- +1
图像特征与自然语言特征的融合
撰稿人 | 徐涛(河南科技学院 讲师)
图像修复(名词解释>),是指将因遮挡、模糊、传输干扰等各种因素造成信息缺失或损坏的图片,利用图像缺失部分邻域的信息和图像整体的结构信息等,并按照一定的信息复原技术对图像的缺失或损坏的区域进行修复。因其具有的独特功能,目前已被应用到许多图像处理的场景中,例如删除图像中不需要的物体,去除目标物上的遮挡物体,修复损坏等任务。
然而传统修复模型存在当目标特征严重缺失时现有图像修复方法未能利用完整区域预测缺失区域特征,造成修复结果特征不连续、细节纹理模糊等问题。
针对这一问题,有研究人员利用深度学习和GAN策略实现残缺图像的修复,提出了基于精细化深度学习的图像修复模型。该方法采用一种新的连贯语义层,并通过连贯语义层保留上下文语义情景结构,使其推测出来的残缺部分更加合理。然而面对特征信息不足的残缺图像时,现有修复模型就会呈现出不能有效修复或修复效果精细纹理缺失的现象。
为解决这一问题,河南科技学院徐涛团队提出一种基于场内外特征(EFIF)融合的残缺图像精细修复方法,该方法融合图像特征和场外知识特征实现残缺图像的修复。
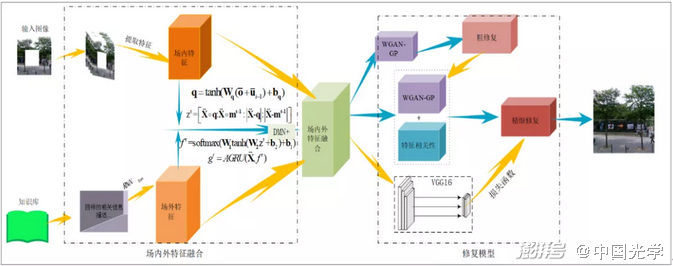
图1:场内外特征融合的残缺图像精细修复模型框架
其成果以“场内外特征融合的残缺图像精细修复方法”发表在《光学 精密工程》。
在这项工作中,根据目标要求将设计步骤分为了以下三步:
1. 常识性知识的检索和嵌入
通过检测图像背景中存在的目标,根据知识库中相应的常识性知识,推测出与目标具有高度相关性的目标集合,并对检测到的背景目标常识性知识进行编码映射到一个连续的向量空间,构成场外特征。
2. 特征融合
本文通过改进的DMN+算法实现基于情景问答的场外知识检索,获取最具相关性的待修复目标特征描述。通过对上下文的学习,使提取到的特征之间进行信息交互,以获取更多的与目标信息相关的场外特征信息,更有利于实现图像的修复。
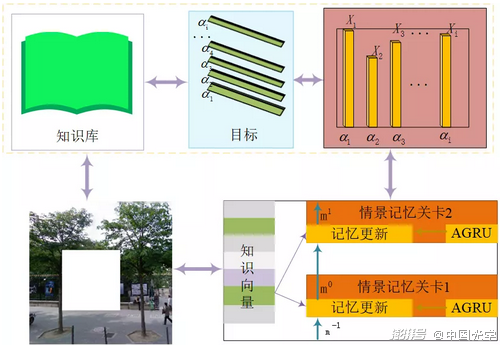
图2:场外特征的检索与获取
3. 修复模型构建
残缺图像精细修复模型由三部分网络构成,即:场内外特征融合网络,粗修复网络和精细修复网络。将信息残缺的图像输入到场内外特征融合网络,得到一个特征信息更加丰富的输出结果,并将其输入到粗修复网络,获取粗修复图像。将待修复的图像和粗修复图像同时输入精细修复网络,通过提取叠加区域的有效特征信息,生成最终的精细修复图像,从而实现对残缺图像的精细修复。
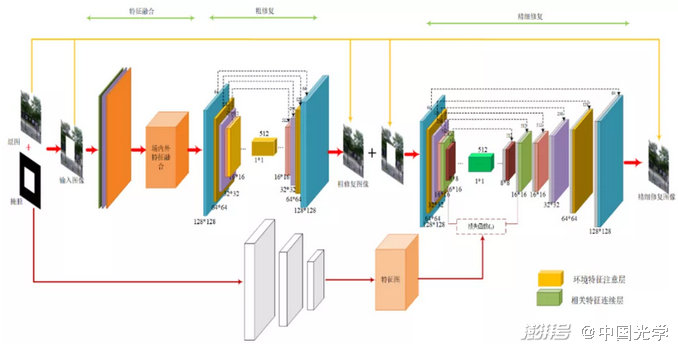
图3:残缺图像精细修复方法的网络模型
在三个复杂程度不同的数据集中对本文所提算法进行实验验证如图4~图6所示。本算法在视觉定性对比和客观定量两方面均优于现有对比修复模型。该模型的修复结果在视觉定性对比和客观定量两方面均优于现有SH[1],GLCI[2],CSA[3]三个对比修复模型,PSNR值最高为35.98,SSIM值最高为0.983。

图4:现有修复模型与本文修复模型在Place2数据集中比较,从右到左依次为输入图像,SH、GLCI、CSA、粗修复、EFIF,及原图

图5:现有修复模型与本文修复模型在RUIE数据集中比较,从右到左依次为输入图像,SH、GLCI、CSA、粗修复、EFIF,及原图

图6:现有修复模型与本文修复模型在Underwater Target数据集中比较,从右到左依次为输入图像,SH、GLCI、CSA、粗修复、EFIF,及原图
该研究成果所提算法可删除图像中不需要的物体,去除目标物上的遮挡物体,可用于自动驾驶提高对环境的理解能力,同时,算法对残缺图像有较好的修复效果,可推广应用于残缺文物的数字化修复工作。
论文信息:
徐涛,周纪勇,张国梁等.场内外特征融合的残缺图像精细修复[J].光学精密工程,2021,29(10):2481-2494.
DOI:10.37188/OPE.20212910.2481
作者信息:

徐涛,博士,讲师,硕士研究生导师,2017年于北京工业大学获得博士学位,主要从事智能机器人环境感知、机器视觉等方面的研究。E-mail: xutao@hist.edu.cn

周纪勇,硕士研究生,2019年于绥化学院获得学士学位,现于河南科技学院攻读硕士研究生,研究方向:图像处理。E-mail: zhoujiyong2020@126.com
参考文献:
[1] ZHAOYI Y, XIAOMING L, MU L, et al. Shift-Net: image inpainting via deep feature rearrangement [C]. Proceedings of the European Conference on Computer Vision, Munich, Germany, ECCV, 2018: 3-19.
[2] IIZUKA S, SIMO-SERRA E, ISHIKAWA H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics, 2017, 36(4):1-14.
[3] LIU H Y, JIANG B, XIAO Y,et al. Coherent semantic attention for image inpainting[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV). October 27 - November 2, 2019, Seoul, Korea (South). IEEE, 2019:4169-4178
监制 | 袁境泽、臧春秀、赵阳
编辑 | 赵唯
欢迎课题组投稿——新闻稿
转载/合作/课题组投稿,微信:447882024
带您每天读1篇文献!加入>Light读书会
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

