- +1
网易云信神经网络音频降噪算法:提升瞬态噪声抑制效果,适合移动端设备
原创 Synced 机器之心
机器之心专栏
网易云信音频实验室
网易云信音频实验室自主研发了一个针对瞬态噪声的轻量级网络音频降噪算法(网易云信 AI 音频降噪),对于 Non-stationary Noise 和 Transient Noise 都有很好的降噪量,并且控制了语音信号的损伤程度,保证了语音的质量和理解度。
基于信号处理的传统音频降噪算法对于 Stationary Noise(平稳噪声)有比较好的降噪效果。但是对于 Non-stationary Noise(非平稳噪声),特别是 Transient Noise(突发噪声)降噪效果较差,而且有些方法对于语音也有较大的损伤。随着深度学习在 CV(Computer Vision)上的广泛应用,基于神经网络的音频降噪算法大量涌现,这些算法很好的弥补了传统算法对于 Non-stationary Noise 降噪效果不好的问题,在 Transient Noise 上也有较大的提升。
但是,基于神经网络的音频降噪在计算复杂度上存在挑战。虽然我们生活中的终端设备的计算能力在不断提升,比如个人笔记本、手机等,但是大模型的深度学习算法,很难在绝大部分设备(特别是不含 GPU 的设备)上运行。目前也有一些开源的、基于神经网络的低开销降噪算法[1,2,3],能够在大部分终端设备上达到实时运行的标准。但是这些算法的运算量对于 RTC(实时通信)的 SDK 依然太大,其原因是 SDK 中包含了大量算法,每个子算法的开销都必须严格把控,才能保证整个 SDK 的运算开销在一个合理范围,并且能够在大部分终端设备上运行。
针对上述挑战,网易云信音频实验室自主研发了一个针对瞬态噪声的轻量级网络音频降噪算法(网易云信 AI 音频降噪),对于 Non-stationary Noise 和 Transient Noise 都有很好的降噪量,并且控制了语音信号的损伤程度,保证了语音的质量和理解度。与此同时,云信的 AI 音频降噪将计算开销控制在一个非常低的量级,达到了和传统算法接近的计算量,比如 MMSE [4]。目前,网易云信的 AI 音频降噪已经成功落地在其自研的新一代音视频技术架构(NERTC)中,在大幅提升降噪效果的同时,也在大多数终端机型上成功应用,包括了大部分中低端机型。
本文介绍的内容,即网易云信音频实验室发表于 INTER-NOISE 2021 的《A Neural Network Based Noise Suppression Method for Transient Noise Control with Low-Complexity Computation》一文,本篇文章详细介绍了在基于深度学习的音频降噪算法中,如何在低计算开销的情况下,实现对不同噪声,包括 Transient Noise 的抑制。
方法
在介绍算法细节之前,我们需要先在数学上来构建一下问题模型。在公式(1)中,x (n) 、s (n) 、和 d (n)分别代表带噪信号、干净语音信号和噪声信号。
带噪信号x (n)代表麦克风在实际场景中所收集的信号,其中n代表时域采样点。我们对公式(1)做一个 STFT(短时傅里叶变化)得到(2),
其中
分别代表x (n) 、s (n)和 d (n)的频域信号,i代表第
时域帧,k代表频点。由此我们可以得出公式(3),
代表估计出的语音信号,
表示估计出的 Gain 大小。至此,我们的降噪问题就是需要去估计出一个准确的
。
特征表示
为了要实现低计算量的目的,我们需要最大限度的去压缩模型大小,这样必然导致在同等状况下,压缩后模型的表现会更差。为了弥补模型变小后带来的效果下降,该研究从输入特征(Input Feature)入手,选择更能代表语音特性的特征,从而去区分语音和噪声。当然特征大小(Feature Size)也需要严格控制,共同保证低计算量的要求。现在开源的单通道深度学习降噪算法中,比较普遍的 Feature 是用信号的 Magnitude 和 Phase,或者直接用频域信号的 Complex Value。这样的做法好处是可以保证模型能获得所有的频域信息,没有任何信息丢失;但是缺点是这些频域信息对于语音信号和噪声信号的分离度不够,而且输入的参数量偏大。方法 [1] 中用到了 Pitch Correlation(基音相关性),
表示求信号的相关性,
表示 Pitch Correlation。Pitch Correlation 能够突出语音信号的特性,能在噪声中将语音信号分离出来。Pitch Correlation 在平稳噪声上有着很好的表现,但是一旦出现非平稳噪声,由于 Pitch Correlation 只包含帧内信息,这时候就无法区分分平稳噪声和语音了。还有一种情况,当 SNR(信噪比)比较小时,时域的自相关性受噪声影响大,容易导致其判断不准,从而产生误差。针对以上问题,我们提出了谐波帧间互相关性(Harmonic-Correlation),
其中
之前
帧的 Magnitude。对于
该研究分两步来讨论它的优势。首先,对频域 Magnitude(
)做自相关(Auto-Correlation)可以突出谐波特性(类似于 Spectral Sharpening 或者 Reverse Whitening),对于语音信号中的谐波特性,可以更容易的凸显出来。其次,把自相关换成和前
帧的 Magnitude 做互相关(Cross-Correlation)可以增加帧间的信息,语音信号的谐波相比一些突发噪声具有更长的连续性,以此可以将一些突发噪声从语音信号中区分开。
另外一个和
相似的特征是 Coherence,公式如下,
可以看出,Coherence 也可以突出信号中的谐波信息,不同之处在于它也是基于时域的相关性,而且增加了归一化处理。
损失函数
Valin 在 [1] 中提出了一种损失函数,
其中
代表 Gain 值的 Ground Truth,
代表估计出的 Gain 值。
通过平方的 Error 值,在训练过程中不断调整模型收敛方向,并且通过四次方的 Error 值去加强微调能力,让收敛后的模型最终的损失能够进一步减小。
在研究过程中研究发现,虽然
有着较好的调节能力,但是存在两个问题。第一个问题是
容易陷入局部最小值,由于平方过后 Error 值偏小,导致很难逃出这个区间。第二个问题是四次方的部分有时在实际信号中不好控制,在最终收敛时会因为C值过大而产生误差。因此,该研究在
的基础上提出了
,
在
中,我们可以根据需要去调节
的大小,从而减小陷入局部最小值的概率,并且最大程度的减小收敛后的最终误差。经过计算,
的值从 0 增加的 5 的时候,最终 Loss 值达到最小,但是由于
的增加会导致计算量的增加,最终收益最大的
值为 3。
学习模型以及实时处理
该研究沿用了 [1] 中 RNN-GRU 模型,原因是 RNN 相比其他学习模型(例如 CNN)携带时间信息,可以学习到数据中前后在时序上的联系。该研究认为这种联系在语音信号上非常重要,特别是在一个实时的、帧长相对较短的语音算法中。模型的结构如 Fig.1 所示。训练后的模型会被嵌入网易云信的 SDK 中,通过读取硬件设备的音频流,对 Buffer 进行分帧处理并送入 AI 降噪预处理模块中,预处理模块会将对应的 Feature 计算出来,并输出到训练好的模型中,通过模型计算出对应的 Gain 值,对信号进行调整,最终达到降噪效果(Fig.2)。
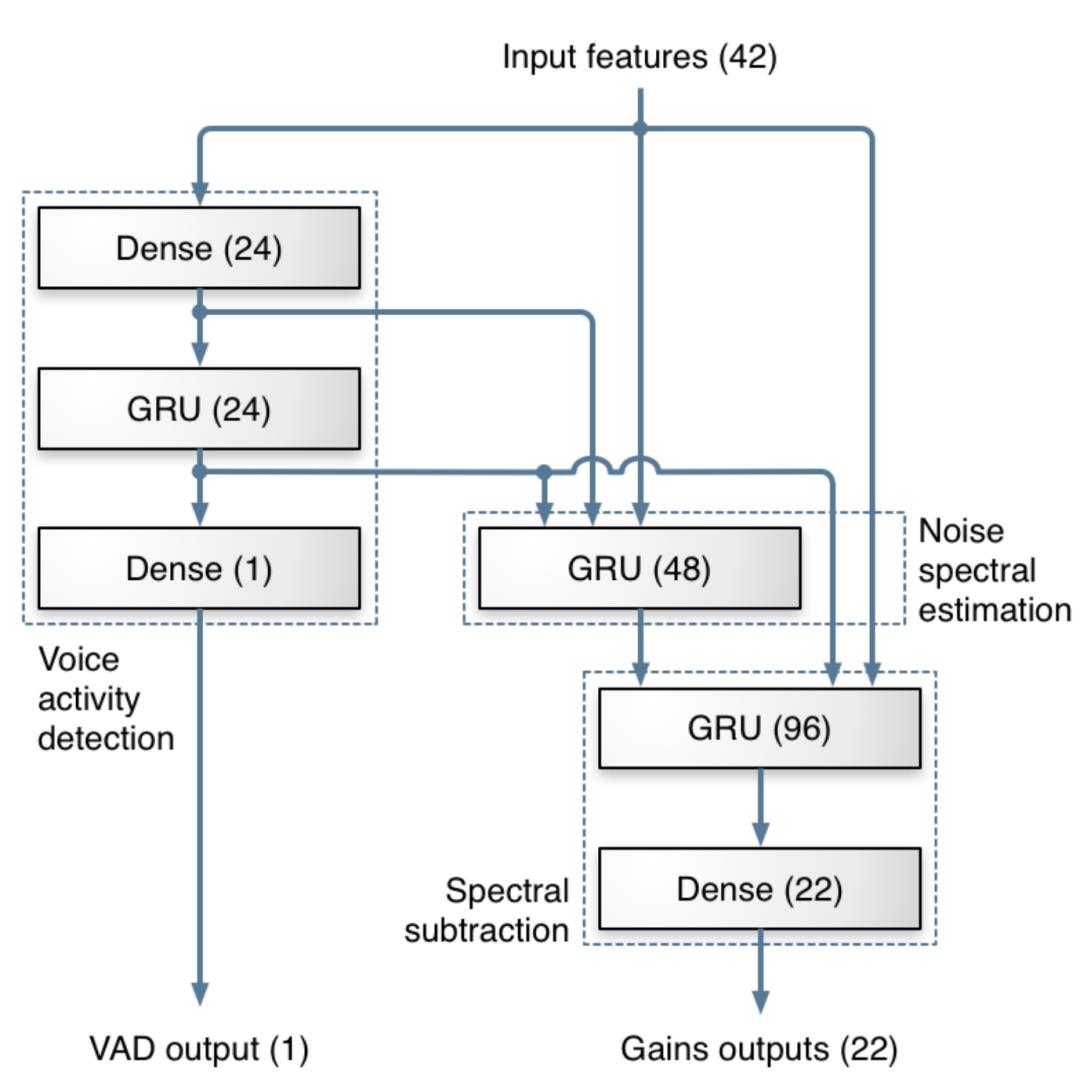
Figure 1: GRU模型。
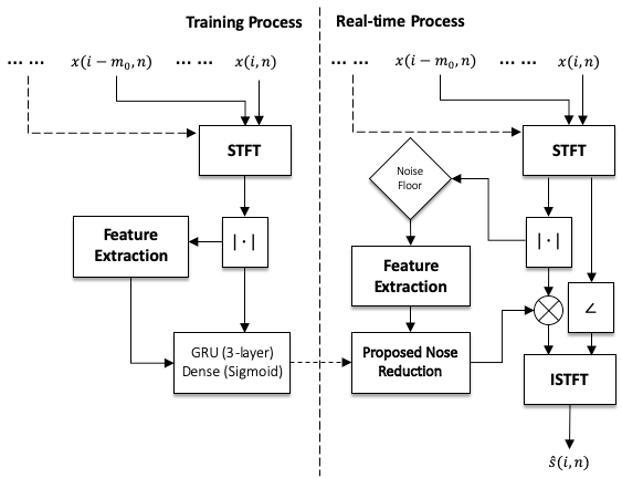
Figure 2: 训练和实时处理框图。
测量结果和讨论
在测试阶段,该研究首先建立了和 Training/Validation 完全不同的一个测试集。在对比项上,选择了 [4] 作为传统信号处理的降噪算法代表。在基于深度学习的算法中,研究者首先选择了 RNNoise[1],以此来评估优化所带来的效果提升。其次,该研究选择了 DNS-Net[2]和 DTLN[3]当下两个热度很高的实时 AI 降噪算法来作为对比项。
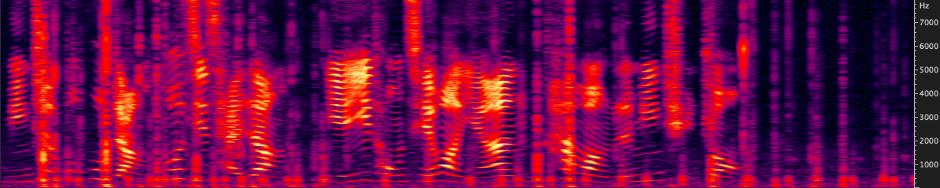
(a)Noisy signal (5dB SNR)


Fig.3 展示了一段 Keyboard Noise 下的降噪前后对比。Keyboard Noise 作为 Transient Noise 中的一种,是在 RTC 场景中非常容易遇到的噪声。比如在一个在线会议中,会议中的任意一位参会者在用键盘记录会议信息时,都会让这个会议陷入键盘噪声中。Fig.3 展示的是在 5dB SNR 场景下的情况。从图中可以看出,网易云信 AI 降噪在非语音部分,对键盘噪声的压制极大,基本全部消掉;在和语音重合部分,虽然没有完全消掉,但是也有明显抑制,并且保护了语音质量。
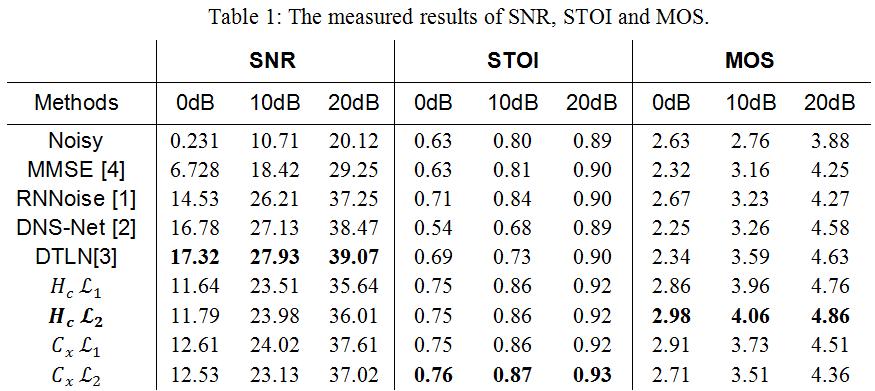
在 RTC 场景中,当降噪后 SNR 达到 20dB 以上,3-4dB 的差值对于听感来说差异较小。所以该研究在调试中把降噪量稳定在一个范围内,然后尽量去追求更高的语音理解度(STOI[5])和语音质量(MOS[6])。Table 1 展示了云信 AI 降噪和对比项之间的量化对比。从结果中可以看出,网易云信自研的 Feature 和 Loss Function 在整体上呈现对语音保护更好,降噪量略小。其中,
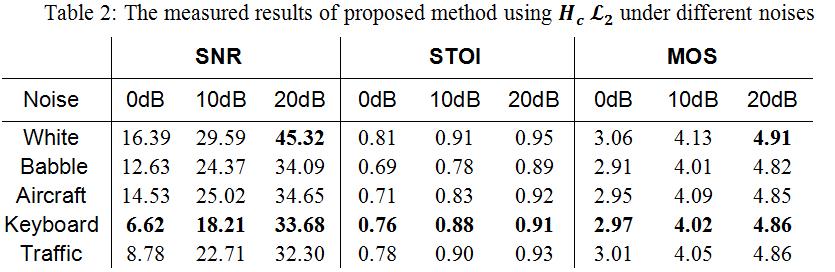
对语音质量保护最好,在降噪量上也在可接受的范围内。Table 2 展示了
在不同噪声类型上的表现。在 Keyboard 噪声中,虽然在低 SNR 的情况下降噪量提升不明显(RTC 场景中,持续低信噪比的 Transient Noise 场景出现频率较低),但是在 10dB SNR 以上的场景中,降噪量和其他噪声接近,并且保持着很好的语音质量。该研究也定性的测试其他的 Transient Noise,降噪量和语音质量都保持在很稳定的水平。
网易云信的 AI 降噪在 10ms 的音频帧数据(16kHz 采样率)中只需要约 400,000 次浮点计算,经过云信自研的 AI 推理框架 NENN 加速,在 iPhone12 上每 10ms 的运算平均时间低于 0.01ms,峰值时间低于 0.02ms,CPU 占比小于 0.02%。
总结
综上所述,网易云信 AI 降噪实现了一个轻量级的实时神经网络音频降噪算法。它在 Stationary 和 Non-Stationary Noise 上都有很好的效果,对于业界的难点 Transient Noise 也有很好的抑制效果;与此同时,相较同类 AI 降噪算法,云信 AI 降噪对语音质量有着更好的保护。
自成立以来,网易云信音频实验室除了保障产品的算法研发和优化需求之外,已提交专利数十项。接下来,网易云信音频实验室将在基础算法、模型方面加强研究,结合具体行业和应用场景,以技术创新引领产品创新。
参考文献
1.J.M. Valin, "A hybrid DSP/deep learning approach to real-time full-band speech enhancement," 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP). IEEE, 2018.
2.Y. Xia, et al, "Weighted Speech Distortion Losses for Neural-Network-Based Real-Time Speech Enhancement," ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
3.Westhausen, Nils L., and Bernd T. Meyer. "Dual-signal transformation lstm network for real-time noise suppression." arXiv preprint arXiv:2005.07551 (2020).
4.Y. Rao, Y. Hao, I.M. Panahi, "Smartphone-based real-time speech enhancement for improving hearing aids speech perception," 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2016.
5.C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short-time objective intelligibility measure for time-frequency weighted noisy speech,” in IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 4214– 4217, 2010.
6.Nilsson, Michael, Sigfrid D. Soli, and Jean A. Sullivan. "Development of the Hearing in Noise Test for the measurement of speech reception thresholds in quiet and in noise." The Journal of the Acoustical Society of America 95.2 (1994): 1085-1099.
原标题:《网易云信神经网络音频降噪算法:提升瞬态噪声抑制效果,适合移动端设备》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

