- +1
智能体如何自己学会在多车环境下开车?研究还用了GTA5
如何在有其他车辆参与的环境中让智能体(agent)学会自动驾驶的策略?这是一个复杂的问题,涉及感知、控制和规划多个层面。
在今年西安举办的机器人领域顶级会议国际机器人和自动化会议(International Conference of Robotics and Automation, ICRA)上,来自于美国卡内基梅隆大学(曹金坤)、加州大学伯克利分校(Xin Wang, Trevor Darrell)和瑞士苏黎世联邦理工大学(Fisher Yu)的研究人员发表了题为《instance-aware predictive navigation in multi-agent environments》(多智能体环境下的实例预测导航)的研究。
研究提出实例感知预测控制( IPC,Instance-Aware Predictive Control)方法,强调在不添加任何的人为示范(Expert demonstration,常用于“模仿学习”中的策略优化)前提下,从无到有,完全通过强化学习中“探索-评估-学习”(explore-evaluate-learn)的路线进行策略的学习,提供了更好的可解释性和样本效率。
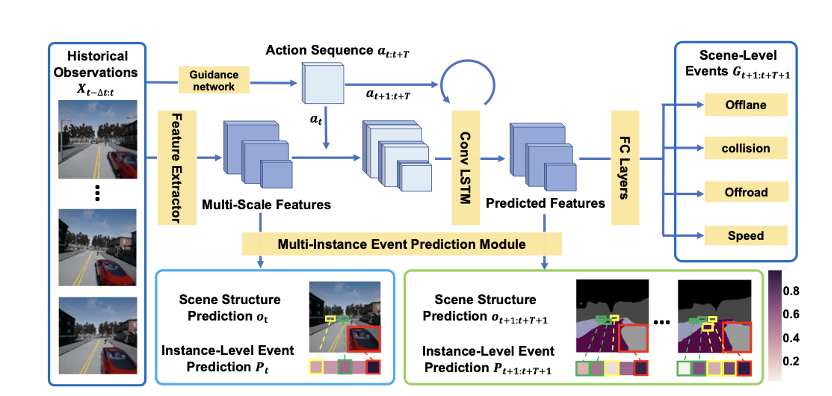
实例感知预测控制(IPC)框架。在给定历史观察情况下,引导网络(Guidance network)有助于在动作空间中对动作序列进行采样。该模型既预测未来的视觉结构,也包含某些事件的可能性。Observation是包含语义分割和实例(其他智能体车辆)位置的视觉观察。G是场景级事件。P是每个预测的可能实例位置上的实例级事件。事件预测给动作选择带来了参考。视觉结构预测为动作决策带来解释。右下角的颜色条表示实例级事件的概率。
强化学习方法:从无到有,无人为示范学会自动驾驶策略
在回答此研究的亮点之处时,论文第一作者、卡内基梅隆大学在读博士曹金坤对澎湃新闻(www.thepaper.cn)记者表示,“我们在具有挑战性的CARLA(Car Learning to Act,开源模拟器,可模拟真实的交通环境,行人行为,汽车传感器信号等)多智能体驾驶模拟环境中建立了无需人为示范(Expert demonstration)的算法框架,提供了更好的可解释性和样本效率。”
当前的自动驾驶的策略更多的基于规则(rule-based):通过人设计具体的策略来进行驾驶。也有很多学者基于“模仿学习”(imitation learning)的方法进行研究,即让车辆模仿人在不同的情况下的驾驶选择。
曹金坤表示,“这两种方法都有弊端,前者是人难免‘百密一疏’,有些具体的场景无法被规则很好地覆盖,或者在进行设置时很多衡量的指标都难以具有普遍性。后者的问题在于,车辆只能学习人类好的、安全场景下的驾驶策略,而一旦现实场景中的自动驾驶车辆进入了危险的、在学习时人没有作出示范的场景,它的策略就变成完全空白了。”
“而相比较这两个方法,强化学习(Reinforcement learning)因为基于车辆的探索,所以可以更普遍地让车辆尝试和探索到不同的场景,相较于前两种方法有其优势。而如果我们之后希望可以有大规模、更加健壮的自动驾驶策略开发的流水线(pipeline),这种基于探索的策略或许至少会有一种有益的补充。”
完成这个强化学习过程的一个重要基础就是数据采集,从视觉场景直接获得原始数据(如相机观察数据等)进行强化学习一直是一个困难的问题,这也导致了“基于原始数据”(raw-data-based)的强化学习要比“基于状态”(state-based,指智能体通过人为定义的干净的状态描述来进行策略的开发)的强化学习进展缓慢得多。
研究团队为了切合现实的自动驾驶策略的真实性要求,使用了基于原始数据的方法,并且只使用了车前的一个无深度摄像头的数据,没有使用任何的雷达设备。基于这个唯一的传感器,被控制的车辆会对场景中的其他车辆进行检测。

紧接着,通过采样的方法,智能体会选取多组动作序列的候选,并对不同的行动策略已经结果预测,判断采取这个策略在未来一段时间内可能造成的影响。基于这种对未来预测并检验的过程,智能体(agent)学习到正确的驾驶方式,模型预测控制才成为可能。
对未来的预测:“稀疏”与“稠密”的信号
在预测阶段,尽管理想地预测和驾驶相关的指标对于控制来说已经是足够的了,如和其他车辆碰撞的概率、车辆行驶到反向车道的概率等等。但是在完全基于车辆自身感知和复杂真实的物理环境中,这种非常简单的信号被认为是过于“稀疏”(sparse)的,无法支撑起复杂模型的训练所需的数据规模。
为了获取更加“稠密”的模型训练数据来源,研究者使用了计算机视觉中的“语义分割掩码”(semantic segmentation mask,即观察范围内不同类别物体的轮廓)来帮助训练。而此类人类可以理解的视觉数据又反过来帮助人们理解智能体所做的动作选择,比如在未来某时刻其预测有其他车辆会非常靠近自己的右侧,那么这时如果其输出的驾驶动作是向左倾斜也可以被理解了。
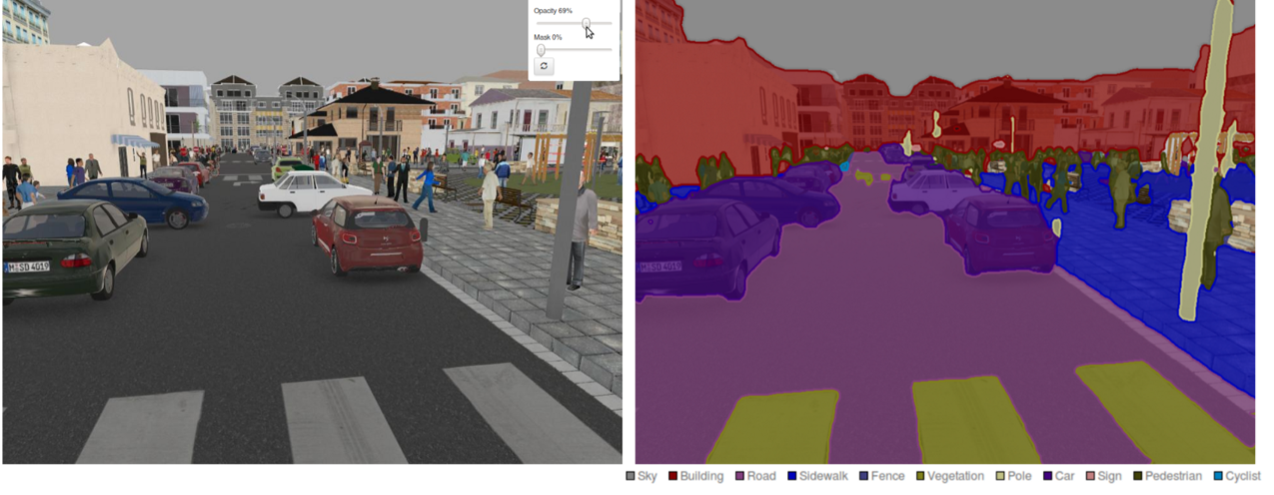
道路场景下的语义分割掩码示意图
所有前述的未来场景的视觉(车辆位置,语义分割掩码)和状态(碰撞几率、逆行的机会等)都被控制车辆在模拟器中行驶的同时收集下来,然后放在一个缓冲区(buffer)中。在驾驶收集数据的同时,这个智能体会从缓冲区中采样历史的驾驶记录,来进行视觉感知和状态预测模型的训练。整个模型的训练和策略演化都是完全在线(online)和无人为示范(demonstration-free)的,即在线的强化学习(online reinforcement learning)。
“让智能体在有其他车辆参与的环境中学会自动驾驶策略有两个部分,场景感知与预测,以及基于此的驾驶策略选择。在场景感知与预测中,一个是智能体对于周边的建筑、车道等静止的物体要做出非常精准的未来状态估计,另一个是对于其他的车辆的未来状态做出准确估计,后者要难得多,”曹金坤对澎湃新闻表示。
“因此,尽管在长久的训练后,智能体对于周边的建筑、车道等静止的物体可以做出非常精准的未来状态估计,但是对于其他的车辆的未来状态还是会非常的挠头,”曹金坤表示。
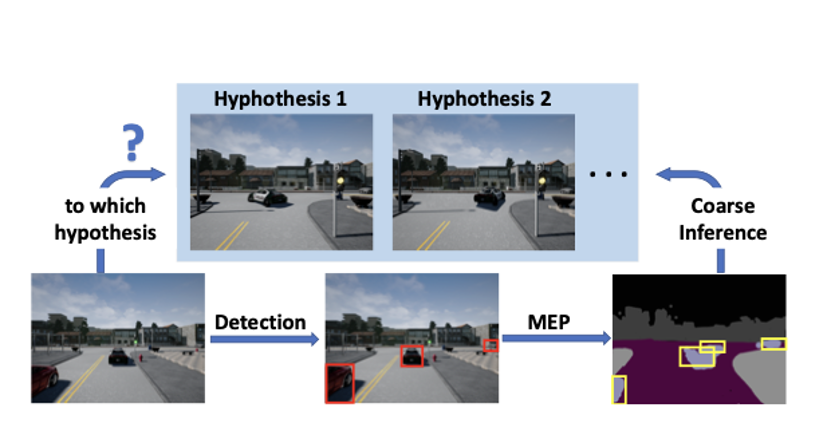
多实例事件预测(Multi-instance Event Prediction,MEP)中可能的实例位置的预测如何为不同的假设建立粗略的推理。
论文中提出,在驾驶中,其他车辆的策略是未知的,受控的智能体对他们的策略没有预先的感知,而且他们的动作也有一定的随机性,不是一个完全的“决定性”(deterministic)的动态过程(dynamic process),受控车辆面对的实际上是“多假设未来”(multi-hypothesis future),也就是说从现在的时间点出发,即使受控车辆一直采取一样的行动,未来的整个道路情况都依旧是不确定的。
“为了解决这个问题,我们设计去预测未来的状态分布,而不是单一可能。但是从根本上说,这种方法受限于模型的遗忘和从有限数据采样预测分布的困难等问题,做的还是不够好的,需要进一步的改进,”曹金坤反思道。
利用预测结果进行自动驾驶策略的选择
在拥有预测未来场景和车辆状态的能力之后,研究团队还需要解决驾驶动作的采样和评估问题。
研究团队对这两个阶段分别设计了解决方案。
第一个困难便是在连续的动作空间中进行采样(比如踩油门的力度和方向盘的角度都是连续的数字)。对此研究团队设计了一个“指导网络”(guidance network),其在连续的动作空间中首先进行离散化处理,通过当前和过去的场景观测在离散化后的空间中选择一个决策子区域,然后在这个选中的更小的动作区域中进行均匀采样得到最后的动作信息。
对于采样动作的评估困难的问题,其主要来自于对于未来其他车辆状态预测中的高噪声,而这种噪声又源自于前述的“多假设未来”。针对这个问题,研究团队设计了两阶段的(two-stage)损失函数(cost function)计算和候选过滤几率。
在第一个阶段中,通过计算一个与其他车辆不直接相关的未来状态产生的损失来过滤掉一部分采样出的候选动作。之后在第二个阶段中,单纯对于在未来与其他车辆碰撞的几率,得到s*p*c的损失数值,其中s是一个折扣系数,目的是令距离当前越远的未来状态对于当前的决策影响越小,使得车辆可以优先专注于即将发生的危险,p是对于这个状态预测的信度(confidence)估计,c是和目标车辆产生碰撞的概率估计。通过这种与其他车辆相关(instance-aware)的损失计算,智能体最终选中了要被执行的驾驶动作。
自动驾驶研究中的局限:模拟环境与损失函数设计
在采访中,曹金坤非常坦诚地谈及这篇论文中方法的局限性和缺陷。曹金坤提醒,“受限于成本、法律等障碍,当前类似的实验都只能在模拟环境下进行,而这就对模拟环境的真实性提出了很高要求。而在如今的物理、数值计算、图形学等领域的发展状态下,我们还不可能有一个和现实场景一模一样的模拟环境,这就对开发策略在真实场景中的可用性带来了一些隐患。如果之后有了更加真实的模拟器乃至于‘元宇宙’,这个问题或许可以被缓解一些。”
同时,“我们的方法还基于人手工的损失函数的设计,这个问题也是现在的模型预测控制的一个几乎共有的问题,这个损失函数设计的好坏类似于强化学习中的奖励函数(reward function)的好坏一样,都会对方法的效果产生很大的影响,但是因为设计开发者自身的知识、场景状态简化的可行性等,都不可能是最完美的,所以我们希望这个领域可以有一个更好的“适应性”(adpative)或者自学习的损失/奖励函数的方法出现,在不同的场景和需求下使用不同的约束函数。但是这又变成了一个鸡生蛋还是蛋生鸡的问题,现在来看还是非常的困难,”曹金坤补充道。
商用的完全的自动驾驶离我们还有多远?
面对商用的完全的自动驾驶什么时候能替代人类上路开车的疑问,曹金坤表示,“很多问题,特别是技术问题,为了让公众了解,方便传播,往往会被过分的简化。比如‘商用的完全的自动驾驶’怎么定义呢?我们现在常说L1-L5,但是这个也是有问题的。如果我们讨论的是科幻中那种完全移除了驾驶座,道路上100%都是自动驾驶车辆在驾驶的话,我觉得技术上可能只需要10年,事故率就可以低于现在的人驾驶的事故率了,但是考虑到相关的法律、就业等问题,我觉得这个周期会长的多。”
“另外,如果这些车辆可以互相的分享信息,他们不是所谓的独立智能体的话,这个事情在技术上会更快一些。但是,如果不是100%的自动驾驶车辆,而是人和自动驾驶车辆混合的话,问题就变得复杂的多了,在法律上和技术上都是如此,我很难去预测这个事情了,我觉得也不可能有人可以预测。”
附:
研究中采用的CARLA模拟器和游戏侠盗猎车5(GTA5)
因为成本和可行性原因,现有的给予强化学习的自动驾驶策略都基于一些仿真模拟器进行,该文章方法基于英特尔团队开发的CARLA模拟器和著名的游戏侠盗猎车5(GTA5)进行。

CARLA模拟器中的道路场景

GTA V游戏中的驾驶场景
CARLA基于著名的虚幻5物理引擎,在物理仿真和场景真实度上相对于之前的同类产品都有很大的提升,而且因为其被设计的最初目的便是进行相关的研究和工程模拟,所以提供了完整的编程控制接口,可以进行自由的定制操作。
而GTA V是电子游戏侠盗猎车的最新作,在发布接近十年后仍旧拥有最优秀的视觉真实度和开放的场景设计,但是美中不足的是其作为一个游戏并不自带任何的编程控制接口,所以研究人员使用了一些外挂的控制脚本来进行自动驾驶车辆在游戏内的操作以及对其状况的分析。
澎湃新闻:请问做这样一个研究的初衷是什么?
曹金坤:现在自动驾驶的策略更多的基于规则(rule-based),也就是通过人手工设计的策略来进行驾驶。而在学术界中,很多人研究基于“模仿学习”(imitation learning)的方法,也就是让让车辆模仿在不同的情况下人的驾驶选择。但是这两种方法都有弊端,前者是人难免“百密一疏”,有些具体的场景无法被很好的规则覆盖,或者在进行设置的时候很多衡量的指标都难以具有普遍性。后者的问题在于,车辆只能学习人的好的、在安全场景下的驾驶策略,而一旦现实场景中的自动驾驶车辆进行了危险的、在学习时人没有作出示范的场景,他的策略就变成完全空白了。而相比较这两个方法,强化学习因为基于车辆的探索,所以可以更普遍地让车辆尝试和探索到不同的场景,相较于前两种方法有他的优势。而如果我们之后希望可以有大规模的、更加健壮的自动驾驶策略开发的流水线(pipeline),这种基于探索的策略或许至少会有一种有益的补充。
澎湃新闻:您觉得这个研究还有什么不足?
曹金坤:坦白地说,这个工作只能说是在前述的方向上做出了一点点探索而已,为了达到公众期待的自动驾驶,需要做的还有太多太多,我这边想提及几点比较重要的技术方面的不足:
1.受限于成本、法律等等障碍,现在没有团队可以在真实场景中做类似的实验,更不要提冒着损坏大量的车辆乃至于造成道路上安全事故的风险进行完整的基于探索的策略开发了,所以我们都只能在模拟环境下进行,而这就对模拟环境的真实性提出了很高要求。在如今的物理、数值计算、图形学等领域的发展状态下,我们还不可能有一个和现实场景一模一样的模拟环境,这就对开发策略在真实场景中的可用性带来了一些隐患。如果我们之后有了更加真实的模拟器乃至于“元宇宙”,这个问题或许可以被缓解一些。
2.我们的方法还基于人手工的损失函数的设计,这个问题也是现在的模型预测控制的一个几乎共有的问题,这个损失函数设计的好坏类似于强化学习中的奖励函数(reward function)的好坏一样,都会对方法的效果产生很大的影响,但是因为设计开发者自身的知识、场景状态简化的可行性等,都不可能是最完美的,所以我们希望这个领域可以有一个更好的“适应性”(adpative)或者自学习的损失/奖励函数的方法出现,在不同的场景和需求下使用不同的约束函数。但是这又变成了一个鸡生蛋还是蛋生鸡的问题,现在来看还是非常的困难。
3.我们的论文中提出,因为其他车辆行为的随意性,受控车辆面对的实际上是“多假设未来”(multi-hypothesis future),也就是说从现在的时间点出发,即使受控车辆一直采取一样的行动,未来的整个道路情况都依旧是不确定的。为了解决这个问题,我们设计去预测未来的的状态分布,而不是单一可能。但是从根本上说,这种方法受限于模型的遗忘和从有限数据采样预测分布的困难等问题,做的还是不够好的,需要进一步的改进。
做研究的过程某种程度上也是个不断自我否定的过程,逐步发现自己做的东西的不足,但在这里我还是对自己宽容一些吧,就先只说这三点吧。
澎湃新闻:这个项目过程中遇到的最大挑战是什么?
曹金坤:挑战还是蛮多的,首先是我们的方法还是会利用一些黑箱吧,很多时候一个模型的效果不好,我们会比较难知道怎么去定位,需要一些尝试。然后是一些工程上的问题,无论是CARLA还是GTA V,用起来都需要一些学习成本的。最后是时间问题,我做这个项目的时候是在加州大学伯克利分校做访问,因为我们的方法是完全在线的,收集数据和训练模型都需要实时的去做,我们经常一次尝试就需要训练四五天然后才能知道结果,这样的周期还是很长的,等待过程有点煎熬。
澎湃新闻:接下来的研究计划是什么呢?
曹金坤:我现在在新的学校读博了,也有一些新的任务,和计算机视觉以及自动驾驶还是有关的,但是因为研究组的方向问题,在这个项目上暂时没有进一步的计划了。我前面也说了很多的缺陷可以作为future works的起点,或许会有别的研究者继续做相关的工作吧。
澎湃新闻:您作为相关专业领域的研究人员,觉得商用的完全的自动驾驶离我们还有多远?
曹金坤:这个问题很好,我常常有一个看法是,很多问题,特别是技术问题,为了让公众了解,方便传播,往往会被过分的简化。比如“商用的完全的自动驾驶”怎么去定义它呢?我们现在常说L1-L5,但是这个也是有问题的。如果我们讨论的是科幻中那种完全移除了驾驶座,道路上100%都是自动驾驶车辆在驾驶的话,我觉得技术上可能只需要10年吧,事故率就可以低于现在的人驾驶的事故率了,但是考虑到相关的法律、就业等问题,我觉得这个周期会长的多。另外,如果这些车辆可以互相的分享信息,他们不是所谓的独立智能体的话,这个事情在技术上会更快一些。但是,如果不是100%的自动驾驶车辆,而是人和自动驾驶车辆混合的话,问题就变得复杂的多了,在法律上和技术上都是如此,我很难去预测这个事情了,我觉得也不可能有人可以预测。
澎湃新闻:您提到了在向公众传播技术问题时候对问题简化的带来的问题,我们作为媒体从业者对这点非常的感兴趣,可以展开说说么?
曹金坤:实际上就是一个严谨性和传播性的取舍了。现在人工智能很火,很多的公众号都是请我们这些从业者去写论文都难免会有问题,这是因为技术问题的描述本来往往是需要很长的前缀的,而在面向公众的传播载体中,一般很难这么做,毕竟一个句子太长,读两遍读不懂,读者就不看了。我们这些博士是因为不读不行,不然我们也不愿意读呀。
我举个例子吧,关于最近的特斯拉放弃雷达这个事情,我看网上有人在讨论“好不好”、“可行不可行”。但这个问题真的很难被如此简单的讨论,因为这和人们对于“自动驾驶有多好”的期待有关。如果只是期待自动驾驶做到和人一样的安全性,那当然是可行的,毕竟人的脑袋上也没有长雷达。但是如果是期待在很多的场景下,比如大雨大雪等,自动驾驶可以做人做不到的事情,那么特斯拉可以说是基本放弃了这个野心了。所以在传播和讨论的时候,有时候把这些前提说清楚还是蛮重要的,而如何怎么简洁准确地说清楚这个事情,让技术类的文章相对准确又相对易读,就是媒体的工作了。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

