- +1
OpenAI CLIP模型袖珍版,24MB实现文本图像匹配,iPhone上可运行
机器之心报道
机器之心编辑部
OpenAI 的 CLIP 模型在匹配图像与文本类别方面非常强大,但原始 CLIP 模型是在 4 亿多个图像 - 文本对上训练的,耗费了相当大的算力。来自 PicCollage 公司的研究者最近进行了缩小 CLIP 模型尺寸的研究,并取得了出色的效果。
今年 1 月初,OpenAI 打破了自然语言与视觉的次元壁,接连推出了两个连接文本与图像的神经网络 DALL·E 和 CLIP,后者能够完成图像与文本类别的匹配。CLIP 能够可靠地执行一系列视觉识别任务,给出一组以语言形式表述的类别,它即能够立即将一张图像与其中某个类别进行匹配,而且不像标准神经网络那样需要针对这些类别的特定数据进行微调。
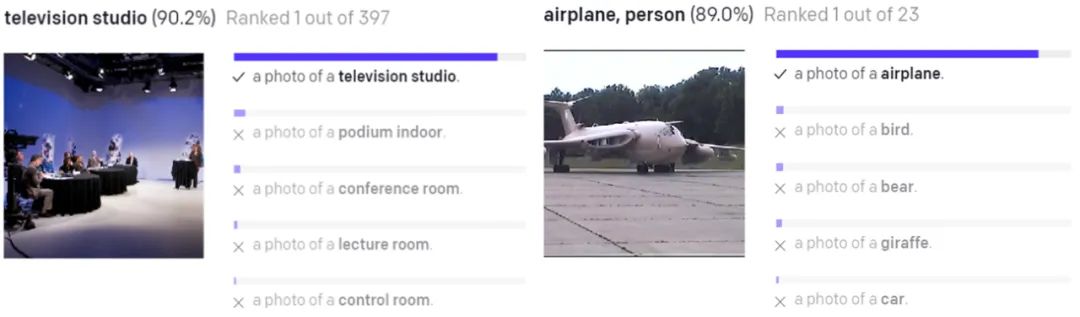
CLIP 模型的一些效果示例。图源:OpenAI
之后,OpenAI 更是在 CLIP 模型中发现了。这类神经元能够对以文本、符号或概念形式呈现的相同概念作出反应,例如「Spider-Man」神经元(类似 Halle Berry 神经元)能够对蜘蛛图像、文本「spider」的图像和漫画人物「蜘蛛侠」做出响应。
虽然 CLIP 模型在匹配图像与文本类别方面非常强大,但它是在 4 亿多个图像 - 文本对上训练的,使用了很大的算力,需要 256 个 GPU 训练两周。这对于普通开发者来说是无法想象的。因此,是否有可能缩小 CLIP 模型的尺寸,并且不减弱其性能呢?
最近,PicCollage 公司的研究者对这一课题展开了研究,他们在自己的内容产品上对 CLIP 模型的性能进行了测试,并且获得了满意的效果。不过很快发现了 CLIP 模型的一个奇怪点:在搜索查询中优先考虑文本相似度而不是语义相似度。他们想要解决 CLIP 模型过分重视文本相似度的问题,以此获得更相关的搜索结果。
除此之外,研究者还想缩小 CLIP 模型的尺寸并探索在 IOS 设备上部署的可能性。他们使用模型蒸馏的方法来缩小 CLIP 的尺寸,350MB 的原始模型(可称为 teacher 模型)蒸馏后降为 48MB(student 模型),精度为 FP32。并且,在单个 P100 GPU 上训练了数周后,他们将 48MB 大小的 student 模型转换成了 CoreML 格式,并再次得到了 24MB 大小的模型,精度为 FP16,性能变化几乎可以忽略不计。研究者表示,蒸馏后的模型可以在 iPhone 等 IOS 设备上运行。
接下来详细解读研究者的探索过程。
在图像中过分强调文本
让我们用一个简单的设置来演示这一问题,考虑三张图片:
一张带有「Cat」这个词的图片;
一张带有「Gat」这个词的图片;
一张带有猫的图片。


假设你正在搜索「cat」这一单词,CLIP 将把这一文本转换为向量,即 text_vector,上面三张图像向量的 text_vector 余弦相似度如下所示:
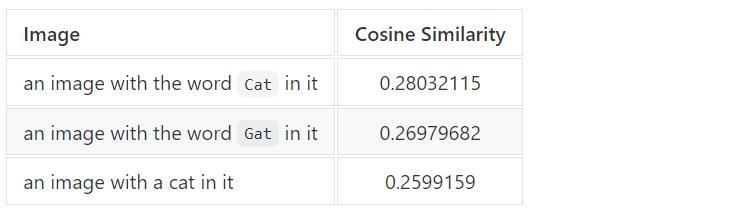
我们可以得出搜索词和图像之间的相似性可以通过两种方式来表达「相似」:
图像包含与搜索词相似的文本:即文本相似;
图像和搜索词语义相似:即语义相似。
在构建搜索功能时,研究者可能更喜欢语义相似性而不是文本相似性。研究人员发现 CLIP 倾向于给文本相似的图像更高的分数。
解决方案在图像中过分强调文本
假设在共享向量空间中存在一个方向,其中图像的「文本,textness」属性变化很大,而其他(语义)属性保持不变。如果我们可以找到这个方向,就可以使用一个向量指向该方向,并将其添加到所有的图像向量(或文本向量),然后对它们进行归一化并计算余弦相似度,我们称这个向量为 textness_bias 向量。
换句话说,在进行下面操作之前:
image_vectors /= np.linalg.norm(image_vectors, axis=-1, keepdims=True)cosine_similarities = text_vector @ image_vectors
我们需要先进性如下操作:
# add bias to the image vectorsimage_vectors += scale * textness_bias# or add bias to the text vectortext_vector += scale * textness_bias
下一个问题是如何找到 textess_bias 向量?这里有两种不同的方法,可以得到相似的答案。如下是第二种方法:
Reducing “textness”: training a small model with no hidden layerWe created a dataset of images with and without text in them. The idea was to train a model and then use the weights of the model as an indicator of textness bias:class Model(nn.Module): def __init__(self, dim=512): super(Model, self).__init__() self.linear = nn.Linear(dim, 2)def forward(self, x): return self.linear(x)model = Model()Then we used the weight vector responsible for predicting the positive label as the textness bias. Another interesting finding was that adding the bias to the text vector was much more effective than adding it to the image vectors.textness_bias = model.linear.weight[1]text_vector += scale * textness_biasThe bigger the scale, the more emphasis CLIP puts on textual similarity. Let's take a look at some of the results.Results of controlling textual similarity in searchFor every search term, we varied the value of scale sequentially like so: -2, -1, 0, 1, 2. For each value of scale, we stored the top ten results in a single row. Thus for each search term, we got a grid of images where each row corresponded to a value of scale and contained top ten results for that scale. Notice how the preference for textual similarity increases as we go from top row to bottom row:
减少「文本」:训练一个没有隐藏层的小模型
创建一个包含和不包含文本的图像数据集,实现思想是训练一个模型,然后使用模型权重作为 textness bias 指示器:
class Model(nn.Module): def __init__(self, dim=512): super(Model, self).__init__() self.linear = nn.Linear(dim, 2)def forward(self, x): return self.linear(x)model = Model()
然后使用权重向量预测正标签,作为 textness bias,同时还可以发现将偏差添加到文本向量比将其添加到图像向量更有效。
textness_bias = model.linear.weight[1]text_vector += scale * textness_bias
scale 越大,CLIP 就会更加强调文本相似性,让我们来看看一些结果。
在搜索中控制文本相似性的结果
对于每个搜索词,我们依次改变 scale 的值如下:-2, -1, 0, 1, 2。对于每个 scale 值,我们将 top10 结果存储在一行中。因此,对于每个搜索项可以得到一个图像网格,其中每一行对应一个 scale 值,并包含该 scale 值的 top10 结果。

ViT 的模型蒸馏
CLIP 具备强大的功能,下一步研究者决定使用模型蒸馏来减小其大小。该任务包含一些细节:
使用蒸馏的方法:CLIP 模型实际上是具有一组不相交参数的两个模型:ViT(将图像转换为向量)和 Transformer(将文本转换为向量)。我们决定对 ViT 模型(~350MB,FP32 精度)进行模型蒸馏。student ViT 模型的大小决定为小于 50MB。
student 模型:原始 ViT 模型是由一个名为 VisualTransformer 的类定义的。该模型依照如下代码创建:
teacher_clip = VisualTransformer(input_resolution=224,patch_size=32,width=768,layers=12,heads=12,output_dim=512)
为了创建 student 模型,该研究将宽度和层数减少了两倍。由于不确定 head 的数量,该研究定义了两个版本——一个与 teacher 模型的 head 数量相同,另一个版本的 head 数量是 teacher 模型的两倍。这是为了了解增加 head 对模型的性能有什么影响。
student_clip_12_heads = VisualTransformer(input_resolution=224,patch_size=32,width=768//2,layers=12//2,heads=12,output_dim=512)student_clip_24_heads = VisualTransformer(input_resolution=224,patch_size=32,width=768//2,layers=12//2,heads=24,output_dim=512)
该研究首先训练 student_clip_12_heads。
用于训练的数据:该研究首先以从多种来源获取的约 200000 张图像的数据集开始训练。大约 10 个 epoch 之后,一旦开始看到一些有希望的结果,训练数据集就增加到 800000 多张图像。
使用的损失函数:KLD + L1 损失的总和用于训练模型。对于前十个 epoch,温度(temperature)设置为 4,然后降低到 2。
训练完 student_clip_12_heads,该研究微调了 student_clip_24_heads 上的权重。该研究面临的一项主要挑战是收集数据以涵盖各种图像。原始 CLIP 是在 4 亿张图像上训练的。虽然收集如此大规模的图像是不切实际的,但该研究专注于从标准开源数据集收集图像。为了规避对大量图像的需求,该研究还尝试使用 Zero Shot 蒸馏,但没有奏效。
CLIP 中蒸馏 ViT 模型的结果
该研究使用 COCO 测试数据集通过查看每个搜索词的前 20 个结果来查看蒸馏 CLIP 模型的性能,还根据原始 CLIP 和蒸馏 CLIP 的前 N 个结果评估了均值平均精度 (MAP),每个搜索词的 N 的范围从 10 到 20。该研究发现对于每一个 N 值,MAP 大约为 0.012。如此低的值表明原始 CLIP 和蒸馏 CLIP 的结果不会有很多共同的结果。虽然这听起来令人沮丧,但蒸馏 CLIP 模型的结果看起来非常有希望。尽管两种模型都给出了语义上有意义的结果,但快速浏览两种模型的前 20 个结果可以找到 MAP 值很低的原因。
teacher 模型中「bird」一词的结果:
student 模型中「bird」一词的结果:
如上两图所示,尽管两个模型几乎没有产生相同的结果,但每个模型的结果都有意义。
原文链接:https://tech.pic-collage.com/distillation-of-clip-model-and-other-experiments-f8394b7321ce
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《OpenAI CLIP模型袖珍版,24MB实现文本图像匹配,iPhone上可运行》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

