- +1
使用NeMo快速入门NLP、实现机器翻译任务,英伟达专家实战讲解
对话式AI是当前AI领域最火热的细分领域之一,其中自然语言处理(NLP)是最为困难的问题之一。
那么,零基础、对会话式AI感兴趣的小伙伴们如何快速入门 NLP领域?
近日,英伟达x量子位发起的NLP公开课上,英伟达开发者社区经理李奕澎老师分享了【使用NeMo快速入门自然语言处理】,介绍了NLP相关理论知识,并通过代码演示讲解了如何使用NeMo方便地调用NLP函数库及NLP预训练模型,快速完成NLP各类子任务的应用。
以下为分享内容整理,文末附直播回放、课程PPT&代码。
大家好,我是英伟达开发者社区经理李奕澎。今天的课程中,我将首先对自然语言处理(NLP)做出介绍,包括NLP的定义、发展历程、应用场景;然后带大家了解NLP的工作流程及原理;接下来将详细阐述从Word2Vec到Attention注意力机制、从Transformer到BERT模型的内部原理;最后,将通过代码实战介绍如何在NeMo中结合BERT模型,快速实现命名实体识别、机器翻译等任务。
自然语言处理简介
自然语言处理(NLP)是对话式AI场景中的一个子任务。
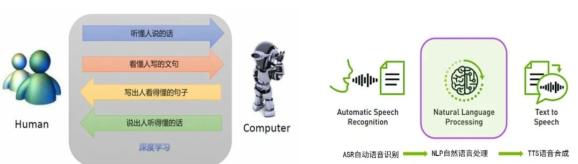
对话式AI本质上是一个人机交互的问题,它让机器能够听懂人说的话、看懂人写的文字,同时机器写出人看得懂的句子、说出人听得懂的话。机器能够“听”的过程,是由自动语音识别(ASR)技术实现的,机器能够“说”的过程,是由语音合成(TTS)技术实现的。
本次课程中,我们将把重心放在如何让机器去理解、懂得人类的语言这一过程,即对话式AI的重中之重—自然语言处理(NLP)技术。
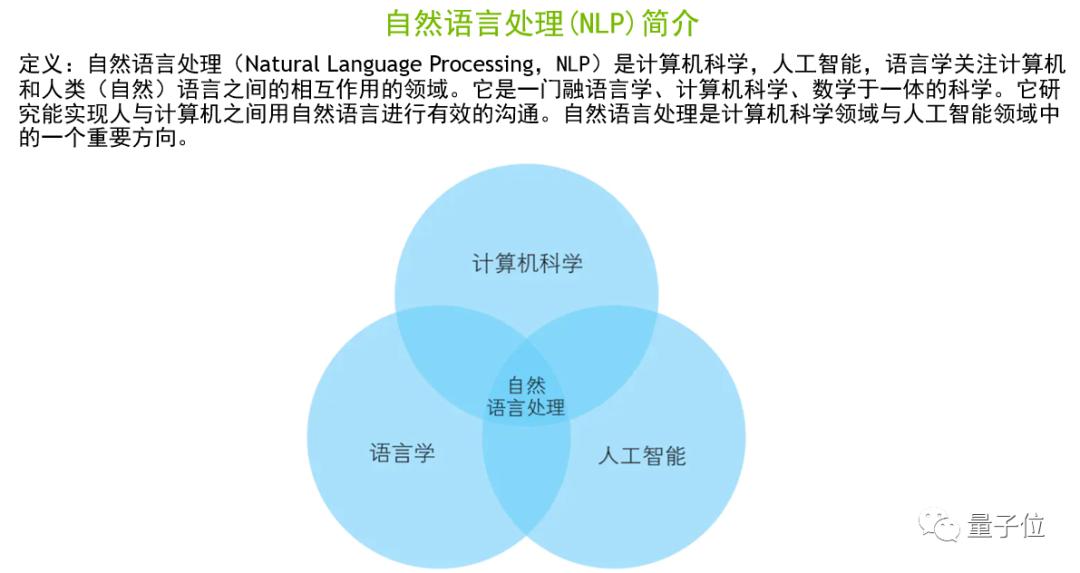
上图是维基百科对NLP的定义。简单来说,NLP是一个语言学、计算机科学、人工智能的交叉学科,其目标是实现人与机器之间有关语义理解方面的有效沟通。
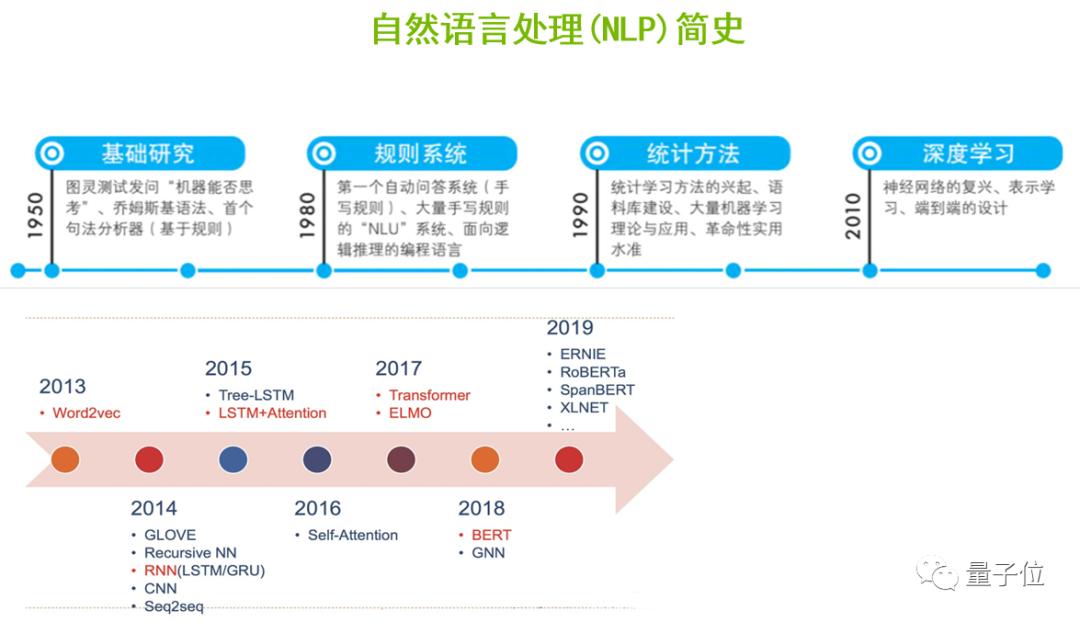
NLP主要经历了5个重要的发展阶段。首先是基础阶段,在1950年从图灵测试发问“机器是否能够思考”开始,研究者就根据乔姆斯基语法,基于规则实现了第一个句法分析器。
1980年,由于基于规则系统的研究不断的发展,第一个基于大量的手写规则的自动问答系统就诞生了。
1990年,随着统计学习方法开始兴起,结合语料库的建设和大量机器学习算法不断的创新和迭代,革命性的应用相继出现。
到了2010年,随着深度学习的崛起、神经网络的复兴,包括文字表示学习、端到端设计等思想的进步,让NLP的应用在效果上得以进一步的提升。
此后,随着2013年Word2Vec算法的出现、2018年划时代的BERT模型的诞生,以及从BERT延伸出来的一系列更优秀的算法,NLP进入黄金时代,在工业界的应用领域、实用性和效果得到了大大的提升,实现了落地和产业化。

NLP的应用领域非常之多,比如文本检索、文本摘要、机器翻译、问答系统、文本分类/情感分析、对话系统、信息抽取、文本聚类、序列标注、知识图谱等,上图介绍了在不同领域的具体应用。
NLP的工作流程和实现原理
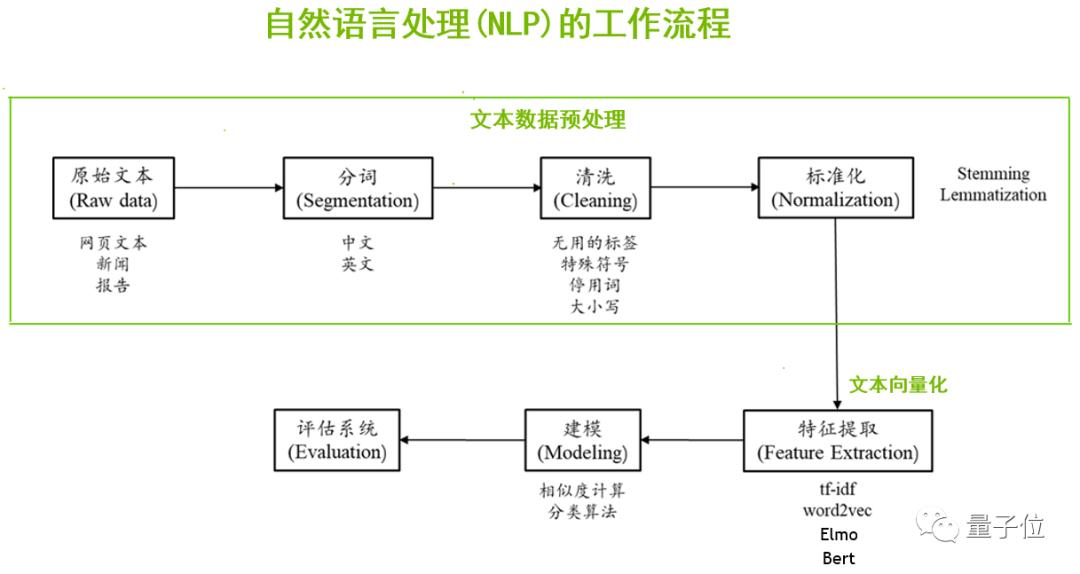
一般来说,当我们拿到一个NLP的项目,首先需要做的是数据预处理,尤其是文本数据预处理。数据的来源比较广泛,可以通过爬虫、开源数据集、各种合作渠道等获得原始的文本数据;我们需要对这些数据进行分词、清洗、标准化等预处理工作。
接下来,我们要让计算机认识这些文本,也就是文本向量化,把人类可读的文字转换成计算机可以认识的、数字化的过程。可以通过tf-idf、Word2Vec、Elmo、BERT等算法提取到文本的词向量。
最后再根据相似度计算、分类算法进行建模,训练模型,并进行推理测试、模型评估、应用部署等。
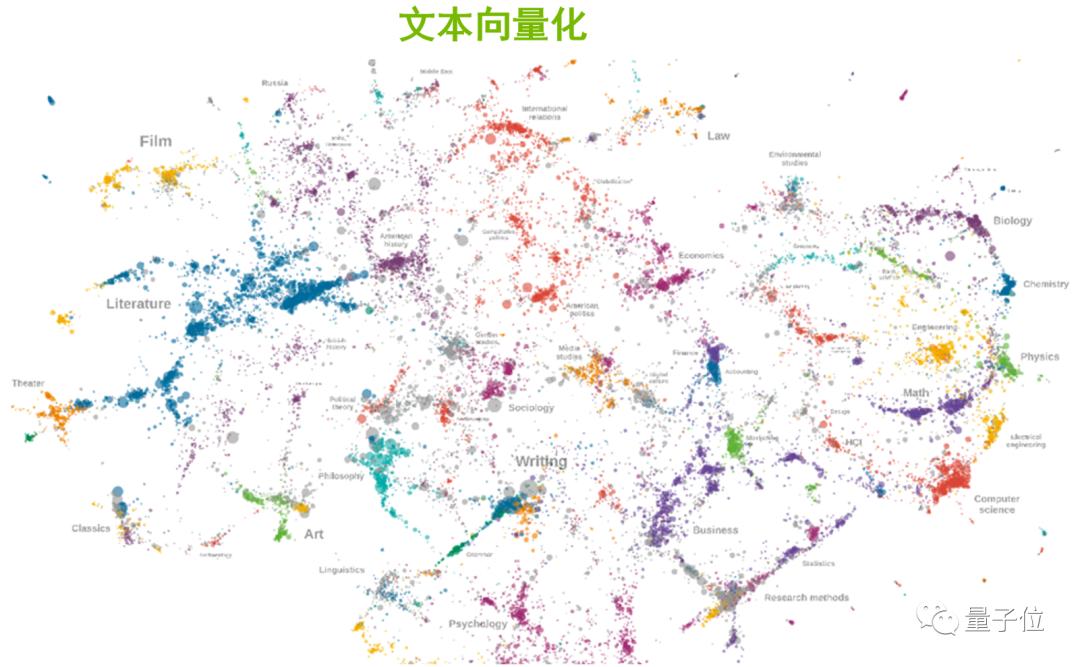
对于其实现原理,比较难理解的是“文本向量化”这一部分,我重点聊一下。俗话说“物以类聚、人以群分”,同样的,对文本进行向量化之后,能够发现属性相近的单词,在向量空间的分布上更加接近。
那么这些单词是怎么实现向量化的?
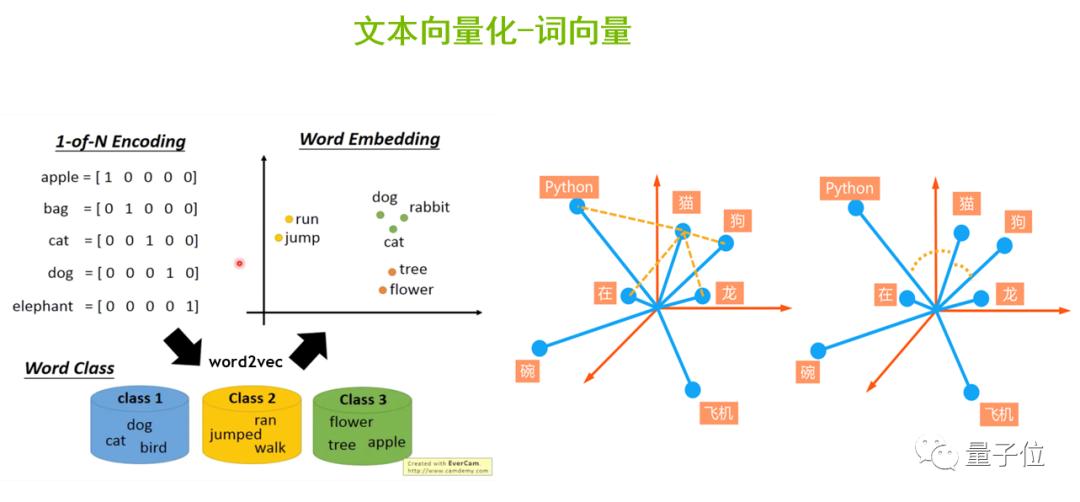
计算机只认识二进制的数据,因此我们需要给语料库中的每一个单词进行编码,从而让计算机可以认识不同的单词,并且进行相关的计算。
我们可以采用Onehot编码,如上图左侧,apple的第一维是1其它是0,bag的第二维是1其它是0,以此类推。但它有一些缺点,一是当语料库非常庞大时,比如100万个单词,这将导致每个单词都需要表示成100万维的向量,这种向量是很稀疏的,不利于计算。二是Onehot编码无法表达相似的单词之间的相似长度,比如说英文单词beautiful和pretty,二者意思相近,但是无法通过Onehot编码的方式表达出来。
为了解决这一问题,我们将Onehot编码作为输入,通过Word2Vec算法对它进行降维压缩,生成更加稠密的词向量,并投射到向量空间中。这样,表示动作的动词run和jump之间的向量位置会比较接近,dog、rabbit、cat等表述动物的名词会离得比较近。
也就是说,通过Word2Vec生成稠密的词向量后,便于我们计算单词间的相似度。
从Word2Vec到Attention注意力机制
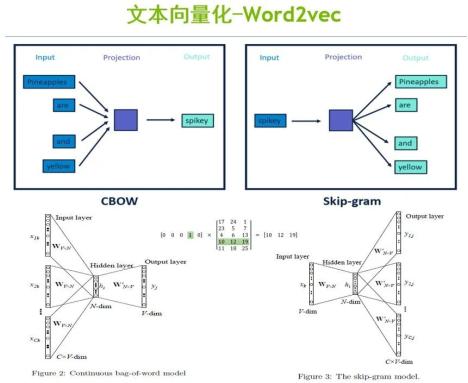
可以说,Word2Vec的出现是NLP领域中非常重要的一个节点,下面简单介绍下。
Word2Vec是连续词袋模型(CBOW)和跳字模型(Skip-Gram)两种算法的结合。
CBOW模型的主要思想是用周围的词、即上下文来预测中间词。比如上图左半部分,首先以pineapples、are、and、yellow这几个词的Onehot编码作为输入,与初始化的权重矩阵进行矩阵相乘,得到n维的向量;然后进行加权平均,把它作为隐藏层的向量h;再用向量h和另外一个初始化的权重矩阵进行矩阵相乘,最后再经过激活函数的处理,就可以得到一个v维的向量y。向量y当中的每一个元素代表了它相对应的每一个单词的概率分布,其中概率最大的元素所指的单词就是我们想要预测的中间词。
而Skip-Gram模型是通过中间词来预测上下文。如上图右半部分,首先是将spikey这个词的Onehot编码作为输入,与初始化的权重矩阵进行矩阵相乘,得到隐藏层的向量h;然后将h与每一个输出单元的初始化权重矩阵进行矩阵相乘,就可以得到输出词及相对的概率。
CBOW与Skip-Gram相结合就是Word2Vec算法,但这种算法也存在一定问题,比如无法解决一词多义的问题,也就是对上下文语义关系的理解还不够深入。
为了解决一词多义的问题,一些更先进的算法,如ELMO、BERT、GPT等算法就相继出现了。
BERT和GPT都是基于Transformer的结构,而Transformer的核心是注意力机制。
举个例子,人类浏览一段手机介绍的文字时,除了注意价格等因素,男性可能会把更多注意力放在性能、技术参数相关字段,女性则更注意外观、颜色等字段。
在NLP中,机器也可以模拟人类的注意力机制,根据信息的重要程度更深入的理解文本。
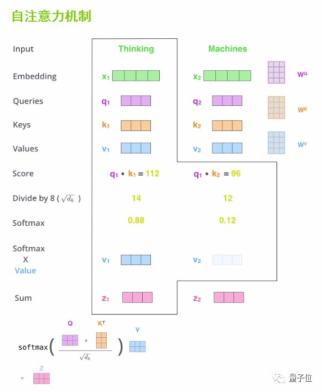
首先介绍下“自注意力机制”的工作流程。
给定两个单词,比如Thinking和Machines,第一步是要输入这两个单词的词向量x1、x2。
第二步,将x1、x2分别与初始化的 q、k、v权重矩阵进行矩阵相乘,得到q1、k1、v1、q2、k2、v2矩阵。其中q矩阵是用来做搜索的,k矩阵是用来被搜索的,v矩阵是值矩阵,是文本内容的本身。
第三步,将q1和k1进行矩阵相乘,将q1和k2进行矩阵相乘,用来计算 Thinking与Machines两个词的相关度,来打出注意力的分数。这个分数就体现了上下文中不同单词间的关联程度。
第四步,为了防止矩阵点乘后的结果过于庞大,这里需做缩放处理和softmax归一化的处理。
第五步,将归一化的结果与值矩阵分别进行点乘,加权求和,就可以得到做完注意力机制之后的z矩阵。
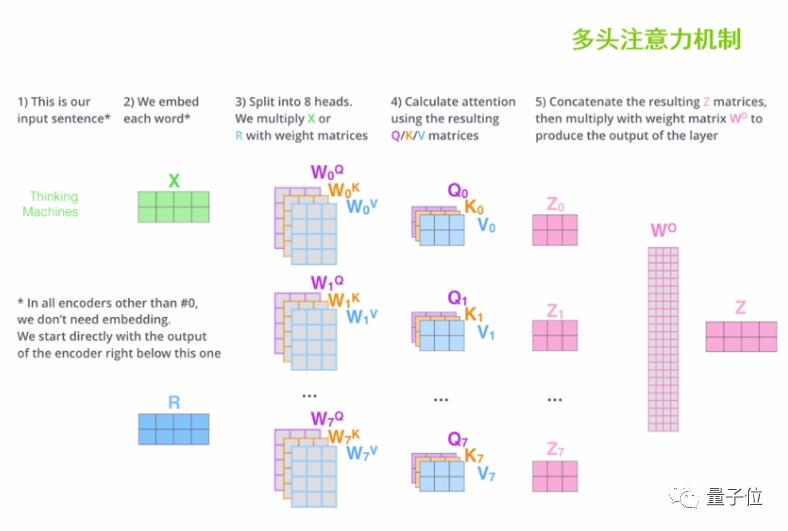
在实际的操作当中,我们可以设置多个自注意力机制的叠加,初始化多个q、k、v权重矩阵参与文本向量的特征提取,也就是“多头注意力机制”。最后把这多个注意力的头拿到的注意力矩阵z进行加权求和,就可以得到最终的注意力矩阵Z,便于后续的计算。
从Transformer结构到BERT模型
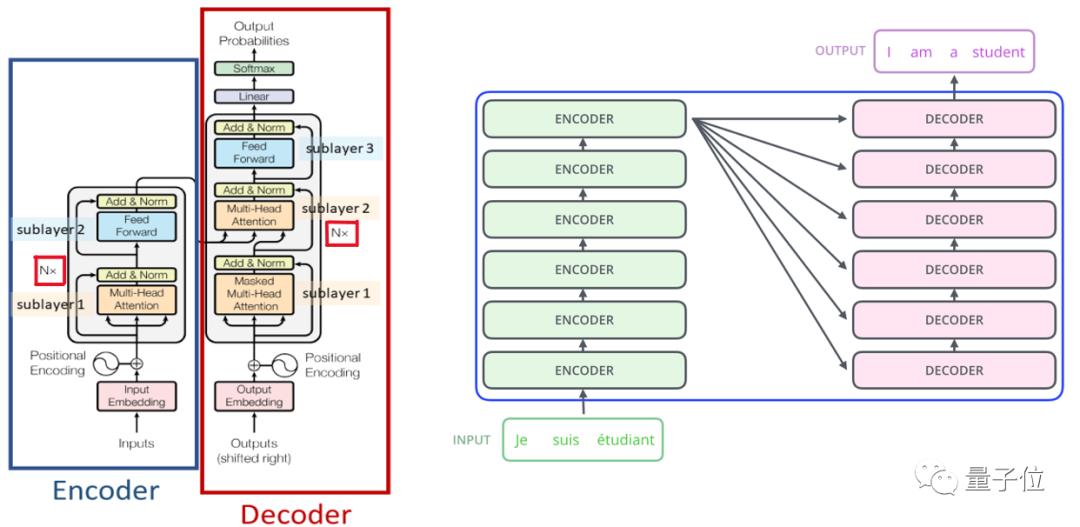
Transformer的核心是注意力机制,下面一起了解下它的内部的结构。
如上图左侧,蓝色框里的Encoder部分是Transformer的编码器,红色框里的Decoder部分是Transformer的解码器。
编码器的输入是词向量本身加上位置嵌入向量形成的向量的和,再经过一层多头注意力机制层,再经历带有残差网络结构的Add&Norm层,就走完了第一个子模块。接下来就进入第二个编码器子模块,先经过一个前馈神经网络层,再接一层基于残差网络结构的Add&Norm层,就完成整体的编码工作。
解码器除了基于注意力机制、考虑自身的文字信息的输入之外,它在第二个解码器子模块中还考虑了编码器的输出结果。
上述就是Transformer的一个编码器和一个解码器的工作流程,实际使用中可以重复n次。Transformer论文发表的作者使用了6个编码器和6个解码器来实现机器翻译的任务,取得了非常不错的效果。
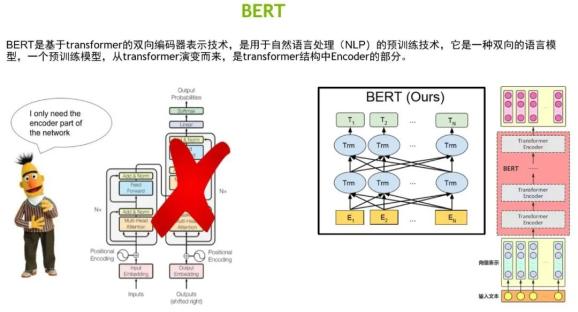
BERT是基于Transformer的双向语言模型,同时也是一个预训练模型。
我们可以将BERT理解成Transformer结构中的编码器,是由多个编码器堆叠而成的信息特征抽取器。BERT有3个重要的特点:
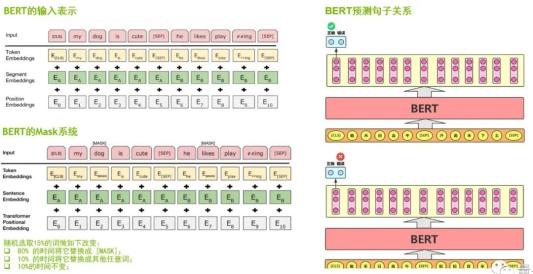
从BERT的输入表示方面来看,BERT的输入既有词嵌入(Token Embeddings),又有位置嵌入(Position Embeddings),同时还加入了分割嵌入(Segment Embeddings),所以BERT的输入是三个Embeddings求和结果。
从BERT的Mask系统来看,它类似于我们做完型填空的任务。给定一个句子,将其中的某个词遮挡起来,让模型根据上下文信息来预测被遮挡起来的词。这样能够让模型对上下文的语义有更深的理解。
第三点是BERT预测句子关系,即句对分类任务,对被打乱顺序的段落进行重新排序,这就需要对整个文章做出充分、准确的理解。因此,我们认为BERT是一个句子级别、甚至文章级别的语言模型,并且在句子分类、问答系统、序列标注、阅读理解等11项 NLP的任务中都取得了非常好的应用效果。
在NeMo中如何使用BERT
BERT模型如此优秀,那么我们如何快速、方便地利用起来呢?接下来我将通过代码实战演示,分享如何在开源工具库NeMo中玩转BERT。
接下来,李老师通过代码演示,分享了如何安装NeMo、如何在NeMo中调用BERT模型,实现命名实体识别、机器翻译等任务。大家可观看视频回放继续学习。
视频链接:https://www.bilibili.com/video/BV1Bq4y1s7xG/
(代码演示部分从第43分钟开始)
代码&课程PPT下载链接:https://pan.baidu.com/s/1AXMv7e0EY8ofzgdm4gy-pQ
提取码: nhk2
下期直播预告
7月14日晚8点第2期课程中,奕澎老师将直播分享使用NeMo快速完成NLP中的信息抽取任务,课程大纲如下:
介绍信息抽取技术理论
介绍命名实体识别(NER)
构建适合NeMo的自定义NER数据集
介绍NeMo中的信息抽取模型
代码演示:使用NeMo快速完成NER任务
直播报名:
扫码-关注“NVIDIA开发者社区”,并根据提示完成报名:
△请准确填写您的邮箱、便于接收直播提醒&课程资料哦~
— 完 —
原标题:《使用NeMo快速入门NLP、实现机器翻译任务,英伟达专家实战讲解,内附代码》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

