模糊化处理,达到能听到说话声,但是不知道别人在说什么。这也能在互动场景里面提升听声音的体验。

除了模糊还有其他方面,例如在现在(演讲)的环境中,大家的声音都是在没有遮挡情况之下的。但在一个虚拟的世界中,有多个房间,或者双方在隔了一堵墙的情况下,就会有音障既为声音障碍,是需要通过空间音频渲染进行模拟的。
在没有障碍物的时候,声音是直接传播过去的。当有障碍物的时候,它会让人的声音变闷,或者是让人声音的传播的距离变小。在房间外听屋内人说话,近距离可以听到,但离得远衰减后就听不见了。
为了模拟类似的音障、声音衰减的管理,可以通过模拟不同的厚度的障碍物,实现衰减的调整。
面对稍厚的墙,只有一米左右才能听到讲话人的声音。无障碍物或一堵薄墙的情况下声音是慢慢衰减的。声音的障碍还有很多其他的模拟方法,这是其中一种,通过声音的衰减(音量衰减和银色衰减)快慢来模拟。
还有别的模拟方法,例如声音本身是一个衍射的状态,隔的不是墙而是柱子,声音的模拟就会更加复杂。
2、端云结合的空间音频实时渲染引擎的设计

以上所讲从渲染的方式来说都是链路式的,是直达声的渲染,然后做不同的混响,加入一些人声模糊等等。总体上整套使用起来还是有算力成本的。

我们来看整个一条链路如何实现,以及是怎样设计空间音频渲染的流程,算法可以部署在什么地方延时最小,算力最小,成本也可控呢?
第一步在空间音频渲染中需要空间的设计,因为抛掉视觉只谈音频没有太大的意义。我们会有在虚拟场景的一些空间设计,包括复杂的如基于Unity、 Unreal的游戏引擎的3D场景,也有简单的如会议交互场景的头像分布距离和角度,而我们无论是做2D的交互还是3D的交互是要预先设计好的。
有了这个功能之后,在这样的一个场景里,我们自己是类似Avatar的化身,或者是一个头像,我们所在的音源的位置以及朝向,以及听音者的位置和朝向,和虚拟环境的参数,例如房间的大小,中间有无声音的障碍,这些就是Meta Data(元数据)。它是决定怎样去进行渲染的基础。
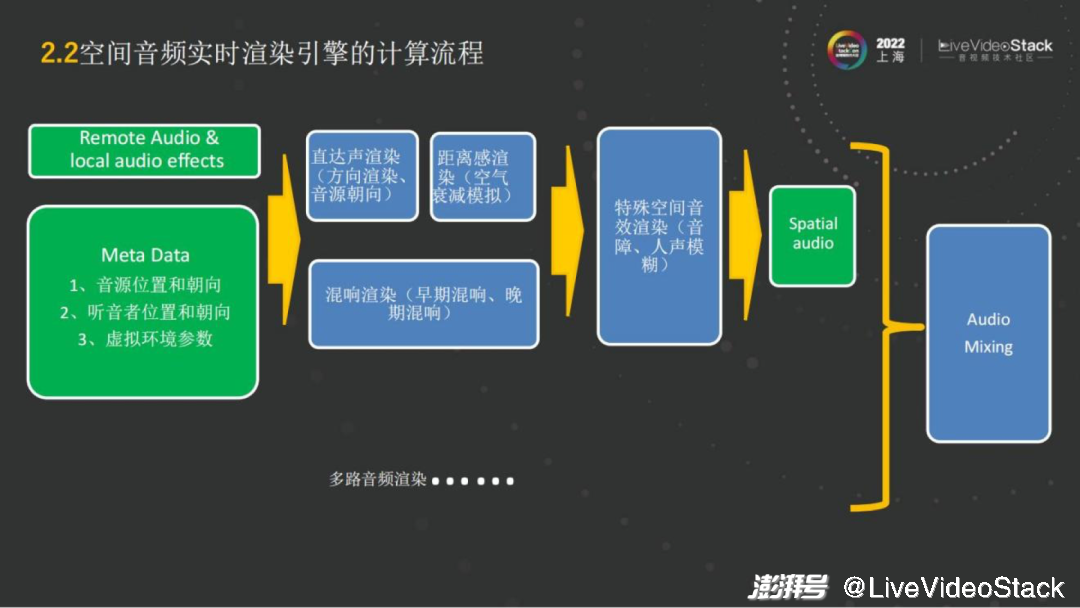
有了Meta Data,再结合传统的RTC的远端的 Audio,或者是local的音效,就可以做空间音频整体的渲染了。例如来了一路音频流,首先要知道这路音频流是属于哪个ID,这个ID的Meta Data是什么,然后就可以对它进行直达声的渲染,包括方向的渲染、音源的朝向、距离的渲染。混响部分就是之前准备好的房间里,包括这个房间大小多少,人处于房间的某个角落还是在正中央,位置在哪,来营造音频流的混响氛围。之后再看有没有特殊的要求,例如是否需要选择性地模糊某些音源。
最后当每路音频传输过来后或每个音源完成了空间音频渲染,接下来就需要做混音,把多路的空间音频混成特定声道,例如耳机就是双耳的立体声,如果是5.1声道,就把它混成5.1声道的播放。
这就是整个空间音频实时渲染的计算流程。从流程来看,它的算法部分整体来说是比较多的,包括直达声的渲染,混响的渲染;从算力上而言,直达声少一些,它相当于编解码中解码的过程,跟解码的算力相当。如果是混响就会复杂一点,取决于混响是精细还是粗糙,精细的混响对应的算力就比较大。
整个流程而言,如果是在可控的范围内,即渲染的路数不多时,在端上运行起来没太大压力,但是如果是千人会议,演唱会,那在端上来说会比较困难。

这里有几种方案,例如中心的服务器去做位置信息的这种计算、或者在端上去做。简单而言,在RTC的音频流里面,是可以直接把Meta信息放到音频的包里去,里面就是 Meta的模块。
音频会随着Audio和Meta Data同时传播到远端,类似于P2P的网络结构,每个人都是在自己的终端设备中进行计算的。若是一个小型的互动场景也是适用的,因为路数有限,收流只要把所有人都收过来,再同时进行计算就可以。如果是在达到50人左右的小型的活动上,一个手机就忙不过来了。首先从场景上考虑,比如很多游戏的互动场景,本身就是有服务器的位置同步的功能,例如打MOBA游戏,没有位置同步就不知道往哪发招。
当有这样的能力后,其实只需要把空间音频的计算加进去,位置同步的功能其实本身就自带。在此情况下,位置同步信息已经由服务器完成,本地只需要计算空间音频的部分,不需要做同步,这样流量也会减小。这个情况下就可以进行小型活动,把位置同步放到服务器上,把本地的空间音频渲染放在端上。
但即使端上能操作渲染,配置稍好的手机也就只能跑到50路左右,再往上就会听到卡顿了,计算不过来了。在大规模的线下会展上,包括演唱会的场景下,就需要在服务器上完成空间音频的位置同步和空间音频渲染。这样在服务器上把所有的流同时进行渲染之后,最后发到远端时,可以进行混音,只需要在接收端去接收一路双声道的信号,就能够感受空间音频。从这个方案其实是增加了服务器的loading,但它有两个好处。一个好处是它能够支持更多同步的空间音频计算的能力。另一个就发流而言,在接收端只需要接受一路流,流量也会减少很多。如果是同时接收100路流,那对于接收端的接受能力也会有很大的挑战。
从空间音频的部署上来说,根据它的规模和并发数,可以找最合适、最经济的方案。大家都想往端上放,服务器loading就可以小一些,但实际上,端上目前而言能支持到50路就差不多了。
3、空间音频实时渲染在游戏、社交等行业中的应用

讲完了算法部署的整个流程,我们再看看空间音频实时渲染在游戏、社交的行业有哪些应用。

有些空间音频会起到增强的效果,有些会重构行业的“新玩法”。就增强而言,互动播客也好,或者虚拟活动,这些都会起到增强的作用。例如受疫情影响,现在有很多的虚拟会场、线上的展会,有很好的3D的展示效果,它只是把空间音频放上去,让人有种在会场里走来走去、亲切交流的感觉,就会起到增强的作用。包括线上的教育等,如乐队的排练,音乐的教学,会需要不同的方位,典型的例如乐队的形式,需要中间有主唱、左边一个吉他手、右边一个贝斯手,这种需要不同位置的渲染,它是增强的效果。
而例如虚拟演唱会、Metaverse 这样的场景,就是一个重构式的变化。
当有了空间感之后,结合头戴式设备,头动、身体转动的时候,也会有一个空间音频的实时渲染。以及人在位置变化的时候,可以实现音频跟随,就整体的效果而言是完全不一样的,比如营造快速移动产生多普勒效应、很多像类似这样的应用会有新的玩法,是之前无法感受到的。
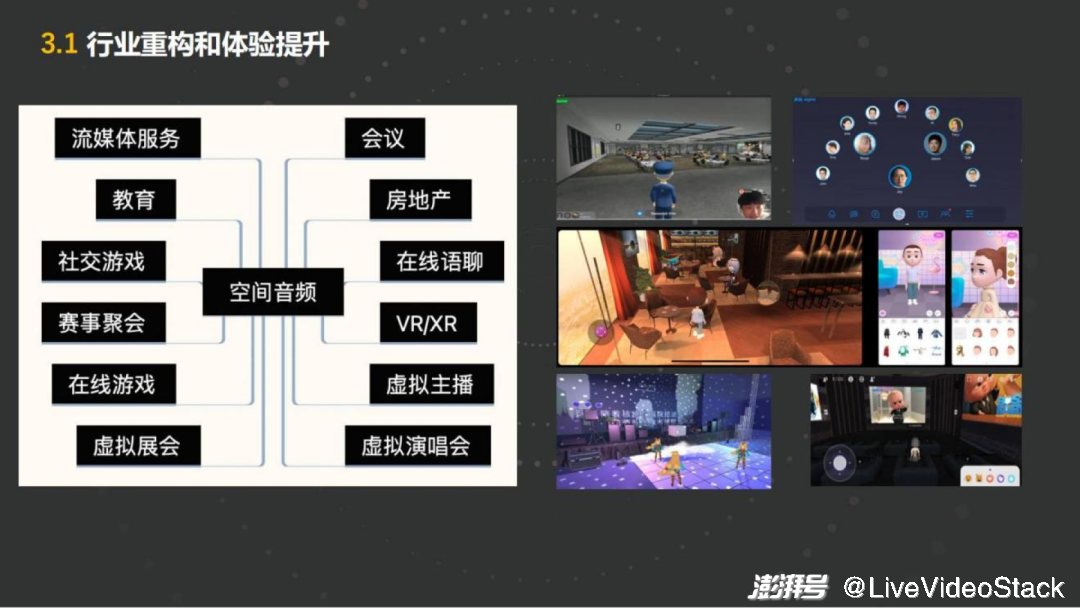
这个行业里面也让人意想不到的应用,包括虚拟房地产,如NFT房地产,它会有一个虚拟的空间,有整个声场的虚拟环境,完全可以作为一个产品进行贩售。
另外一块例如流媒体的服务,现在很多赛事或是电影,观众去观看时它本身会有 immersive音频的格式,在远端体验的时候就需要做空间音频的渲染,才能体验出immersive音频格式 的能力。无论是带上耳机去听,还是用5.1声道的家庭影院设备,都可以把这个能力释放出来。

除了行业上的应用,还可以有多种新的玩法。例如像虚拟环绕声,现有一些的音源,无论是立体声、MP3格式或是无损格式,都是立体声声音,我们可以通过重构这些声音,转换成一个环绕声,使空间感更强。
类似的虚拟环绕声能够把双声道变成环绕声,例如5.1、7.1或者是更多声道的环绕声的体验,这样对音乐的听感或者环绕声听感都能有比较好的提升。这是基于现有的,但如果是基于例如杜比的Atmos做的话,本身就是环绕声,会有更好的播放效果。
除此之外如果需要在音乐里有更好的听感,例如使用Ambisonic的麦克风,可以把整个声场录下来。如果只有一个单声道的麦克风录音,在回听的时候还是一个单声道。如果把整个声场录下来,就可以在整个声场里走动,也可以在整个声场里进行观看。整体而言,无论是交互式的电影还是交互式的现场,都能进行整个声场的采集和回放。
基于Ambisonic技术的麦克风其实在广播电台已经有很多的应用,而线下的RTC场景还是有很多新的体验可以去尝试。

我今天分享的内容总结在这张图里。我们再展望一下还有哪些更多的空间音频的探索领域。其实要展现更逼真的临场感,还有很多新的玩法和新的功能,例如近场的HRTF,贴着人的耳朵说话,类似ASMR的模拟。另外有很多声音,不一定是点状,它可以是一个瀑布,或者是一个“下雨天”。很多声音是体积声,有比较大的声场,体积声的渲染也会对沉浸感有比较大的提升。
刚才我们提到沉浸式的虚拟世界,其实每一个人都是虚拟世界制作者。你本人就是一个导演,或者是在进行比赛,无论是电竞也好,还是真实的场景观看也好,这些都可以通过空间音频把整个声场录下来,然后再回放,就可以实现交互式的电影。人在整个声场里面走动观察每一个细节,都会有很好的沉浸式体验。
同时空间音频的编码还有很多可以深究的地方。如何更好地去进行空间音频的分发,尤其是在实时领域还要满足低延迟和低算力的编解码成本,这也是比较好的探索方向。
另外在Metaverse会有新的 AR和VR的交互式。例如在一个VR的空间里面,我们可能需要瞬移代替走路来解决头晕目眩的感觉。那么瞬移的场景下如何进行交互,这些都是可以跟空间音频结合的。可能在未来的元宇宙世界里,个体可能不是简简单单的一个人,可能是一个超人、是蜘蛛侠的角色,类似的场景都是可以有更多新的交互式的体验。

我今天的分享就到这里,谢谢大家。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

