- +1
语言模型做起目标检测,性能还比DETR、Faster R-CNN更好
博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
长期以来,CNN都是解决目标检测任务的经典方法。
就算是引入了Transformer的DETR,也是结合CNN来预测最终的检测结果的。
但现在,Geoffrey Hinton带领谷歌大脑团队提出的新框架Pix2Seq,可以完全用语言建模的方法来完成目标检测。

团队由图像像素得到一种对目标对象的“描述”,并将其作为语言建模任务的输入。然后让模型去学习并掌握这种“语言”,从而得到有用的目标表示。
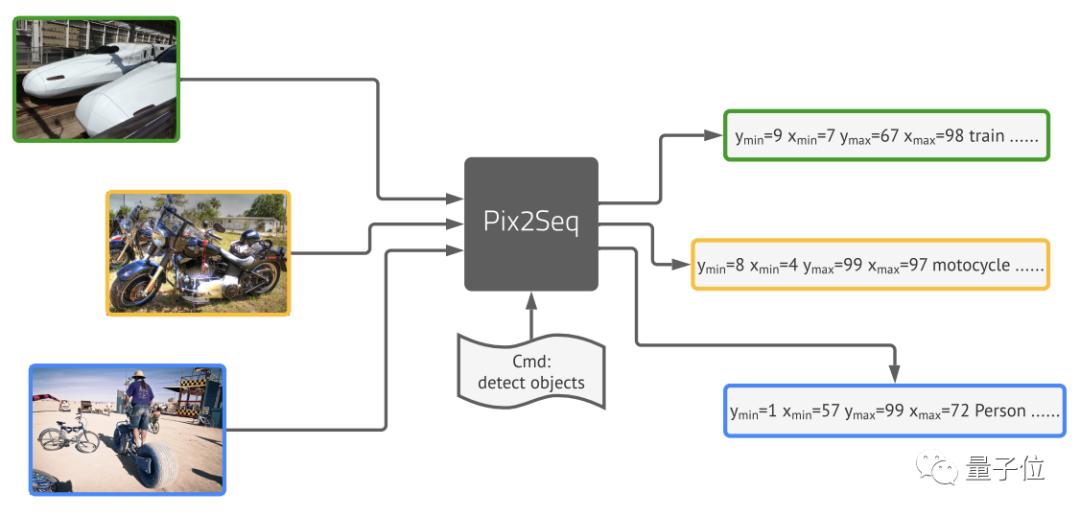
最后取得的结果基本与Faster R-CNN、DETR相当,对于小型物体的检测优于DETR,在大型物体检测上的表现也比Faster R-CNN更好,。
接下来就来具体看看这一模型的架构。
从物体描述中构建序列
Pix2Seq的处理流程主要分为四个部分:
图像增强
序列的构建和增强
编码器-解码器架构
目标/损失函数
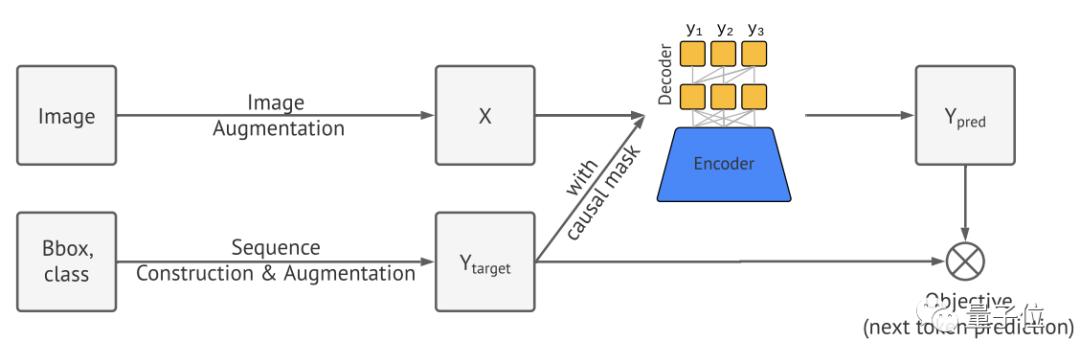
首先,Pix2Seq使用图像增强来丰富一组固定的训练实例。
然后是从物体描述中构建序列。
一张图像中常常包含多个对象目标,每个目标可以视作边界框和类别标签的集合。
将这些对象目标的边界框和类别标签表达为离散序列,并采用随机排序策略将多个物体排序,最后就能形成一张特定图像的单一序列。
也就是开头所提到的对“描述”目标对象的特殊语言。
其中,类标签可以自然表达为离散标记。
边界框则是将左上角和右下角的两个角点的X,Y坐标,以及类别索引c进行连续数字离散化,最终得到五个离散Token序列:
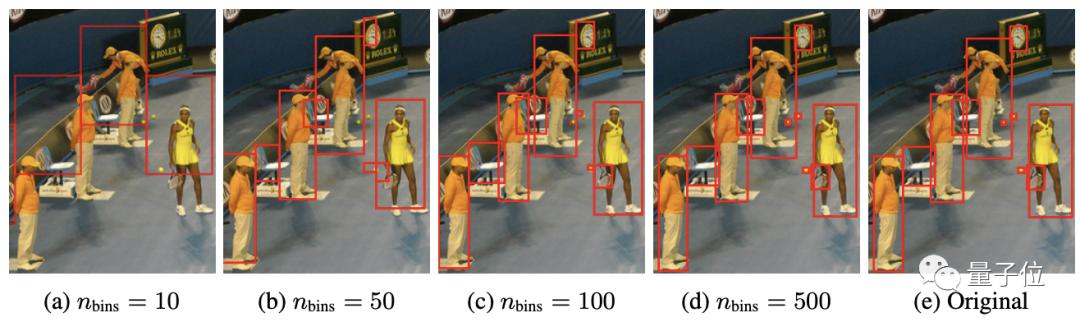
研究团队对所有目标采用共享词表,这时表大小=bins数+类别数。
这种量化机制使得一个600×600的图像仅需600bins即可达到零量化误差,远小于32K词表的语言模型。
接下来,将生成的序列视为一种语言,然后引入语言建模中的通用框架和目标函数。
这里使用编码器-解码器架构,其中编码器用于感知像素并将其编码为隐藏表征的一般图像,生成则使用Transformer解码器。
和语言建模类似,Pix2Seq将用于预测并给定图像与之前的Token,以及最大化似然损失。
在推理阶段,再从模型中进行Token采样。
为了防止模型在没有预测到所有物体时就已经结束,同时平衡精确性(AP)与召回率(AR),团队引入了一种序列增强技术:
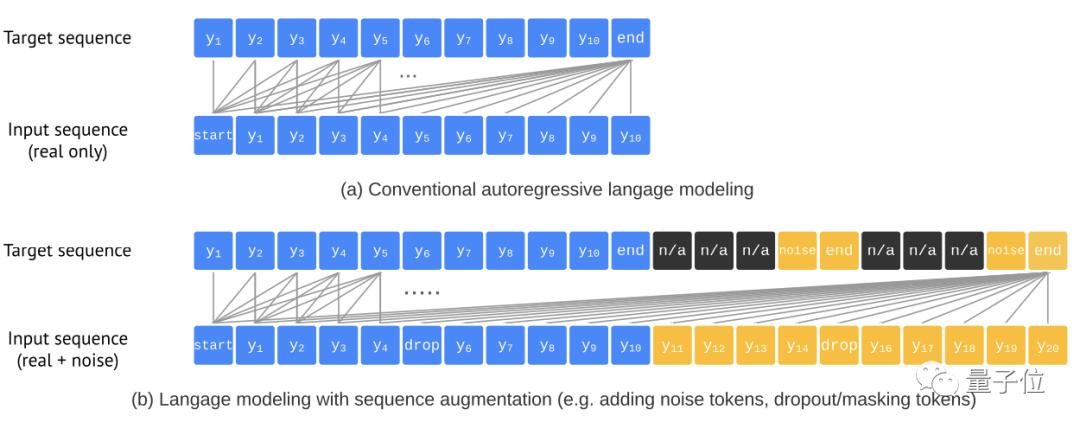
这种方法能够对输入序列进行增广,同时还对目标序列进行修改使其能辨别噪声Token,有效提升了模型的鲁棒性。
在小目标检测上优于DETR
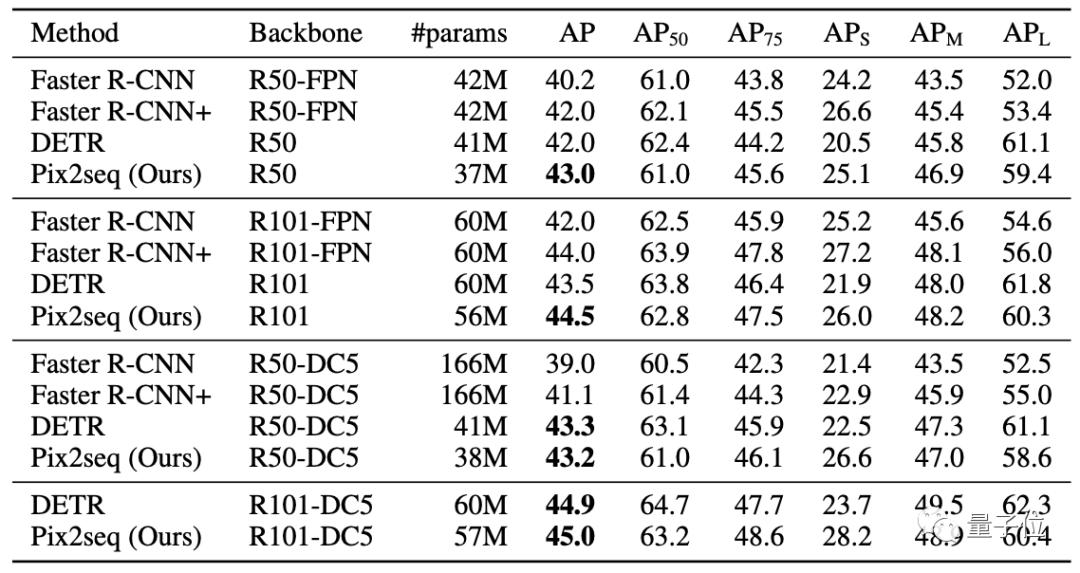
团队选用MS-COCO 2017检测数据集进行评估,这一数据集中含有包含11.8万训练图像和5千验证图像。
与DETR、Faster R-CNN等知名目标检测框架对比可以看到:
Pix2Seq在小/中目标检测方面与Faster R-CNN性能相当,但在大目标检测方面更优。
而对比DETR,Pix2Seq在大/中目标检测方面相当或稍差,但在小目标检测方面更优。
一作华人
这篇论文来自图灵奖得主Geoffrey Hinton带领的谷歌大脑团队。
一作Ting Chen为华人,本科毕业于北京邮电大学,2019年获加州大学洛杉矶分校(UCLA)的计算机科学博士学位。
他已在谷歌大脑团队工作两年,目前的主要研究方向是自监督表征学习、有效的离散结构深层神经网络和生成建模。

论文:
https://arxiv.org/abs/2109.10852
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
原标题:《语言模型“不务正业”做起目标检测,性能还比DETR、Faster R-CNN更好 | Hinton团队研究》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

