- +1
我花了八个月和一万块,用AI做了毫无灵魂的音乐
原创 陈东泽 果壳
用程序员的方式,作一首曲子
八个月前,我,一名 33 岁的程序员,报名了小区的钢琴班。在此之前,我没学过音乐。
第一节课,在那间被钢琴旋律塞满的教室里,我被乐谱上连绵有序的音符吸引,萌生出了一个想法:“我是否可以用程序员的方式创作出一首曲子?”
本质上,音乐是一系列按时间有序排列的音符。那么,只要用程序找到藏匿在音符之间的排列规则,就能让程序自动作曲。
对于寻找规则,自然是人工智能(AI)最在行。AI 系统与传统系统最大的区别就是:传统系统的目标是获得答案;AI 系统则是利用已有答案获得规则。
AI 在音乐领域的应用已经很常见,像听歌识曲、曲风分类、自动扒谱等,而用 AI 实现“半自动”作曲?也不是新想法了,网上也早已经有现成的模型和 demo。比如 Google 上线的交互钢琴 A.I. Duet,人们只需弹奏少量音符,AI 就能据此弹奏出风格协调的曲子;而 OpenAI 的 Jukebox 能在人们给定旋律开头和歌词内容后,生成歌曲。
 A.I. Duet丨Google
A.I. Duet丨Google这里不得不提史上第一位被认证的 AI 作曲家——Aiva,Aiva 学习了由莫扎特、贝多芬等名家谱写的 15000 首曲子,利用深度学习搭建出了模型,然后作出原创曲子。自 2016 年诞生,Aiva 迅速得到商用,广泛用于网络视频的自动配乐,还出了 5 张专辑。
但我不打算用这些现成系统去生成音乐,我想借助更基础的论文和工具,从理解机器是如何“听懂”音乐开始,到把音乐解构成最小单位的数字、选定最合适的模型,再到训练 AI 生成像模像样的音乐,都自己摸索。这样才够“程序员”。
但没想到的是,这一摸索就花了八个月。但这次舍近求远的尝试,也让我明白:在巨大的参数量和人类的模型设计面前,艺术的美虽然不可被量化,但却有迹可循。
为了让机器听懂,首先得解构音乐
AI 是机器,它只能读懂数字。因此第一步就要在音乐与数字之间建立桥梁。我想到了 MIDI(乐器数字化接口)。MIDI 所存储的实际只是一组指令,告诉键盘、贝斯、架子鼓等在某个时间以怎样的方式发声。MIDI 存储了设备,时间与音符之间各自的对应关系。
 图源 Unsplash
图源 Unsplash说得再简单点,MIDI 就像是《节奏大师》游戏飞过来的那些小方块。
我最终使用的数据源叫 Pop17k,由台湾人工智慧实验室开源,它包含了 1700 首 MIDI 钢琴音乐。我也尝试过自制爵士乐的数据源,即通过转录(transcript)技术将大量爵士乐纯音频转换成 MIDI,但发现生成的 MIDI 文件会有个别错音,因此仍需要一次人工校正,工作量太大,所以放弃,选用开源数据源。
MIDI 虽然已经将音乐转换成二进制的数字,但想让 AI 精细化地学习音乐,仍要将 MIDI 做进一步的解构,即将旋律拆解成音高、音长、音强、和弦、小节等基本元素(音高是指声音的频率,音长则是一个声音持续的时间。显然,没有说一个时刻只能有一个音符,因此就有了和弦),并与数字建立映射的关系。
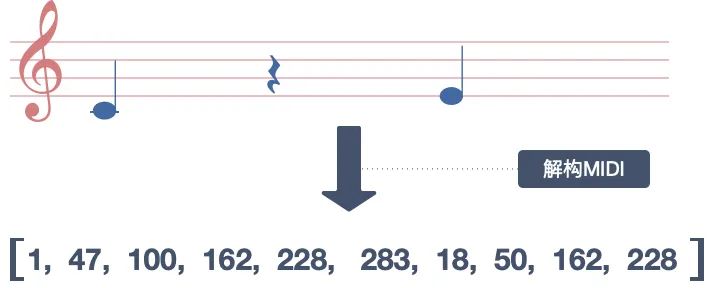 解构 MIDI丨作者制图
解构 MIDI丨作者制图我之前用 AI 做文字翻译时,涉及过单词的解构,当时用到的技术点叫做 Word Tokenize,即是把单词解构成最基本的词根与字母,通过让 AI 学习,就能找到语句与词根间的隐秘关系,甚至能生成训练集之外的新单词。那么,是否存在 MIDI Tokenize 方案呢?
我尝试搜寻“MIDI Tokenize”,老天眷顾,我找到了一套刚发布一周的开源 MIDI Tokenize 方案“MidiTok”,是索邦大学的一名叫 Natooz 的博士生做的。
 有了这个项目的支持,解构 MIDI 便水到渠成了,这时拆解一首曲子,就如同把玩具拆成最基本的乐高积木,将这些乐高积木与数字一一映射,最终就得到了一串数字序列,这就是 AI 能听懂的音符了。
有了这个项目的支持,解构 MIDI 便水到渠成了,这时拆解一首曲子,就如同把玩具拆成最基本的乐高积木,将这些乐高积木与数字一一映射,最终就得到了一串数字序列,这就是 AI 能听懂的音符了。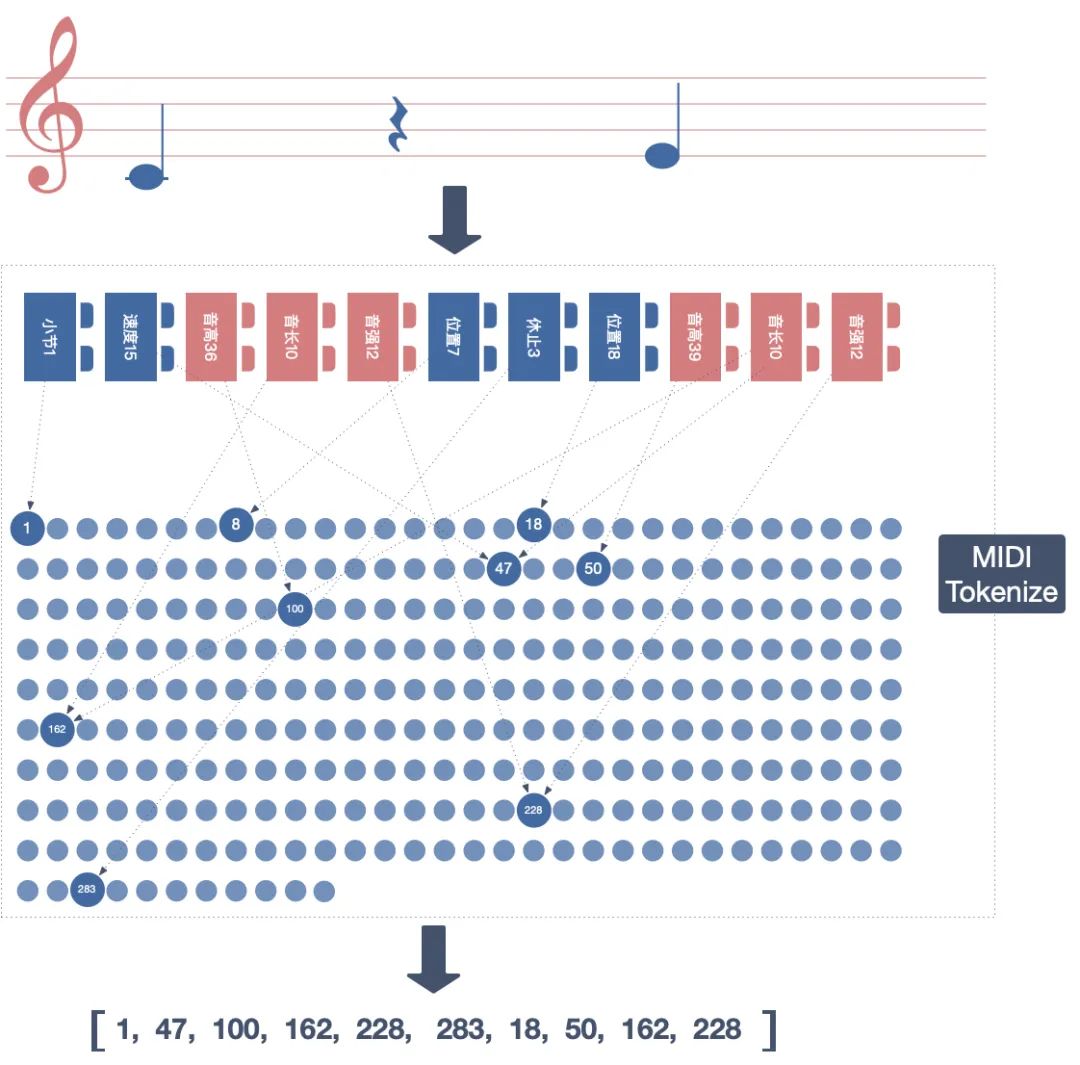 MIDI Tokenize丨作者制图
MIDI Tokenize丨作者制图不期而遇的模型,让 AI 理解音乐
拿到了音符对应的数字,是个好彩头。但接下来的才是真正的挑战——要让 AI 在连绵不绝的数字中寻找规律。模型架构决定了 AI 的学习能力,即合适的模型能有效地抓住音符间的关系,从而预测出下一个音符的概率。
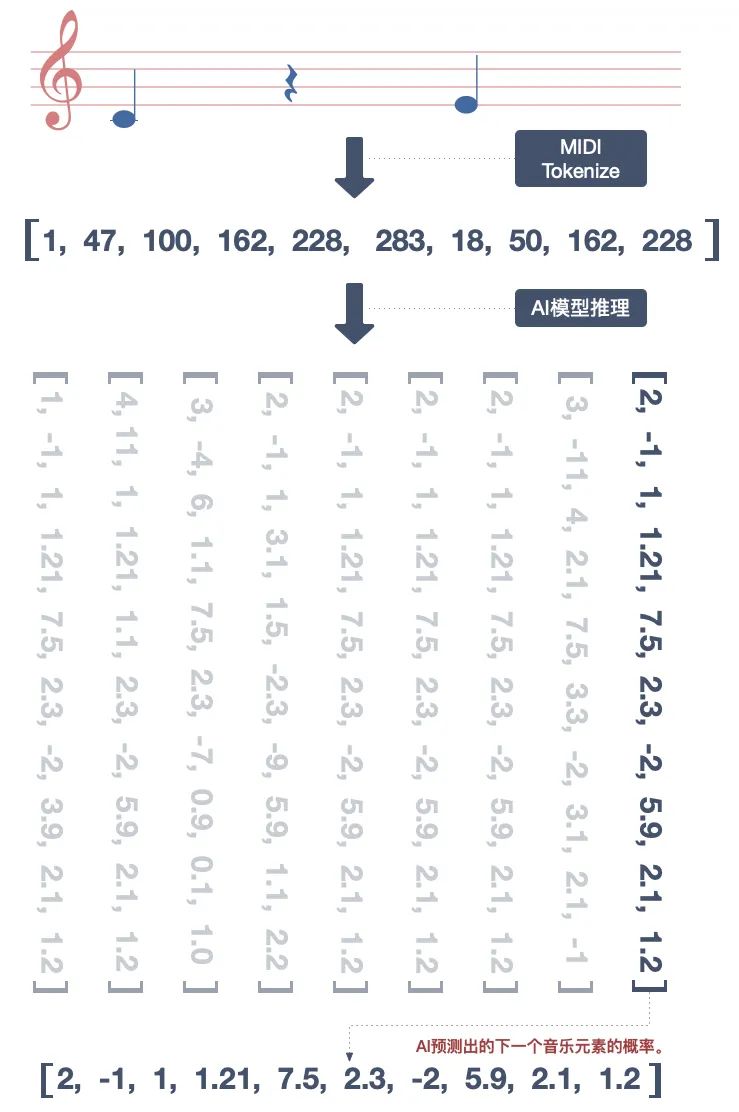 模型推理丨作者制图
模型推理丨作者制图我的切入点是,按照之前做 AI 文字翻译的方式来做音乐生成。两者区别不大,前者是生成文字,后者是生成音符。这种文字生成类的模型,其关键技术点就是注意力(Attention)机制。
注意力机制源于对生物行为的模仿,即用算法模仿了生物观测行为的内部过程,依据外在刺激与内在经验,增强局部的观测精度。就好比人类在集中观测某个具象物体时,无关的画面会自动模糊。
 经过一段时间的实践发现,注意力机制确实能有效地抓到音符的规律,也生成了一些简单的旋律。但却遇到了一个问题,即单纯的注意力机制无法有效在较长的音乐序列中抓到规律,结果只能输出 20~30 秒的旋律,时长增加就会“糊掉”。
经过一段时间的实践发现,注意力机制确实能有效地抓到音符的规律,也生成了一些简单的旋律。但却遇到了一个问题,即单纯的注意力机制无法有效在较长的音乐序列中抓到规律,结果只能输出 20~30 秒的旋律,时长增加就会“糊掉”。一番查阅后,我发现解决方案就藏在一篇论文中,也就是 Google Megenta 团队发布的论文 Music Transformer。论文提到了将注意力机制应用于音乐,并指出音乐序列不同于传统的文字序列,音符的序列所对应的是旋律,而旋律具有周期性与规律性。因此,注意力机制必须将音符之间的相对位置信息纳入考量,即 Relative Attention(相对位置的注意力机制)。
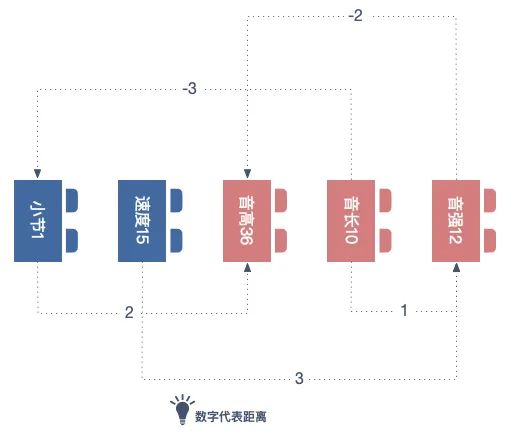 相对位置的注意力机制丨作者制图
相对位置的注意力机制丨作者制图有了理论支撑,我便开始着手实现 Relative Attention。但就是在这个过程中,我却意外地发现了 Compond Word Transformer。这是台湾人工智慧实验室于 2021 年初新发布的论文。
Compond Word Transformer 建立在 Music Transformer 之上,因此更加先进。Music Transformer 是将所有的音乐元素按照时间顺序排成一个有序队列作为输入。
 Music Transformer 的数据输入方式丨作者制图
Music Transformer 的数据输入方式丨作者制图而 Compond Word Transformer 则通过线性变换技巧,将原本的串行输入变换成为并行输入。
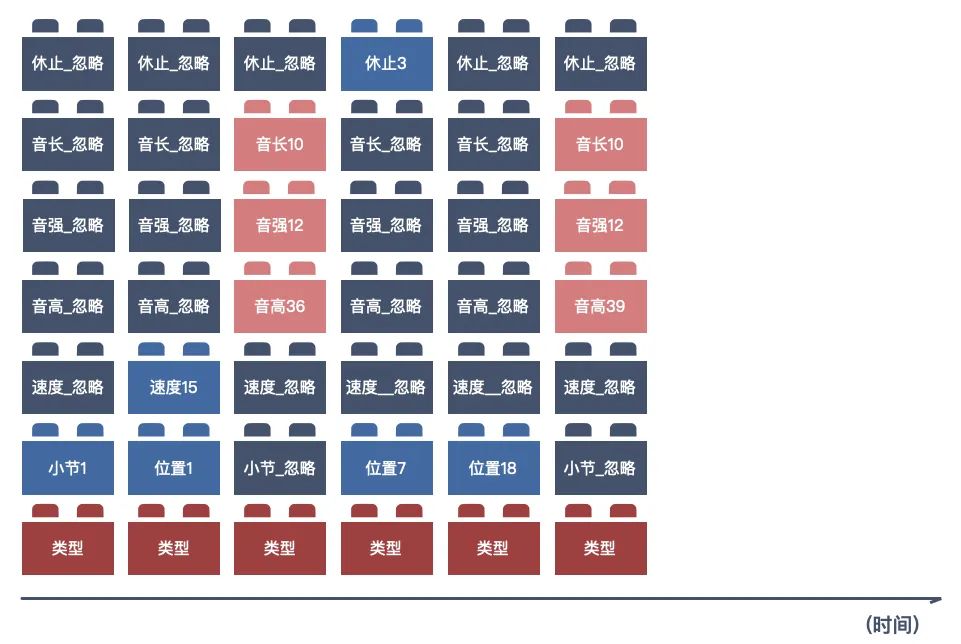 Compond Word Transformer 的数据输入方式丨作者制图
Compond Word Transformer 的数据输入方式丨作者制图如此一来,不但解决了时长增加就“糊掉”的问题,同时模型的训练和采样也更加高效灵活了。
最终,我用 Tensorflow 实现了 Compond Word Transformer,并开源在 GitHub。
训练费用花了 10000 块
要生成好的音乐,就离不开合理的训练与采样。
训练是模型不断学习成长的过程,模型在学习数据的过程中不断自我调整参数,让模型的输出效果在一定范围内接近训练数据,而模型的体量、训练的并发数(batch_size)与模型自我调节的次数(step)等都会对最终的效果产生影响。
于是,我反复调整模型与训练参数,并且尝试不同条件之下的单 GPU 训练和多 GPU 合作式的分布式训练。
这个过程大概持续了三个月,在 GPU 租赁平台花了 10000 元,最终才找到一套最佳实践的方案,当时确实走了不少“弯路”。
 模型的详细参数不过多赘述,代码中已经说明,我来说说模型自我调节的次数(step)对生成音乐效果的影响。在训练时,模型每学习一次数据之后,都会自我调整参数来使自己的输出更加接近数据集,这样一次模型自我调节的过程就叫一个 step。随着 step 的次数增多,模型会与数据集逐步拟合,生成的音乐效果也会大相径庭。比如让 AI 对同一段旋律(来自 Pop17k 数据源)进行续作。
模型的详细参数不过多赘述,代码中已经说明,我来说说模型自我调节的次数(step)对生成音乐效果的影响。在训练时,模型每学习一次数据之后,都会自我调整参数来使自己的输出更加接近数据集,这样一次模型自我调节的过程就叫一个 step。随着 step 的次数增多,模型会与数据集逐步拟合,生成的音乐效果也会大相径庭。比如让 AI 对同一段旋律(来自 Pop17k 数据源)进行续作。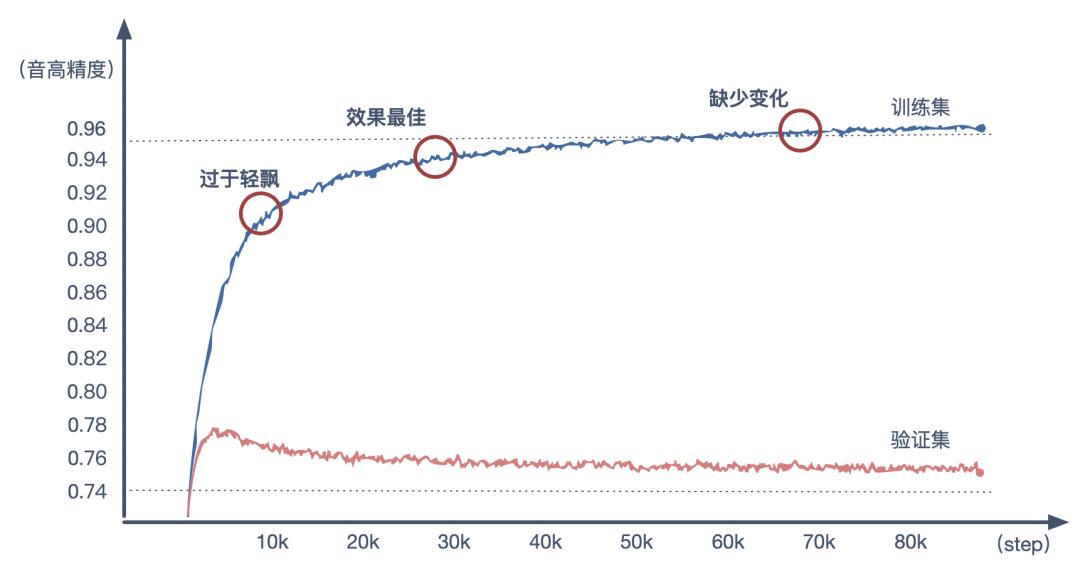 训练折线图丨作者制图
训练折线图丨作者制图对于绝大多数 AI 模型来说,验证集达到最高精度之时,模型的表现往往最佳。但在生成音乐这里却不是这样。我在反复实验后发现,能生成流畅自然旋律的那套参数,往往发生在验证集达到最高精度之后。
这或许恰恰说明理性数字所标记的精度,只能表达模型对于训练集的拟合程度,不能 100% 标记感性音乐的动听程度,音乐感受是因人而异的主观体验。
好的采样策略,旋律的把控更灵活
我拿到了一个训练完成的模型,但却未必能得到好听的旋律。因为 AI 模型最终给出的结果是数字,是概率分布。我还需要用合理的算法,将概率分布转换成最终与音符对应的那个数字。这个过程叫做“采样”。
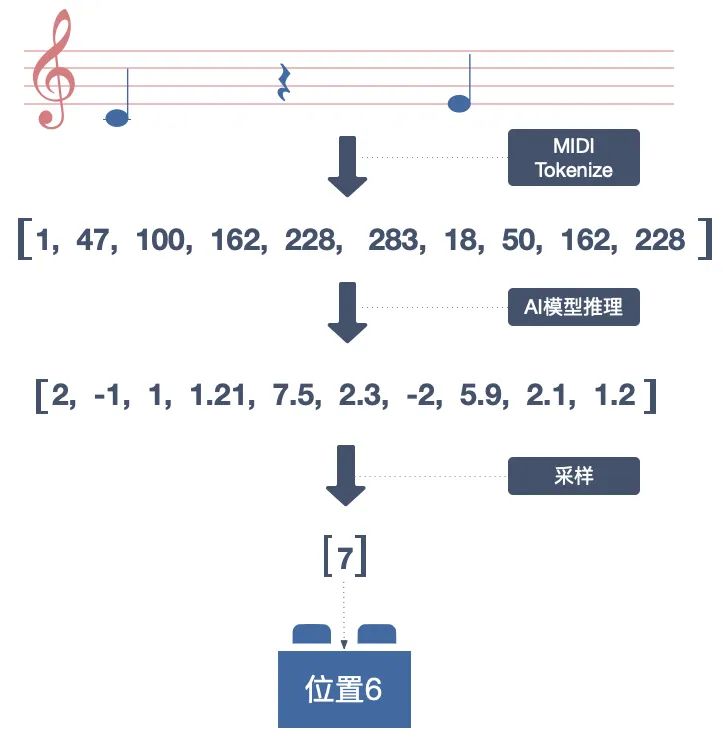 我的第一直觉是直接使用 Greedy Search(只选择概率最大的)。可在实际的测试中发现这并不可行,因为在实际的测试中发现,Greedy Search 会导致音乐缺少变化,甚至陷入一种永不回转的单调,也叫做“Get Stuck In Loops”现象。
我的第一直觉是直接使用 Greedy Search(只选择概率最大的)。可在实际的测试中发现这并不可行,因为在实际的测试中发现,Greedy Search 会导致音乐缺少变化,甚至陷入一种永不回转的单调,也叫做“Get Stuck In Loops”现象。 我需要一种方案让生成的旋律在采样后具有一定变化。这里我结合了之前用 AI 做文字生成的一些经验,我选择的是 TOP-P Sampling 与 Temperature Sampling 结合的算法。
我需要一种方案让生成的旋律在采样后具有一定变化。这里我结合了之前用 AI 做文字生成的一些经验,我选择的是 TOP-P Sampling 与 Temperature Sampling 结合的算法。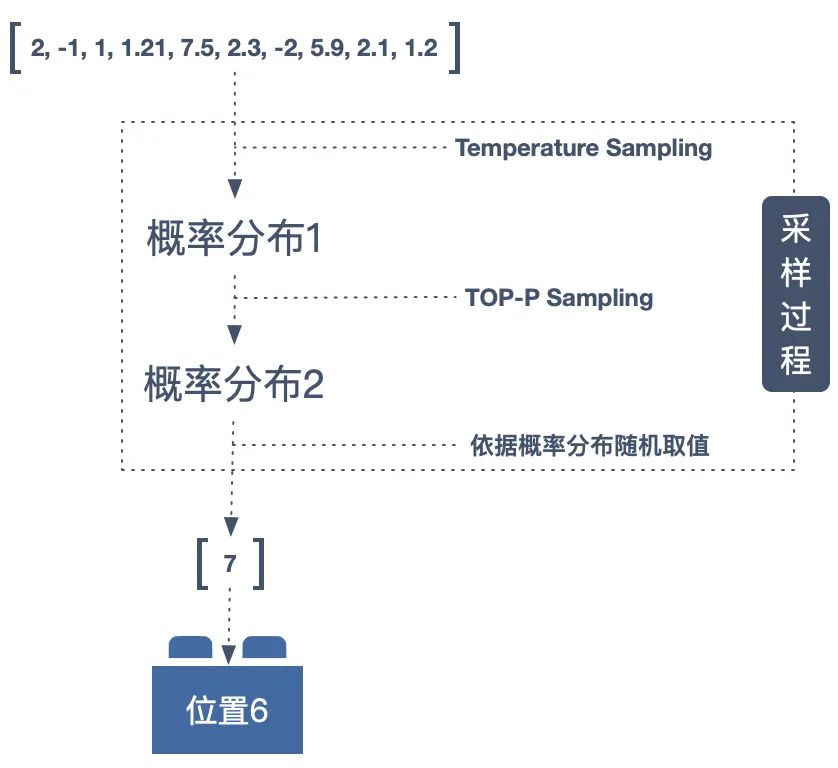 TOP-P Sampling 的核心是可以甩掉末尾的小概率,可通过设置参数 P 来配置候选者的数量,P 的值越大则参选的候选者越少。Temperature Sampling 则给了我一个可调节的“温度”参数,即可通过调整温度 T 来把控旋律的变化幅度。
TOP-P Sampling 的核心是可以甩掉末尾的小概率,可通过设置参数 P 来配置候选者的数量,P 的值越大则参选的候选者越少。Temperature Sampling 则给了我一个可调节的“温度”参数,即可通过调整温度 T 来把控旋律的变化幅度。比如以下两首是为相同开头续作,对比“T-音高”不同的旋律。

 第一首(T-音高 = 0.01)的音高会保持较好的前后一致性。而第二首(T-音高 = 1)的旋律则相对有了更加灵动多变的感觉。这精细独立的把控得益于 Compond Word Transformer 的模型架构,可将不同的音乐元素分别进行独立采样,十分灵活高效。
第一首(T-音高 = 0.01)的音高会保持较好的前后一致性。而第二首(T-音高 = 1)的旋律则相对有了更加灵动多变的感觉。这精细独立的把控得益于 Compond Word Transformer 的模型架构,可将不同的音乐元素分别进行独立采样,十分灵活高效。AI 创作的旋律诞生了
时间过得很快,八个月了,我如愿以偿用程序员的方式创作出了几段旋律。
这八个月的 AI 作曲之路就像一次舍近求远的旅行,我本可以直接使用现成可用的系统去生成音乐,比如 MusicRNN,Jukebox 等。但我选择了从零到一亲自实践,这一路的疲惫与充实,茫然与灵感,失落与成长,让我在抵达终点后仍感觉到一丝意犹未尽。因为探索的乐趣并非来自最终的结果,而是源自于探索本身。
人类文明发展至今,已拥有八大艺术。而技术与艺术结合的则是一个广阔的新领域。新领域也意味着新问题与新挑战。
比如 AI 创作的艺术作品,版权归属于谁?由于 AI 音乐的产生是根据算法模型,让机器在大量现成作品中寻求“规律”,按照这些规律提取资料中特定的乐章片段,依据计算得出的概率重新进行排列组合,所以这些涉及到资料库中大量现成作品的版权问题。据说,Aiva 研发人员特意选择古典音乐为 AI 学习对象,主要就是为了避免版权问题,因为它所使用的莫扎特、贝多芬等人的作品历史久远,版权时效已过。即便 AI 作曲技术经过不断优化,最终得以生产出纯原创、不涉及任何侵权的作品,此作品又将面临到版权认证的问题。
再比如当下 AI 的艺术作品往往被评价缺少“灵魂”,人们认为 AI 不具备情感,不了解音符、节奏等音乐表层结构和基于情绪表达的音乐深层逻辑之间的对应关系,只是在“猜”音符。那人类做出的音乐的“灵魂”又是什么呢?
我认为艺术的“灵魂”一定与一个现象有关。那就是联觉(Synesthesia)现象。
联觉,又称通感,是指一种通道的刺激同时引起的另一种通道的感觉。比如蓝色容易使人产生冷静或忧伤的感觉, 而音乐作曲中也往往会使用大调或小调来传达明亮或阴郁的感受。
出众的联觉感受是艺术家的一种天赋。《权力的游戏》的主题曲作者拉民·贾瓦迪,就有出众的联觉感受。他能在音乐中看到颜色,在文字中听见旋律。将这些不同通道的感受串联起来的,似乎是一种神秘力量,只是我们还没将它发现。
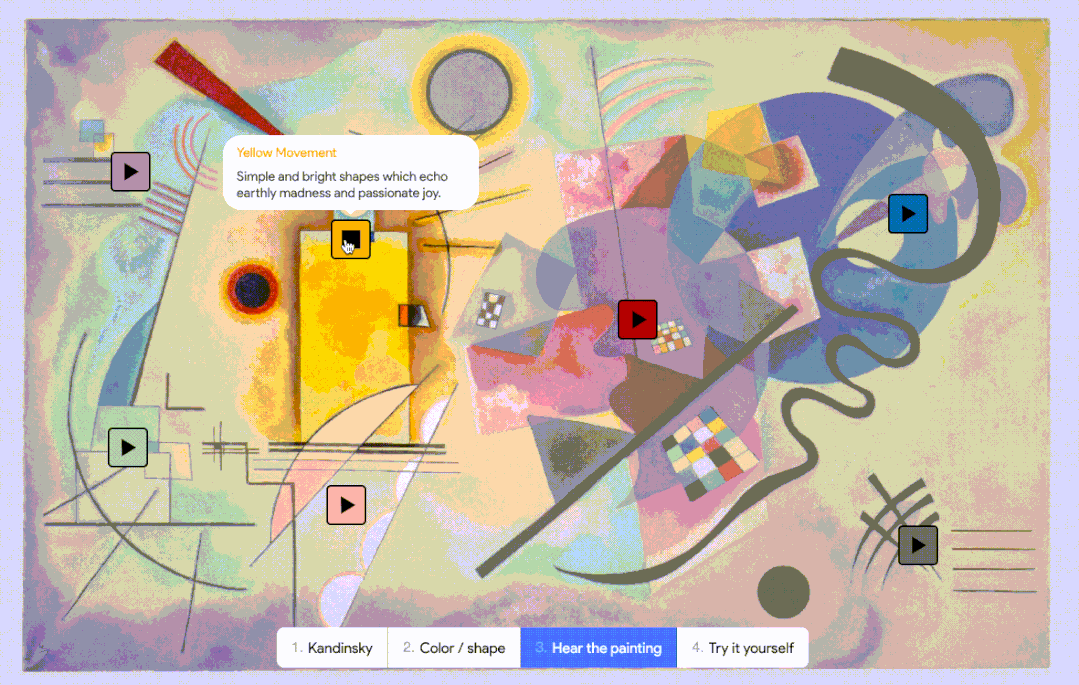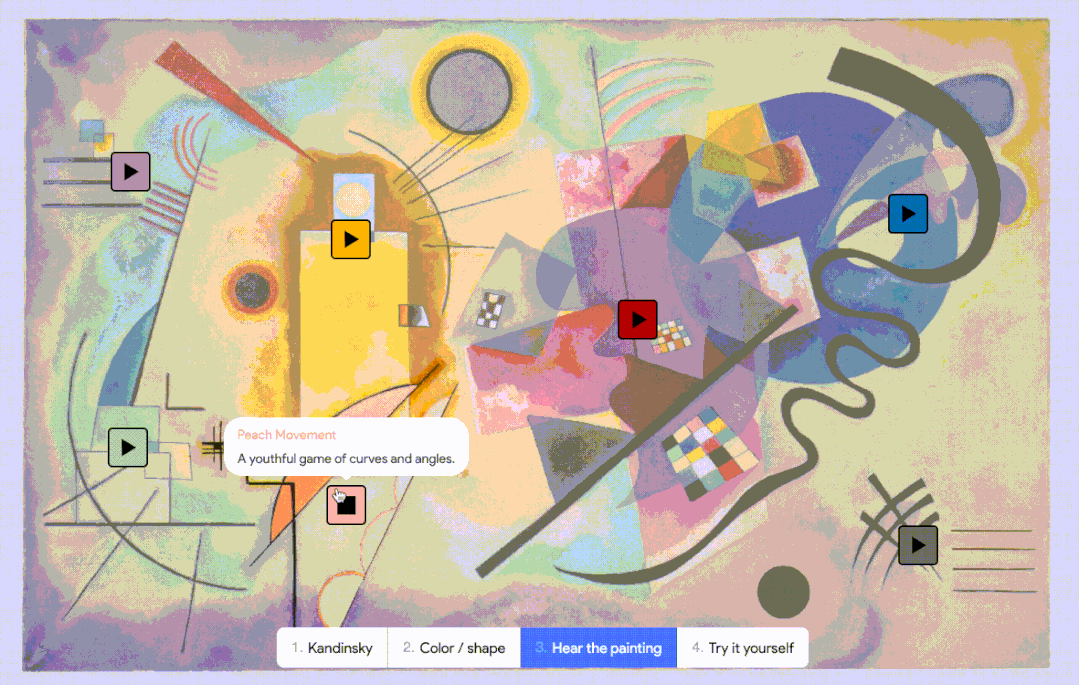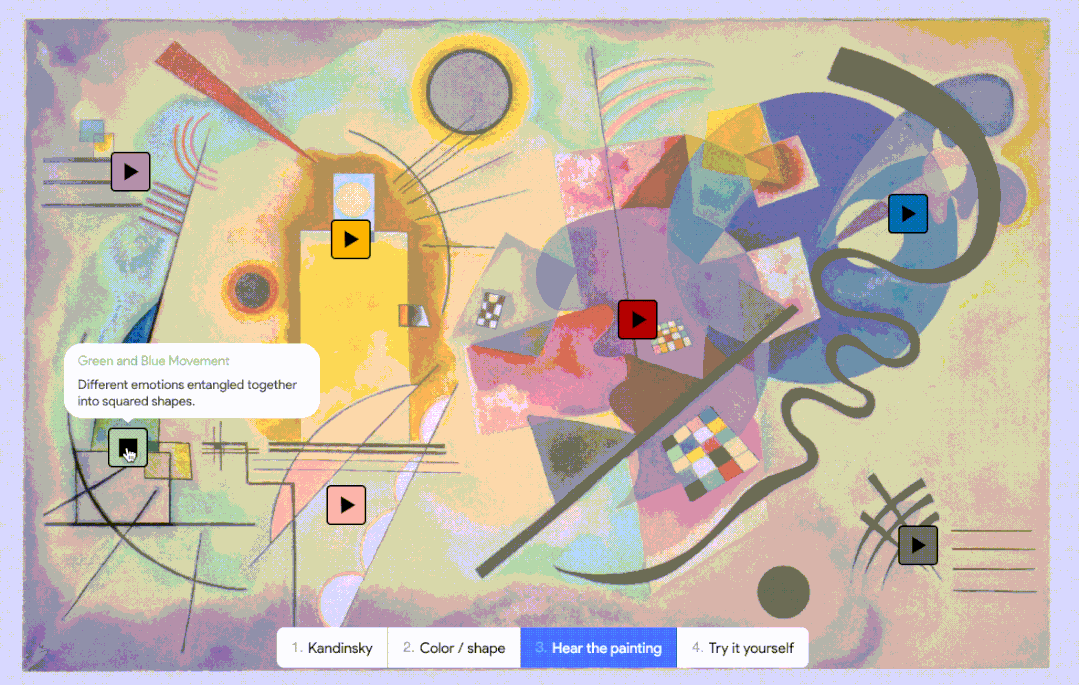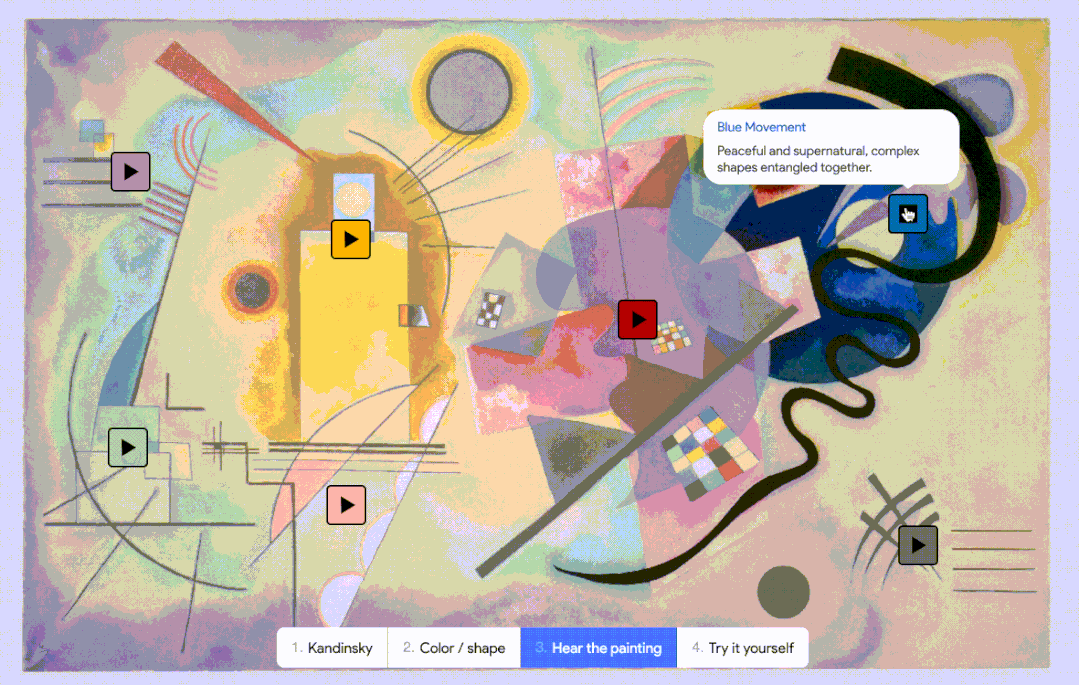 而 AI 对联觉的探索也已上路,Google 也曾在 2021 年发布过一个模拟联觉感受的实验性 AI,叫做 Play a Kandinsky丨Google Arts & Culture
而 AI 对联觉的探索也已上路,Google 也曾在 2021 年发布过一个模拟联觉感受的实验性 AI,叫做 Play a Kandinsky丨Google Arts & Culture相反,AI 没有意识,不存在任何对音乐的“理解”,只是在数字中寻找规律,并按照它掌握的规律,一个接一个地推测出接下来的音符。但在一些注重成本且审美要求不高的应用场景中,AI 作曲就是一个高效的选择。
一些前沿科技团队也清楚 AI 作曲的斤两,所以他们在研究由 AI 百分百作曲的同时,也在做一些人机交互,是把 AI 作为作曲的一种协同工具,比如 Google Magenta 团队开发的 COCOCO,就是帮助作曲家寻找灵感的工具。
AI 作曲的存在,也不断在提醒蹩脚的作曲家们不能再做简单又粗糙的音乐,而应该珍视、钻研音乐这一个表达媒介。至少,你作品里寄托的情感,不能还没有机器猜音符那种概率游戏真诚吧?
参考文献
[0]源码:https://github.com/netpi/compound-word-transformer-tensorflow
[1] MT3: https://arxiv.org/abs/2111.03017
[2] REMI: https://arxiv.org/abs/2002.00212
[3] Attention: https://arxiv.org/abs/1706.03762
[4] Music-Transfomer: https://arxiv.org/abs/1809.04281
[5] CP-Word-Transfomer: https://arxiv.org/abs/2101.02402
作者:陈东泽
原标题:《我花了八个月和一万块,用 AI 做了毫无灵魂的音乐》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

