- +1
全民自动驾驶5年内真的会来吗?这是Lyft的自动驾驶2.0
机器之心报道
编辑:杜伟、小舟
过去十年,尽管机器学习已经在图像识别、决策制定、NLP 和图像合成等领域取得很多成功,但却在自动驾驶技术领域没有太多进展。这是哪些原因造成的呢?近日,Lyft 旗下 Level 5 自动驾驶部门的研究者对这一问题进行了深入的探讨。他们提出了自动驾驶领域的「Autonomy 2.0」概念:一种机器学习优先的自动驾驶方法。

论文地址:https://arxiv.org/pdf/2107.08142.pdf
自 2005 至 2007 年的 DARPA 超级挑战赛(DARPA Grand Challenge,由美国 DARPA 部门出资赞助的无人驾驶技术大奖赛)以来,自动驾驶汽车(SDV)就已经成为了一个活跃的研究领域,并经常成为头条新闻。许多企业都在努力开发 Level 4 SDV,有些企业已经在该领域耕耘了十多年。
已经有一些研究展示了小规模的 SDV 测试,虽然很多预测都认为「仅需要 5 年就可以迎来无处不在的 SDV 时代」,但应看到生产级的部署似乎依然遥不可及。鉴于发展进程受限,我们不可避免地会遇到一些问题,比如为什么研究社区低估了问题的困难度?当今 SDV 的发展中是否存在一些根本性的限制?
在 DARPA 挑战赛之后,大多数业内参与者将 SDV 技术分解为 HD 地图绘制、定位、感知、预测和规划。随着 ImageNet 数据库带来的各种突破,感知和预测部分开始主要通过机器学习(ML)来处理。但是,行为规划和模拟很大程度上仍然基于规则,即通过人类编写的越来越详细的关于 SDV 应如何驱动的规则实现性能提升。一直以来有种说法,在感知非常准确的情况下,基于规则的规划方法可能足以满足人类水平的表现。这种方法被称为 Autonomy 1.0。
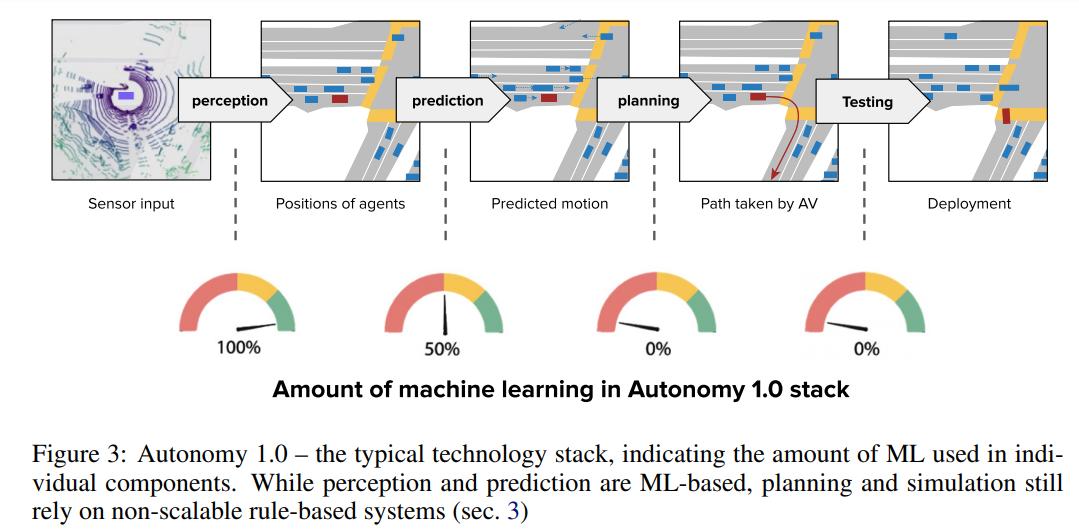
图 3:Autonomy 1.0 的典型技术堆栈,展示了各个组件中使用到的 ML 数量。从图中可以看到,感知和预测组件是基于 ML 的,但规划和模拟依然依赖于非扩展、基于规则的系统。
但是,生产级的性能需要大规模地扩展以发现和妥当处理小概率事件的「长尾效应(long tail)」。研究者认为 Autonomy 1.0 无法实现这一点,原因有以下三点:
一是基于规则的规划器和模拟器无法有效地建模驾驶行为的复杂度和多样性,需要针对不同的地理区域进行重新调整,它们基本上没有从深度学习技术的进展中获得增益;
二是由于基于规则的模拟器在功效上受限,因此评估主要通过路测完成,这无疑延迟了开发周期;
三是 SDV 路测的成本高昂,且扩展性差。
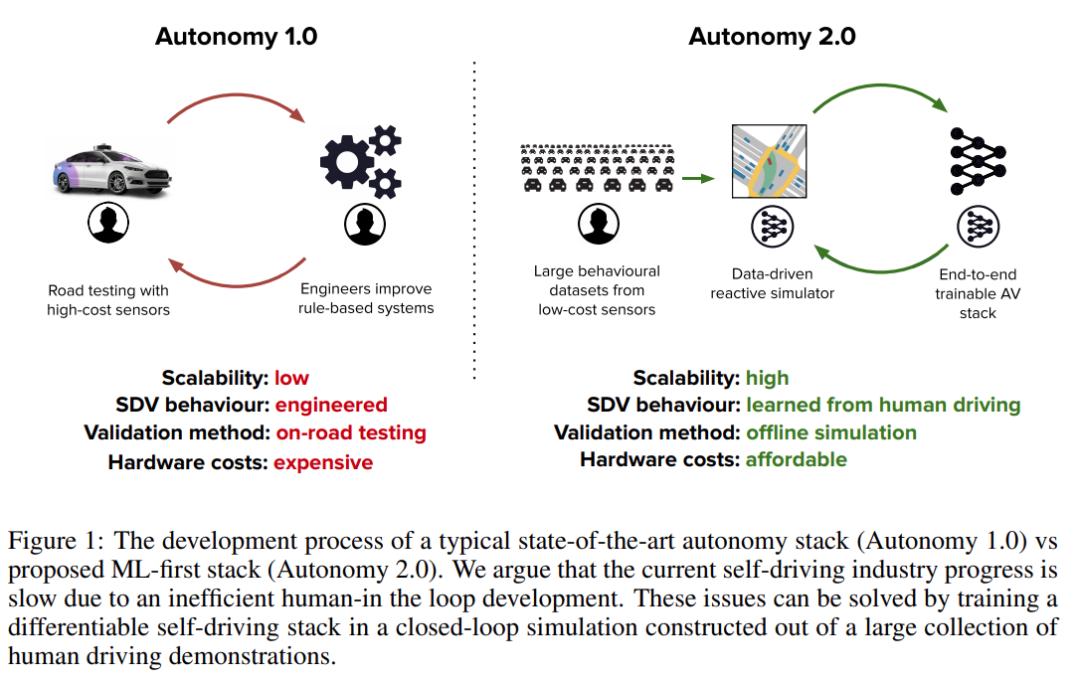
因此,针对这些扩展瓶颈,研究者提出将整个 SDV 堆栈转变成一个 ML 系统,并且该系统可以使用包含多样化且真实的人类驾驶数据的大规模数据集来训练和离线验证。他们将这个 ML 系统称为 Autonomy 2.0,它是一个数据优先的范式:ML 将堆栈的所有组件(包括规划和模拟)转化为数据问题,并且通过更好的数据集而不是设计新的驾驶规则来实现性能的提升。这样做极大地释放了处理小概率事件长尾效应和扩展至新的地理区域所需要的扩展性,唯一需要做的是收集规模足够大的数据集并重新训练系统。
Autonomy 1.0 与 Autonomy 2.0 的开发流程对比,可以看到 Autonomy 1.0 的可扩展性低、SDV 行为由工程师赋予、验证方法为路测、硬件成本高,而 Autonomy 2.0 的可扩展性高、SDV 行为从人类驾驶中学得、验证方法为离线模拟、硬件成本在可负担范围内。
不过,Autonomy 2.0 也面临着以下几项主要挑战:
将堆栈表示为端到端可微网络;
在闭环中利用机器学习的模拟器进行离线验证;
收集训练这些模拟器需要大量人类驾驶数据。
Autonomy 2.0
Autonomy 2.0 是一种 ML 优先的自动驾驶方法,专注于实现高可扩展性。它基于三个关键原则:i) 闭环模拟,即模型从收集的真实驾驶日志中学习;ii) 将 SDV 分解为端到端的可微分神经网络;iii) 训练规划器和模拟器所用的数据是使用商品传感器大规模收集的。
数据驱动的闭环反应模拟
Autonomy 2.0 中的大部分评估都是在模拟中离线完成的。基于规则的模拟具有一些局限性,这与 Autonomy 1.0 对路测的依赖形成鲜明对比。但这并不意味着 Autonomy 2.0 完全放弃了路测,不过其目标在开发周期中不太突出,主要用于验证模拟器的性能。为了使模拟成为开发道路测试的有效替代品,它需要三个属性:
适用于任务的模拟状态表征;
能够以高保真度和强大的反应能力合成多样化和逼真的驾驶场景;
应用于新的场景和地域时,性能随着数据量的增加而提升。
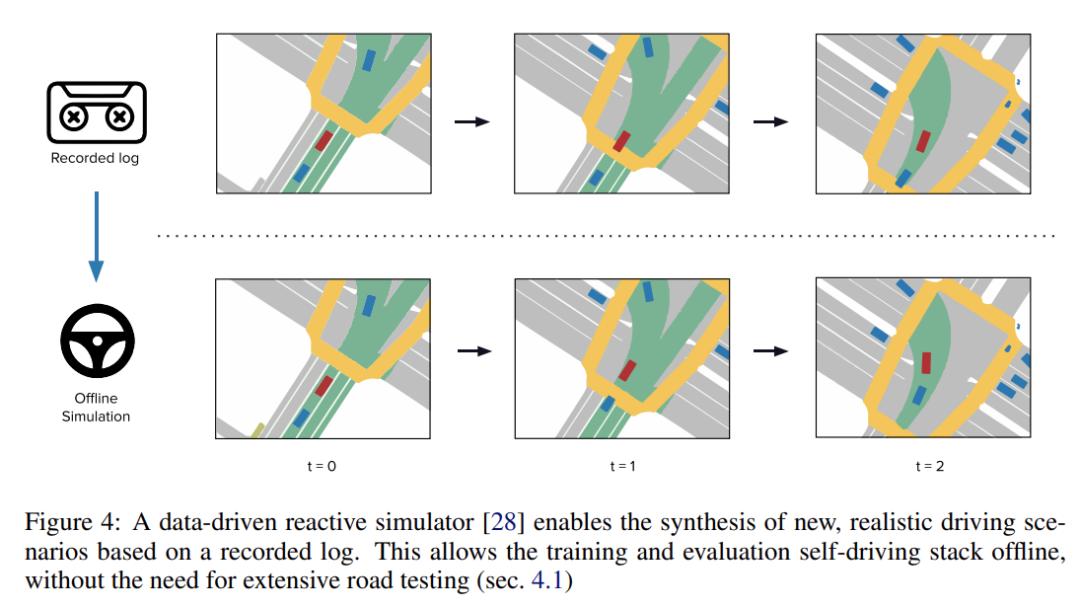
模拟结果必须非常真实,因为模拟和现实之间的任何差异都会导致性能估计不准确,但它不需要是照片般逼真的 [29],而是只关注规划器的表示。该研究推断,为了达到高水平的真实感,模拟本身必须直接从现实世界中学习。最近,[28] 展示了如何使用鸟瞰图表示从先前收集的真实世界日志中构建逼真的和反应性的模拟。如图 4 所示,然后可以部署此模拟将任何日志转换为反应式模拟器,用于测试自动驾驶策略。
从人类演示中训练出来的完全可微的堆栈
Autonomy 1.0 具有手工设计的基于规则的组件,以及感知、预测、规划和模拟之间的人类可解释接口。与 之不同,Autonomy 2.0 堆栈完全可以通过人类演示进行训练,因此其复杂性与训练数据量成正比。为了训练这样一个系统,需要满足几个条件:
每个组件,包括规划,都需要可训练且端到端的可微分;
可使用人工演示进行训练;
性能与训练数据量成正比。
下图 5 是完全可微的 Autonomy 2.0 堆栈架构,可以从数据进行端到端的训练,而无需设计单个块和接口。其中, d、h、f 和 g 是可学习的神经网络。d 和 h 给出了规划发生的场景的潜在表示。f 代表 SDV 和场景中代理的策略。g 是状态转移函数。I_0 是网络的输入,而 {I_1, ··, I_3} 在训练期间提供监督。

大规模低成本数据采集
到目前为止讨论的系统使用人类演示作为训练数据,即具有由人类驾驶员选择的相应轨迹的传感器数据作为监督。要解锁生产级性能,这些数据需要具备:
足够的规模和多样性以包括罕见事件的长尾;
足够的传感器保真度,即用于收集数据的传感器需要足够准确才能有效地训练规划器和模拟器;
足够便宜,可以以这种规模和保真度收集。
虽然最近第一个带有人类演示的公开数据集已发布,但这些数据仅限于几千英里的数据。观察长尾可能需要收集数亿英里的数据,因为大多数驾驶都是平安无事的,例如在美国,每百万英里大约有 5 起撞车事故 。
应该使用哪些传感器呢?感知算法的最新进展表明,在 KITTI 基准测试 [44] 上,高清和商用传感器(如相机 和稀疏激光雷达 [42])之间的感知精度差距缩小了,如下表 1 所示。
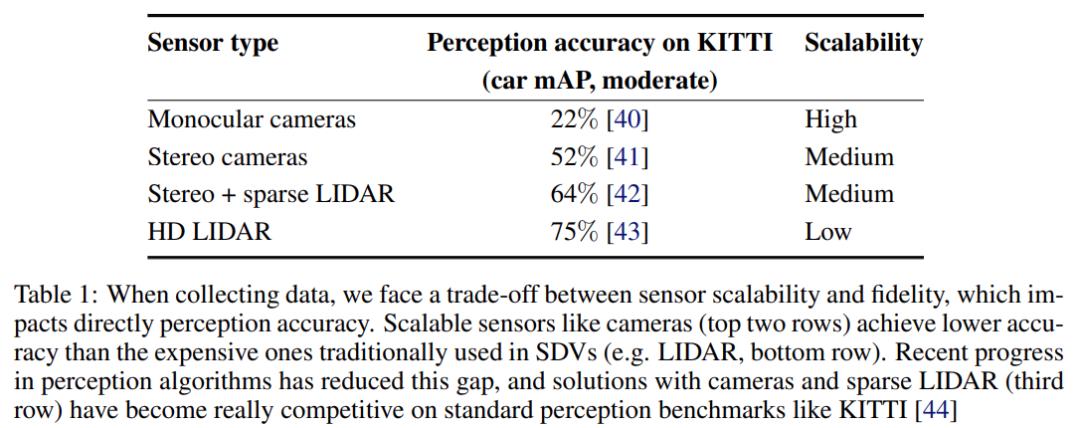
表 1:收集数据时面临传感器可扩展性和保真度之间的权衡,这会直接影响感知精度。
未来需要解决哪些问题
研究者概述了 Autonomy 2.0 的范式,旨在使用 ML 优先的方法解决自动驾驶问题。并且,通过消除人在回路(human-in-the-loop),这一范式的扩展性更强,这也是实现高性能自动驾驶汽车技术的主要痛点。虽然 Autonomy 2.0 范式的发展前景很好,但依然有需要解决的问题,具体如下:
模拟和规划的恰当状态表示是什么?我们应如何衡量场景概率?
我们应如何检测异常值(outlier)以及从未见过的情况(case)?
与使用搜索进行的实时推理相比,通过人类演示进行离线训练的极限在哪里?
我们需要在模拟上投入多少?又应如何衡量离线模拟本身的性能?
我们在训练高性能规划和模拟组件上需要多少数据?在大规模数据收集时又应该使用什么传感器呢?
解答这些问题对于自动驾驶和其他现实世界的机器人问题至关重要,并且可以激发研究社区尽早解锁高性能 SDV。
数据智能技术实践论坛——从数据到知识的「智变」
8月27日15:00-17:00,百分点科技与机器之心联合举办「数据智能技术实践论坛」全程线上直播,四位业界专家与学者详细解读多模态数据融合治理、计算机视觉、基于知识图谱的认知智能、知识图谱构建等领域的技术进展和实践心得。
演讲一:融合创新——计算机视觉技术与产业化发展之道
演讲二:从「治」理到「智」理,多模态数据管理PAI应用方法论
演讲三:从知识图谱到认知智能
演讲四:知识图谱技术及行业应用实践
直播设有QA环节,欢迎加群交流答疑。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《全民自动驾驶5年内真的会来吗?这是Lyft的自动驾驶2.0》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

