- +1
加入联邦学习的客户端设备——随机选择真的好吗?
原创 Jiying 机器之心
机器之心分析师网络
作者:Jiying
编辑:H4O
本文选择了 6 篇研究进展进行深入分析,以了解通过控制和选择参与训练的客户端究竟会对 FL 产生什么样的影响。
现代移动和物联网设备(如智能手机、智能可穿戴设备、智能家居设备)每天都在产生海量数据,这为破解复杂的机器学习模型提供了机会,以解决具有挑战性的 AI 任务。在传统的高性能计算 (HPC) 中,收集所有数据后集中存储在一个位置,并由拥有数百到数千个计算节点的超级计算机进行处理。然而,这种集中数据处理的方式带来了数据安全性和隐私性方面的问题,分散存储的数据给传统高性能计算带来了困难。
联邦学习(Federated learning,FL)是一种机器学习环境,在这种环境下,多个客户端(如移动设备或整个组织)在中央服务器(如服务提供商)的协调下协同训练一个模型,同时保持训练数据的分散性。FL 体现了集中数据收集和最小化的原则,可以减轻传统的集中式机器学习和数据科学方法带来的许多隐私、安全性风险和成本[1]。因此,FL 是一种有效的高性能计算范式。目前,FL 已经在一些应用场景中成功使用,包括一些消费端设备,例如 GBoard、关键词发现,以及制药、医学研究、金融、制造业等等。此外,也出现了大量 FL 开发工具和平台,例如 Tensorow Federated, LEAF, PaddleFL 和 PySy,进一步推动 FL 的发展。
如图 1 所示[2],FL 迭代地要求随机选定的客户端执行下述步骤:1)从中央服务器下载可训练模型的参数,2)根据自己的本地数据更新模型,3)将新的模型参数上传到中央服务器,同时要求中央服务器执行步骤:4)汇总多个客户端的更新,进一步改进模型。在 FL 环境中,客户端部署有一定的计算资源(如配备 GPU 的笔记本电脑、手机、计算能力适中的自动驾驶车辆等等),FL 协议允许客户端在本地存储数据[2]。
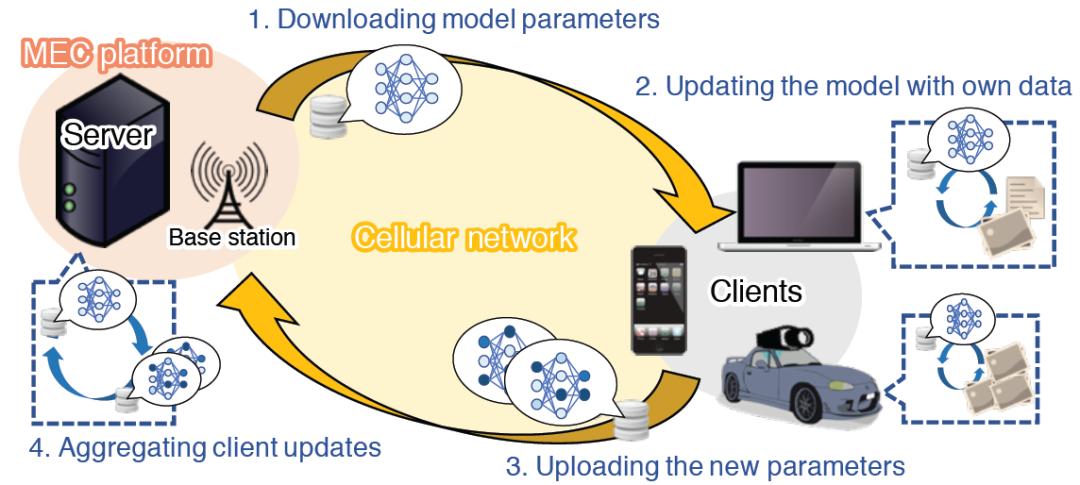 图 1. FL 使人们能够通过中央服务器和客户端之间的模型参数迭代通信,在私有客户端数据上训练机器学习模型[2]
图 1. FL 使人们能够通过中央服务器和客户端之间的模型参数迭代通信,在私有客户端数据上训练机器学习模型[2]在现有的 FL 系统中,参与每一轮更新的客户端数量通常是固定的。最初的 FL 系统假设全部客户端都完全参与,即所有客户端都参与了每一轮的训练。而在实际应用中,受限于客户端状态、网络条件等,FL 的实施方案在每轮训练中只是随机选择一小部分客户端参与。但是,由于在 FL 环境中存在大量的异构客户端(Heterogeneous client),这种 随机选择客户端的方式会加剧数据异质性的不利影响 。FL 环境中的异构性主要包括:(1)各个客户端设备在存储、计算和通信能力方面存在异构性;(2) 各个客户端设备中本地数据的非独立同分布(Non-Idependently and Identically Distributed,Non-IID)所导致的数据异构性问题;(3)各个客户端设备根据其应用场景所需要的模型异构性问题。客户端设备存在的这些异构性往往会影响全局模型的训练效率,客户端可能无法同时接受 FL 训练或测试。例如,当一些客户端的计算资源有限时,他们需要更长的时间来更新模型。此外,如果客户端的无线信道条件不好,也会导致更新时间延长。所有这些问题都会延迟后续中央服务器继续训练过程所需的聚合步骤。
越来越多的研究人员开始关注这样一个问题:是否能够选择 “优秀” 的客户端子集参与每轮的训练 ?然而,客户端选择是一项非常有挑战性的任务,因为要 在不同客户端和任何特定客户端的异构系统和统计模型效用之间进行权衡 。我们选择了 6 项研究进展进行深入分析,以了解通过控制和选择参与训练的客户端究竟会对 FL 产生什么样的影响。
第一篇文章提出了一种基于层级的联邦学习系统(A Tier-based Federated Learning System,TiFL),其核心是在每轮训练过程中自适应地选择训练时间相近的客户端参与到训练中,从而在不影响模型准确度的情况下缓解客户端数据异质性问题[3]。这篇文章中,作者通过理论分析和实验验证了随机选择客户端的策略对 FL 性能的影响,能够帮助我们快速和清晰的了解该问题。
第二篇文章在每轮训练中只识别和传输被认为是信息量大(例如,该过程距离其稳定状态还有多远)的客户端更新,从而减轻 FL 传输压力[4]。这篇文章的研究出发点是减小联邦学习中的通信开销,而作者发现减少开销同时能够保证模型准确度的一个有效方法就是:选择每轮参与更新的客户端。
第三篇文章提出了一个参与者选择框架(Oort),可以识别和挑选有价值的客户端进行 FL 训练和测试[5]。
第四篇文章提出了一个基于强化学习的经验驱动的联邦学习框架(Favor),它可以智能地选择参与每轮联邦学习的客户端设备,以抵消非独立同分布数据(Non-IID)引入的偏差,并加快收敛速度[6]。
第五篇文章中提出了一个混合式联邦学习框架(Hybrid Federated Learning ,HFL),该框架包括一个同步内核和一个异步更新器,其主要目的是当 FL 环境中存在 stragglers 时增强 FL 的学习性能[7]。与经典联邦学习类似,同步内核局部更新序列的加权求和。异步更新器将 stragglers 的模型更新纳入到联邦模型训练过程中,这些 stragglers 可能比同步内核晚几步。
最后一篇文章针对有偏客户端选择的联邦学习进行了收敛性分析。作者发现,偏向选择本地损失较高的客户端会提高整个模型的收敛速度。同时,作者提出了一种 Power-of-Choice 的客户端选择方法[9]。
我们在本文最后对联邦学习的客户端选择问题进行了总结和讨论。
1 基于层级的联邦学习系统[3]
 本文是第 29 届国际高性能并行与分布式计算会议(HPDC '20)中的一篇文章。作者首先量化分析了客户端数据和资源异质性如何影响经典 FL 的训练性能和模型准确度。然后,作者提出了 TiFL(Tier-based Federated Learning),一个基于层级(Tier)的联邦学习系统。TiFL 的关键思想是自适应地选择每轮训练时间相近的客户端,这样就可以在不影响模型准确度的情况下解决数据异质性问题。
本文是第 29 届国际高性能并行与分布式计算会议(HPDC '20)中的一篇文章。作者首先量化分析了客户端数据和资源异质性如何影响经典 FL 的训练性能和模型准确度。然后,作者提出了 TiFL(Tier-based Federated Learning),一个基于层级(Tier)的联邦学习系统。TiFL 的关键思想是自适应地选择每轮训练时间相近的客户端,这样就可以在不影响模型准确度的情况下解决数据异质性问题。1.1 量化分析
在经典 FL 问题中,参与训练的客户端之间的资源和数据异质性可能会导致客户端不同的响应延迟(即客户端接收训练任务到返回结果的时间),这通常被称为掉队者问题(Straggler problem)。令客户端 c_i 的响应延迟为 L_i,则全局训练模型的延迟为:
其中,L_r 表示第 r 轮的延迟。我们可以看出,一轮全局训练的延迟是由客户端中的最大训练响应延迟,即最慢的客户端决定的。作者将客户端划为τ个层级(Tier),相同层级的客户端响应延迟相差不大。在经典 FL 的聚合过程中,随机选择客户端从而形成一个由多个客户端层级组成的客户端群。除最慢层级的客户端τ_m 之外的客户端层级中选择 | C | 个客户端的概率为:
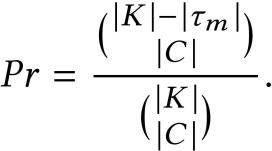 据此,C 中至少有一个客户端来自τ_m 的概率可以表述为:
据此,C 中至少有一个客户端来自τ_m 的概率可以表述为:作者对 Pr_s 进行了拆分计算如下:
 由于具有如下约束:
由于具有如下约束:所以,Pr_s 满足:
 在真实场景中,每一轮都会有大量的客户端被选中,这使得 | K | 非常大,可得 Pr_s≈1。因此,每轮从最慢层级中至少选择一个客户端的概率是相当高的。因此,随机选择客户端的策略可能会导致全局模型训练性能缓慢 。
在真实场景中,每一轮都会有大量的客户端被选中,这使得 | K | 非常大,可得 Pr_s≈1。因此,每轮从最慢层级中至少选择一个客户端的概率是相当高的。因此,随机选择客户端的策略可能会导致全局模型训练性能缓慢 。为了进一步验证这一推断,作者进行了量化实验。实验环境如下:
共使用 20 个客户端,每个客户端又分为 5 组,每组 4 个客户端。
为第 1 组到第 5 组的每个客户端分别分配了 4 个 CPU、2 个 CPU、1 个 CPU、1/3 个 CPU、1/5 个 CPU,以模拟数据资源的异质性。
模型在图像分类数据集 CIFAR10 上使用 FL 进行训练。
对每个客户端进行不同数据大小的实验,得出数据异质性结果。
实验结果见图 2。如图 2(a)所示,在 CPU 资源量相同的情况下,将数据量从 500 增加到 5000,每轮的训练时间几乎呈线性增长。随着分配给每个客户端的 CPU 资源量的增加,训练时间越来越短。另外,在 CPU 数量相同的情况下,随着数据数量的增加,训练时间也会增加。这些初步结果表明,在复杂异构的 FL 环境下,杂散问题可能会很严重。
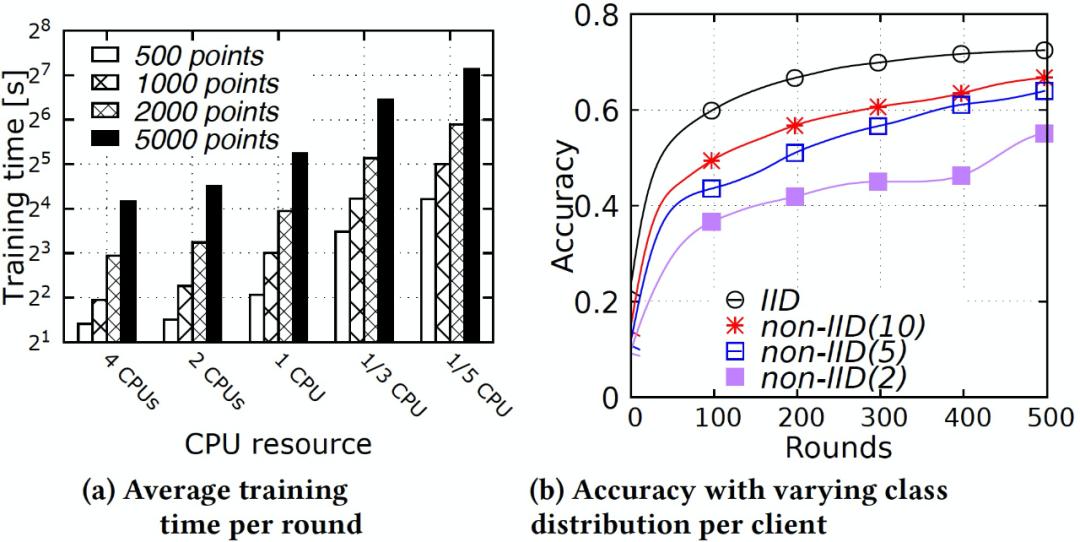 图 2. (a)每轮训练时间 (对数比例) 与资源和数据量异质性;(b)每个客户端 (No-IID) 不同类数下的准确性
图 2. (a)每轮训练时间 (对数比例) 与资源和数据量异质性;(b)每个客户端 (No-IID) 不同类数下的准确性为了评估数据分布异质性的影响,作者为每个客户端保持相同的 CPU 资源 (即 2 个 CPU),并生成一个有偏差的类和特征分布。具体来说,以这样的方式分布数据集,每个客户端分别从 2(No-IID(2))、5(No-IID(5))和 10(No-IID(10))类中获得相等数量的图像。由图 2(b) 中可以看出,不同的 No-IID 分布在准确度上有明显的差异。IID 情况下准确度最高,因为它代表了统一的类和特征分布。随着每个客户端的类数减少,我们观察到准确度也会相应降低。
这些研究表明,数据和资源的异质性会对 FL 的训练时间和训练准确度造成明显影响。
1.2 TiFL
1.2.1 整体架构
基于层级(Tier)的系统的关键思想是,考虑到一轮的全局训练时间是由该轮选择的最慢的客户端所约束的,在每一轮中选择响应延迟相近的客户端可以明显减少训练时间 。TiFL 的整体系统架构如图 3 所示。TiFL 沿用了最新的 FL 系统设计,并增加了两个新的组件:分层模块和分层调度器。新增加的组件可以纳入到现有 FL 系统的协调器中。值得注意的是,在图 3 中,我们只展示了一个单一的聚合器(aggregator),而不是分层的主子聚合器设计,以达到简洁的展示目的。TiFL 支持主 - 子聚合器设计,以实现可扩展性和容错性。
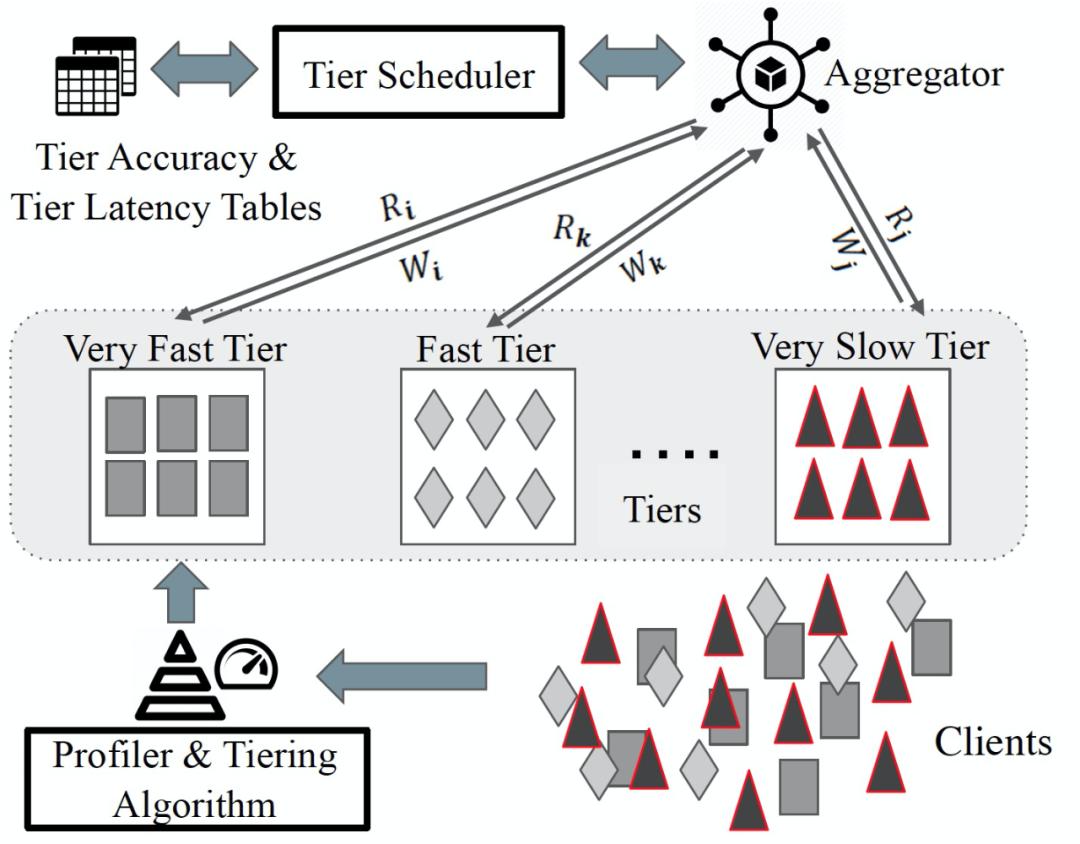 图 3. TiFL 整体架构
图 3. TiFL 整体架构在 TiFL 中,第一步是通过轻量级的 Profiling 收集所有可用客户端的延迟指标。分层算法会进一步利用这些数据将客户端分成独立的逻辑池(Logical pools),称为分层(tiers)。一旦调度器掌握了分层信息(即客户端所属的层级和层级的平均响应延迟),训练过程开始。与采用随机客户端选择策略的 FL 不同,TiFL 中调度器选择一个层级,然后从该层级中随机选择目标数量的客户端。选定客户端后,训练就像最新的 FL 系统一样进行。此外,TiFL 是非侵入式的,可以很容易地嵌入到任何现有的 FL 系统中,因为分层和调度模块只是简单地控制客户端的选择,并不会干预底层的训练过程。
1.2.2 剖析和分层(Profiling and Tiering)
鉴于一轮的全局训练时间是由该轮选择的最慢的客户端所约束的,如果我们能在每一轮中选择具有相似响应延迟的客户端,就可以改善训练时间。然而,在 FL 中,响应延迟是先验未知的,这使得上述想法的实施具有挑战性。为了解决这一挑战,作者引入了一个过程,通过 Profiling 和 Tiering 模块对客户端进行分层(分组),如图 3 所示。
对于第 r 步,初始化所有可用的客户端,响应延迟 L_i 为 0。然后,Profiling 和 Tiering 模块为所有可用的客户端分配 Profiling 任务。Profiling 任务执行 sync_rounds,在每个 Profiling 轮次中,聚合器要求每个客户端在本地数据上进行训练,并等待它们的确认,时间为 T_max 秒。所有在 T_max 秒内响应的客户端其响应延迟值 RT_i 随实际训练时间递增,而超时的客户端则按 T_max 递增。sync _rounds 轮结束后,将 L_i>=sync _rounds*T_max 的客户端全部丢弃并不会纳入后续的计算。收集到的客户端的训练延迟形成一个直方图,直方图被分成 m 个组,属于同一组的客户端构成一个层级。然后计算每组的平均响应延迟,并持续记录下来,稍后用于调度和选择层级。对于计算和通信性能随时间变化的系统,可以定期进行 Profiling 和 Tiering,以便将客户端调整到合适的层级。
1.2.3 Straw-man Proposal: 静态层级选择算法
本节作者提出了一种基于静态分层的客户端选择策略,并讨论了它的局限性,以进一步开发一种先进的自适应分层选择算法。上面提到的 Profiling 和 Tiering 模块根据响应延迟将客户端分为 m 个层级,而分层选择算法的重点是如何在 FL 过程中从合适的层级中选择客户端,以提高训练性能。提高训练时间的方法是优先向更快的层级倾斜,而不是从所有层级中随机选择客户端。然而,这种选择方法减少了训练时间,却没有考虑到模型的准确度和隐私特性。作者提出可以指定在每个层级 n_j 中根据一个预定义的概率进行选择,所有层级的概率之和为 1。在每个层级内,统一随机选取 | C | 个客户端。
在真实世界的 FL 应用场景中,客户端数量通常非常巨大。所以在本文的选择算法中,选取的层级数量 m 远小于 | K|,每个层级 n_j 的客户端数量通常大于 | C|。层级的选择概率是可控的,这就会产生不同的权衡。如果用户的目标是减少整体训练时间,他们可能会增加选择更快的层级的机会。然而,由于不同的客户端可能拥有分布在不同层级的异质性训练数据,只从最快的层级中抽取客户端不可避免地会引入训练偏差,这种偏差可能最终影响全局模型的准确性。作者表示,为了避免这种数据偏差问题,最好引入来自不同层级的客户端,以便覆盖不同的训练数据集。
1.2.4 自适应分层选择算法
作者提出了一种自适应分层选择算法,可以自动在训练时间和准确度之间取得平衡,并根据系统条件的变化,在训练轮次中自适应地调整选择概率。整体目标是使训练模型的偏差最小化,因此可以在整个训练过程中监控各层模型的准确性。t 层的准确度值越低,表明在训练过程中该层的参与度越低,因此 t 层在下一轮训练中的贡献应该越大 。为了达到这个目的,作者提出可以增加准确度较低的层级的选择概率。此外,为了保证训练时间,我们还需要限制各轮训练中对较慢层的选择。因此,作者引入了 一个用来表示某个层级可以被选择多少次的限制条件 Credits_t。
具体来说,一个层级是以相等的选择概率随机初始化的。在接收到权重并更新全局模型后,全局模型在每个客户端上对各自测试数据上的每个层级进行评估,并将其得出的准确度存储为对应层级 t 的该轮准确率 r。将其存储为 (A_t)^r,训练回合中所有客户端的平均准确率为 r 。在后续的训练轮次中,自适应算法根据每 I 轮次中各层的测试准确度更新各层的概率。函数 ChangeProbs 调整概率,使较低的准确度层获得较高的概率而被选中进行训练。然后根据新的层级选择概率(NewProbs) 从所有可用的层级τ中选择一个有 Credits_t 的层级。被选中的层级将被降低 Credits_t。当某个层级的客户端在整个训练过程中一次次被选中时,该层级的 Credits_t 最终会降为零,也就是说以后不会再被选中。这可以作为层级选择次数的控制旋钮。通过设置这个上限,我们可以限制慢速层级贡献训练的次数,从而获得一定的控制权。由于我们现在希望自适应地改变概率,我们添加了 Credits_t 来获得对限制训练时间的控制。
TiFL 的自适应分层选择算法具有数据异质性意识,因此,TiFL 在进行分层选择决策时会考虑到潜在的数据库选择偏差问题,并随着时间的推移自动调整分层选择概率。另一方面,引入 Credits_t,通过对选择相对较慢的层级实施约束来干预整体训练时间。完整算法如 Algorithm 2。
 1.3 实验分析
1.3 实验分析1.3.1 实验设置
首先,作者在一个 CPU 集群上部署 50 个客户端,其中每个客户端都有自己的专属 CPU(s),使用 TensorFlow 为合成数据库建立了一个 FL 测试平台。在每一轮训练中,选择 5 个客户端根据本地数据库进行训练,并将训练后的权重发送给中央服务器,中央服务器将其聚合并更新全局模型。在本文使用的原型中,作者使用了一个强大的单一聚合器可以将多层聚合器集成到 TiFL 中,以确保系统不存在可扩展性和容错性问题。
此外,作者还以同样的方式扩展了被广泛采用的大规模分布式 FL 框架 LEAF。LEAF 提供 Non-IID 和类分布异质性数据。LEAF 框架并不能提供客户端之间的资源异质性,这也是真实应用 FL 系统的普遍具有的关键属性之一。目前 LEAF 框架实现的是对 FL 系统的模拟,本质上 LEAF 的客户端和 FL 中央服务器是运行在同一台物理机器上的。为了引入资源的异质性,作者首先扩展 LEAF 以支持分布式 FL,每个客户端和聚合器都可以在不同的设备上运行并通过网络进行交互,使之成为一个真正的分布式系统。接下来,作者为聚合器和客户端单独分配了专用硬件并完成了部署。每个客户端的资源分配是通过统一的随机分布来完成的,从而使每个硬件类型的客户端数量相等。通过增加资源异构性并将其部署到独立的硬件上,每个客户端都可以模拟真实世界的边缘设备。鉴于 LEAF 自身已经提供了数据 Non-IID 性,通过新增加的资源异构性功能,该框架提供了一个真实世界的 FL 系统,它支持数据数量、质量和资源异构性。
作者使用四个图像分类应用来评估 TiFL。作者使用 MNIST 和 FashionMNIST,其中每个包含 60000 张训练图像和 10000 张测试图像,每张图像的像素为 28x28。作者对这两个数据库都使用了 CNN 模型,首先是 32 个通道和 ReLU 激活的 3x3 卷积层,然后是 64 个通道和 ReLu 激活的 3x3 卷积层,大小为 2x2 的 MaxPooling 层,128 个单元和 ReLu 激活的全连接层,以及 10 个单元和 ReLu 激活的全连接层。Dropout0.25 加在 MaxPooling 层之后,Dropout0.5 加在最后一个全连接层之前。作者还使用了 Cifar10,与 MNIST 和 FashionMNIST 相比,Cifar10 包含了更丰富的功能。Cifar10 共有 60,000 张彩色图像,其中每张图像有 32x32 像素。完整的数据库被平均分成 10 个类,并被分割成 50,000 张训练图像和 10,000 张测试图像。该模型是一个四层卷积网络,在 softmax 层之前以两个全连接的层结束。它是以 Dropout0.25 进行训练的。最后,作者还使用了 LEAF 框架的 FEMNIST 数据库。这是一个由 62 个类组成的图像分类数据库,该数据库本质上是 Non-IID 的,数据量和类分布具有异质性。作者在实验中使用的是 LEAF 中提供的标准模型架构。
在所有的客户端中,作者将他们分成 5 组,每组客户端数量相等。对于 MNIST 和 FashionMNIST,每组分别分配 2 个 CPU、1 个 CPU、0.75CPU、0.5CPU、0.25CPU。对于较大的 Cifar10 和 FEMINIST 模型,每组分别分配 4 个 CPU、2 个 CPU、1 个 CPU、0.5 个 CPU 和 0.1 个 CPU。这中分配方式最终会导致属于不同组的客户端的训练时间不同。利用 TiFL 的分层算法,共分为 5 个层级。
1.3.2 实验结果分析
作者评估了所提出的基于层级的 FL 的几种不同调度政策,具体策略由每个层级的选择概率来定义,并与经典的 FL 进行比较。将经典的每轮从所有客户端中随机抽取 5 个客户端的方法定义为 vanilla。fast 是指 TiFL 每轮只选择最快的客户端的策略。random 表征选择最快的层级优先于较慢层级的情况。uniform 是指基于层级的基本选择策略,其中每个层级被选中的概率相等。对于 MNIST 和 FashionMNIST,考虑到它是一个更轻量级的工作负载,作者重点展示了当策略更积极地优先考虑快速层级时的敏感性分析,即从 fast1 到 fast3,其中最慢层级的选择概率从 0.1 降低到 0,而所有其他层的概率相同。slow 对应最差的策略,TiFL 只从最慢的层级中选择客户端。作者在实验中将其列入参考,以便明确基于静态层级选择方法的最佳情况和最差情况之间的性能范围。表 1 中给出全部策略的详细信息。
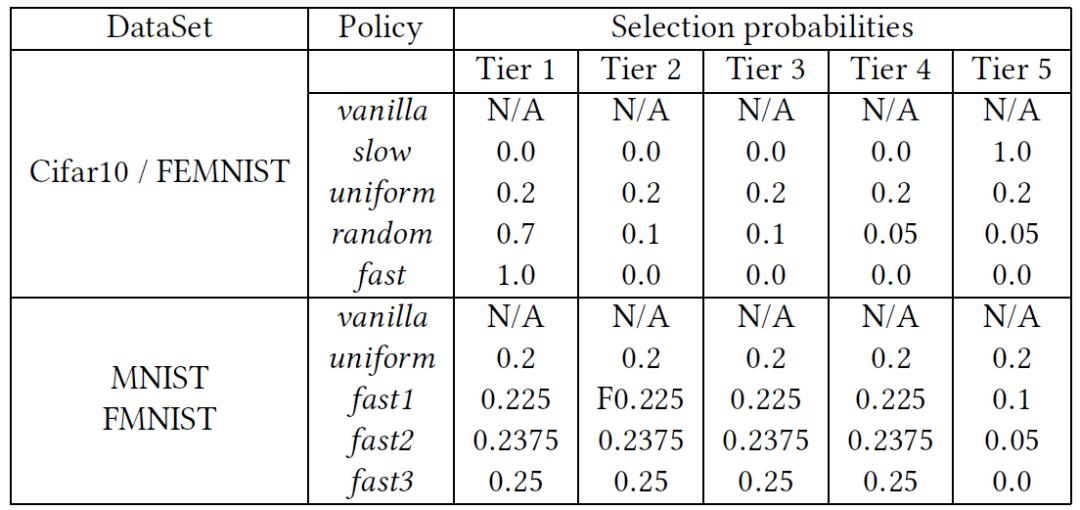 表 1. 调度策略详情
表 1. 调度策略详情首先,作者评估了 TiFL 在资源异构环境下的训练时间和模型准确度方面的性能。在实际应用中,数据异质在 FL 中是一种常态,我们评估这个方案的目的是验证 TiFL 是如何应对数据资源异质性问题的。作者同时评估了存在资源和数据异质性的方案。图 4 中(第 1 列)的实验结果表明,当我们优先考虑快速层时,训练时间明显减少。从图中我们还可以看出,即使是 uniform 也比 vanilla 有超过 6 倍的改进。作者分析,这是因为在 uniform 中训练时间总是被每轮训练中选择的最慢的客户端所约束。图 4(c)显示不同策略之间的准确度差异非常小,在 500 轮循环过后小于 3.71%。然而,如果我们看一下挂钟时间(Wall clock)上的准确度,与 vanilla 相比,TiFL 获得了更高的准确度。也就是说,如果训练时间受到限制,TiFL 的准确度最高可提高 6.19%,这要归功于 TiFL 带来的更快的每轮训练时间,见图 4(e)。这里需要注意的是,不同策略完成 500 轮训练所需的挂钟时间可能大不相同。图 4(列 2)给出了数据量异质性的实验结果。从图 4(b)中的训练时间对比来看,TiFL 在只有数据量异质性的情况下也是有改进的,实现了 3 倍的加速。作者分析,这是因为数据量的异质性也可能导致不同的训练时间,这与资源异质性有着相似的效果。
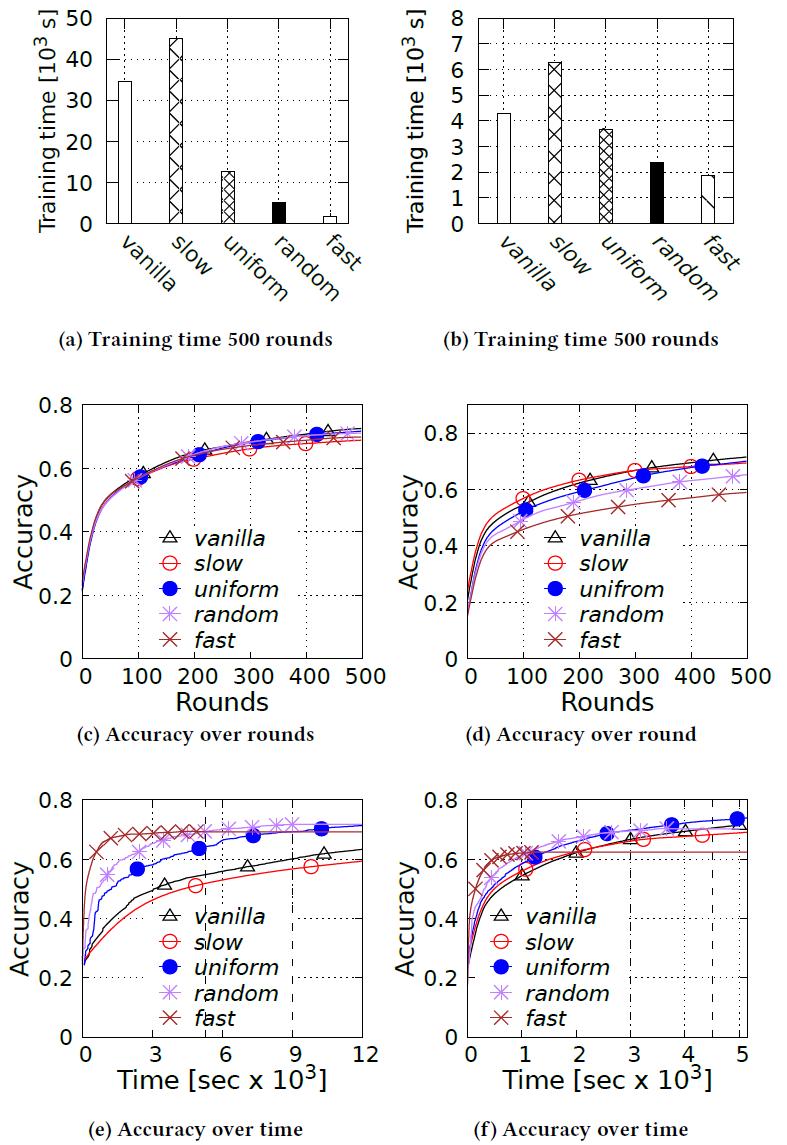 图 4. 资源异质性(列 1)和数据量异质性(列 2)的 Cifar10 上不同选择策略的比较结果
图 4. 资源异质性(列 1)和数据量异质性(列 2)的 Cifar10 上不同选择策略的比较结果图 5 给出了关于非独立同分布(No-IID)数据异质性的实验结果。作者表示,No-IID 异质性并不影响训练时间。因此,作者在文中没有给出实验结果。然而,No-IID 异质性影响了模型准确度。图 5 显示了在 No-IID 中每个客户端给定 2、5、10 个类的轮次准确度。同时图中也给出了 IID 的结果。这些结果表明,随着 No-IID 异质性水平的增加,由于训练数据的强烈偏差,对所有策略的准确性影响也会增大。此外,由于 vanilla 是一种无偏见的选择策略,与其它策略相比它具有更好的弹性,这有助于最大限度地减少客户端选择过程中进一步引入的偏见。
 图 5. 在 No-IID 异质性(Class)和固定资源水平不同的情况下,Cifar10 上不同选择策略的比较结果
图 5. 在 No-IID 异质性(Class)和固定资源水平不同的情况下,Cifar10 上不同选择策略的比较结果最后,作者评估了所提出的 TiFL 自适应分层选择方法,该方法在做出调度决策时考虑了资源和数据的异质性而不侵犯隐私。作者将自适应选择方法与 vanilla 和 uniform 进行了比较,后者是准确度表现最好的静态策略。图 6 显示,由于采用了数据异质性感知方案,在数据数量异质性 (Amount) 和 No-IID 异质性 (Class) 的资源异质性方面,自适应策略在训练时间和准确度上都优于 vanilla 和 uniform。在结合资源和数据异质性的情况下(Combine),自适应策略用了近一半的训练时间就达到了与 vanilla 相当的准确度。而与 uniform 相比较,二者在训练时间上表现相似,自适应策略的准确度有明显提高。
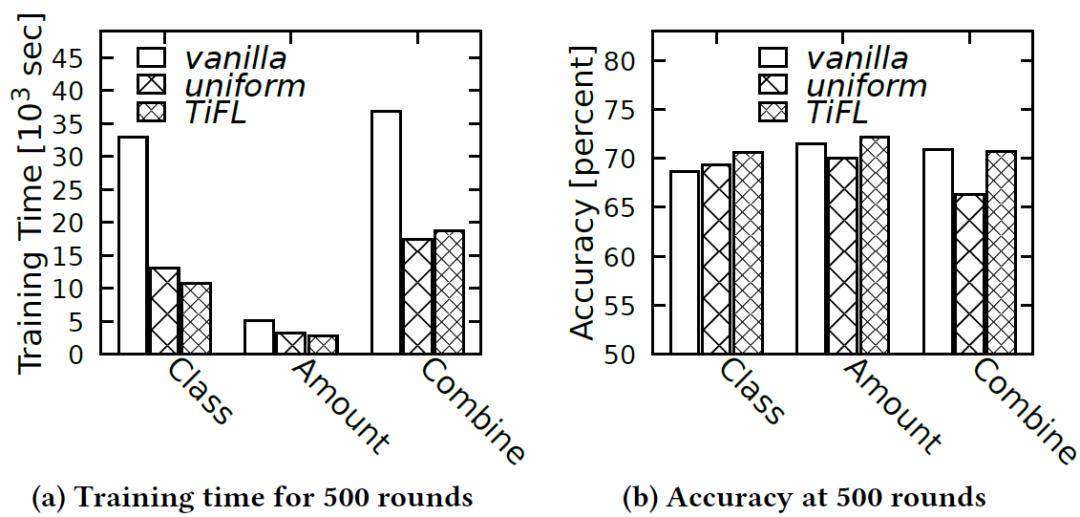 图 6. Cifar10 上不同选择策略的对比结果,包括数据量异质性(Amount)、No-IID 异质性(Class)、资源和数据异质性(Combine)
图 6. Cifar10 上不同选择策略的对比结果,包括数据量异质性(Amount)、No-IID 异质性(Class)、资源和数据异质性(Combine)2 通过优化客户端采样实现高效通信的联邦学习[4]
 本文是一篇 ArXiv 预印文章。在经典 FL 问题中,客户端在本地进行训练并将学习到的模型发送给中央服务器。为实现本地模型的聚合需要在客户端和中央服务器之间频繁地进行大量的信息沟通,因而造成了较大的通信负荷。本文的关注点是“高效通信的联邦学习(Communication-Efficient Federated Learning)”。作者提出了一种简单、高效的在通信约束环境下更新全局模型的方法:从有信息更新的客户端中收集模型,并估计没有进行通信的客户端中的局部更新。
本文是一篇 ArXiv 预印文章。在经典 FL 问题中,客户端在本地进行训练并将学习到的模型发送给中央服务器。为实现本地模型的聚合需要在客户端和中央服务器之间频繁地进行大量的信息沟通,因而造成了较大的通信负荷。本文的关注点是“高效通信的联邦学习(Communication-Efficient Federated Learning)”。作者提出了一种简单、高效的在通信约束环境下更新全局模型的方法:从有信息更新的客户端中收集模型,并估计没有进行通信的客户端中的局部更新。2.1 方法介绍
为了在减少客户端与中央服务器间通信的同时提高模型准确度,作者将从最佳过程中采样(Optimal process sampling)的技术引入到 FL 系统中。作者提出了一种策略,即只有当客户端的模型更新的范数超过一个预先确定的通信阈值时(表征有信息更新),客户端才会将其计算得到的模型权重传送给中央服务器。此外,本文还提出了一个针对不满足通信阈值的模型更新的 non-trival 估计器。
给定一个损失函数:
其中,X 是有 N 个样本的数据库,l_i(θ)为数据 x_i 的损失。在梯度下降过程中,通过使用一个 mini-batch S 评估每轮梯度估计来最小化 L:
根据已知的一些数学规律(详见原文推导证明过程),上式的离散过程可写作:
其中,B(θ)B(θ)^T 表示协方差矩阵,I 为单位矩阵,η为迭代步长。上式可以解释为对 OU 过程(Ornstein-Uhlenbeck Process)进行离散化处理得到的:
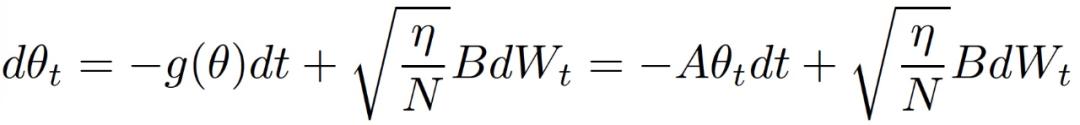 Ornstein-Uhlenbeck 过程 (OU) 是一个静止的高斯 - 马尔科夫过程(a stationary Gauss-Markov process),随着时间的推移,它向其平均函数漂移。与 Wiener 过程的漂移是恒定的不同,OU 过程的漂移取决于其当前实现与平均值的距离。形式上,OU 过程{x_t}_t 可以用随机微分方程来描述:
Ornstein-Uhlenbeck 过程 (OU) 是一个静止的高斯 - 马尔科夫过程(a stationary Gauss-Markov process),随着时间的推移,它向其平均函数漂移。与 Wiener 过程的漂移是恒定的不同,OU 过程的漂移取决于其当前实现与平均值的距离。形式上,OU 过程{x_t}_t 可以用随机微分方程来描述: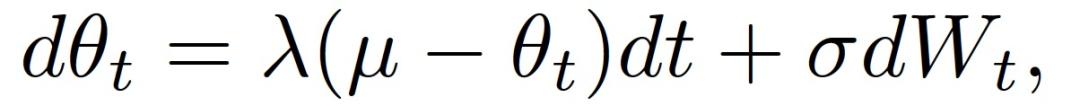 其中,W_t 表示标准 Wiener 过程。上式描述了 OU 过程所限定的随速度漂移的过程,并且具有随方差的布朗运动驱动的波动。
其中,W_t 表示标准 Wiener 过程。上式描述了 OU 过程所限定的随速度漂移的过程,并且具有随方差的布朗运动驱动的波动。OU 过程抽样策略假设网络中的全部节点(客户端)都可以无限制地访问 OU 过程,在中央服务器上部署了估计器。当采样频率约束(即上行带宽)限制了中央服务器可以收集的样本数量时,节点(客户端)应在本地决定何时发送更新。Guo 等人 [8] 的研究表明,最小化均值平方误差(MSE)的最优策略是在时间上采样:
而最优的解码策略(the optimal decoding policy)为
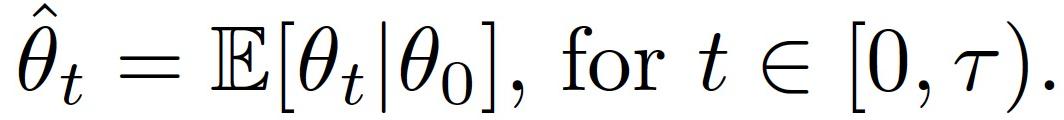 对于 OU 过程,则可以有:
对于 OU 过程,则可以有: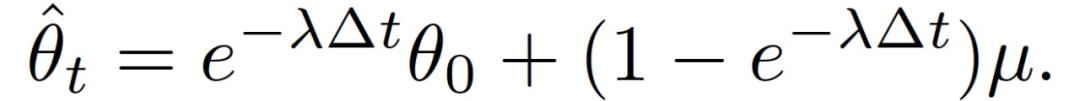 为了建立与 FL 的联系,作者提出在 FL 过程的每一轮 t 中,客户端 k 观察到一个终止于θ_t^(k)的 OU 过程的部分样本路径(即客户端在局部训练期间记录其权重的进展)。样本路径从本轮训练开始时中央服务器广播的θ_t 点(即模型权重)开始。确定本地更新 (由客户端 k) 与之前广播的模型之间的差异:
为了建立与 FL 的联系,作者提出在 FL 过程的每一轮 t 中,客户端 k 观察到一个终止于θ_t^(k)的 OU 过程的部分样本路径(即客户端在局部训练期间记录其权重的进展)。样本路径从本轮训练开始时中央服务器广播的θ_t 点(即模型权重)开始。确定本地更新 (由客户端 k) 与之前广播的模型之间的差异:根据上述抽样优化结果,作者提出如果 ||Δ_t^(k)||_2 超过一个预先确定的通信阈值,则执行更新的传输。具体过程如 Algorithm 2。
 如果在通信阈值测试结果之后,客户端 k 决定不与中央服务器通信,中央服务器可能会估计客户端的更新量如下:
如果在通信阈值测试结果之后,客户端 k 决定不与中央服务器通信,中央服务器可能会估计客户端的更新量如下: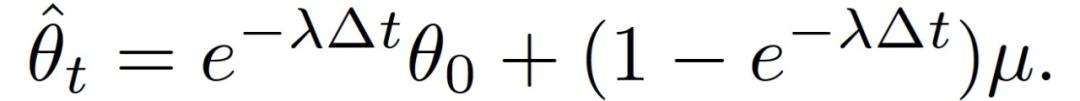 由于其中的参数λ和μ未知,将其改写为:
由于其中的参数λ和μ未知,将其改写为: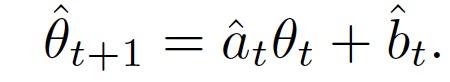 上式中的 a 和 b 可以根据之前中央服务器中聚合得到的θ_0,...θ_t 得到。完整过程如 Algorithm 3:
上式中的 a 和 b 可以根据之前中央服务器中聚合得到的θ_0,...θ_t 得到。完整过程如 Algorithm 3: 由上述分析可知,本文方法是通过与通信阈值的比对实现的通信减少。由于随着训练的进行梯度范数预计会不断减小,当我们接近最小值时,一个固定的通信阈值可能会对学习过程产生不利影响。本文提出一种根据参与客户端的更新幅度确定的动态通信阈值。在 t=0 时,客户端收到的初始通信阈值τ_0=0,意味着各个客户端在第一轮传输。在接下来的几轮中,客户端要么传输他们的更新和他们更新的范数 m_t^(k) ,要么传输一个 NACK 消息(Negative Acknowledgement)以及他们更新的范数。在 t 轮结束时,中央服务器估计更新范数的平均值:m_t,它们的标准差:s_t,并计算下一轮的通信阈值:
由上述分析可知,本文方法是通过与通信阈值的比对实现的通信减少。由于随着训练的进行梯度范数预计会不断减小,当我们接近最小值时,一个固定的通信阈值可能会对学习过程产生不利影响。本文提出一种根据参与客户端的更新幅度确定的动态通信阈值。在 t=0 时,客户端收到的初始通信阈值τ_0=0,意味着各个客户端在第一轮传输。在接下来的几轮中,客户端要么传输他们的更新和他们更新的范数 m_t^(k) ,要么传输一个 NACK 消息(Negative Acknowledgement)以及他们更新的范数。在 t 轮结束时,中央服务器估计更新范数的平均值:m_t,它们的标准差:s_t,并计算下一轮的通信阈值:完整的通信高效 FL 框架为 Algorithm 1:
 在第 t 轮开始时选择 N 个客户端,中央服务器广播模型参数θ_t,被选择的客户端在本地执行大小为 B 的 mini-batch 的 SGD,时间为 E 个 epochs。在对本地模型更新的范数与通信阈值进行比较后,每个客户端局部决定是否通信其更新,并分别传输模型更新θ_t+1^k 或负确认消息。在这两种情况下,客户端都会发送其训练数据大小 n_k,以实现加权。每个客户端也会向服务器传送其更新的范数(只有一个浮点,32 位,与全模型相比)而不会传送实际的更新。最终第 k 个客户端参数为:
在第 t 轮开始时选择 N 个客户端,中央服务器广播模型参数θ_t,被选择的客户端在本地执行大小为 B 的 mini-batch 的 SGD,时间为 E 个 epochs。在对本地模型更新的范数与通信阈值进行比较后,每个客户端局部决定是否通信其更新,并分别传输模型更新θ_t+1^k 或负确认消息。在这两种情况下,客户端都会发送其训练数据大小 n_k,以实现加权。每个客户端也会向服务器传送其更新的范数(只有一个浮点,32 位,与全模型相比)而不会传送实际的更新。最终第 k 个客户端参数为: 中央服务器在计算上的一种简单替代估计方法是重用上一轮客户端模型,或是直接忽略该客户端。最后,中央服务器更新模型如下:
中央服务器在计算上的一种简单替代估计方法是重用上一轮客户端模型,或是直接忽略该客户端。最后,中央服务器更新模型如下:此外,中央服务器还更新用于参数估计的阈值和滚动加和(rolling sums),并继续进行下一轮训练。
2.2 实验分析
作者在三个不同的数据库(合成数据库、EMNIST 和 Shakespeare)上用三种不同的模型对所提出的客户端选择策略进行了基准测试。(1)在合成数据库上进行逻辑回归;(2)在 EMNIST 上应用一个包括 62 个类别的复杂卷积神经网络;(3)在 Shakespeare 数据库上使用循环神经网络进行下一个角色预测。
作者在实验中研究了 FL 系统在以下主要方面的客户端抽样问题:(i)通信效率与客户端选择策略所达到的准确性;(ii)不同方法处理没有将其模型更新传达给中央服务器的客户端的效果。同时,作者考虑了两种处理缺失更新的策略:(i) 零策略(zero),即中央服务器用 0 取代缺失的更新(假设没有发送更新的客户端的模型与最新的全局模型相同);(ii) 忽略(ignore),即中央服务器只对收到的更新进行平均。
2.2.1 固定通信阈值
本文提出的通信阈值策略根据模型更新范数的平均值和标准差来改变通信阈值。作者考虑的问题是采用一个固定通信阈值的更简单的方案是否也能获得类似的效果。首先,要注意的是,对于固定通信阈值策略的 OU 客户端选择方法优于其它竞争方法。具体来说,我们在图 7 中最右边的两张图中观察到,zero 和 ignore 策略停滞不前,收敛速度往往比 OU 策略慢。然而,使用一个固定的通信阈值无法提供准确而又符合通信要求的 FL 系统。首先,将通信阈值作为超参处理,增加了系统设计的复杂性,因为不同的阈值可能导致非常不同的结果,如图 7 所示。调整通信阈值会违背减少通信的目标,因为可能需要执行大量的轮次来不断调整。最后,我们观察到,将通信阈值固定为较小的值也无法减少通信(图 8 中最左边的图),而将其设置为较大值则会导致模型不准确(图 7 中最右边的图)。
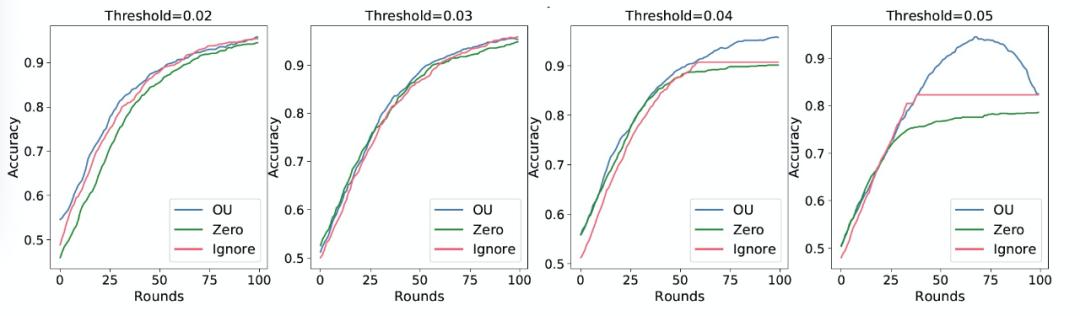 图 7. FedAvg 在不同通信阈值下采用固定通信阈值通信策略的准确度。高通信阈值阻止了向精确模型收敛,因为所有客户端一旦更新小于通信阈值,就会停止传输
图 7. FedAvg 在不同通信阈值下采用固定通信阈值通信策略的准确度。高通信阈值阻止了向精确模型收敛,因为所有客户端一旦更新小于通信阈值,就会停止传输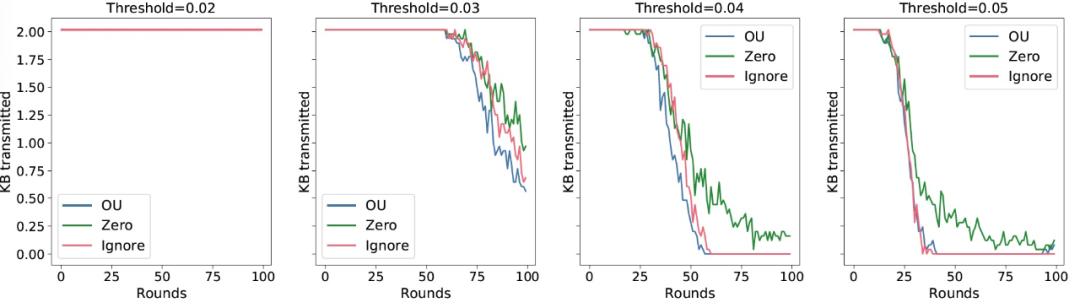 图 8. FedAvg 的每一轮通信与固定通信阈值通信策略的不同通信阈值。较小的通信阈值不能减少通信,而较大的通信阈值在训练过程中完全停止通信,从而导致生成坏的模型
图 8. FedAvg 的每一轮通信与固定通信阈值通信策略的不同通信阈值。较小的通信阈值不能减少通信,而较大的通信阈值在训练过程中完全停止通信,从而导致生成坏的模型2.2.2 对系统进行端到端评价
图 9 给出了 EMNIST 和 Shakespeare 数据库上所有随机 / 自适应选择和三种估计策略(即 OU、zero 和 ignore)组合在训练期间的测试准确度变化情况。我们观察到,OU 估计一直优于其他策略。ignore 更新也能达到很高的准确度,不过其收敛过程更不稳定。最后,zero 策略的性能最差。然而,通过将客户端的更新归零,这两个数据库的收敛速度会大大减慢。另一方面,OU 能够加入缺失的更新而不会使收敛不稳定。在这两种情况下,OU 策略都获得了最好的最终准确度;对于涉及 Shakespeare 数据库的任务,OU 甚至比全通信的基线方案获得了更好的准确度。
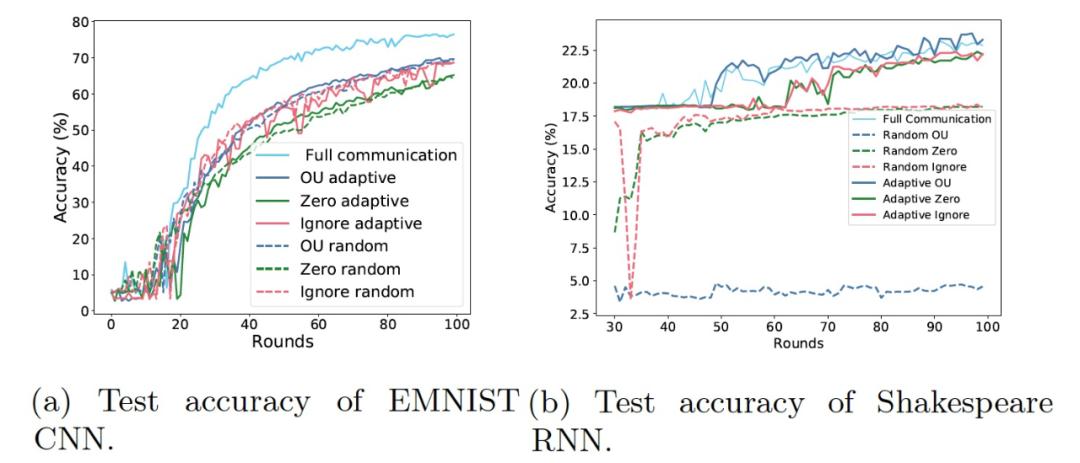 图 9. 模型在合成逻辑回归、EMNIST 和 Shakespeare 上的准确度。OU 客户端抽样策略始终优于竞争方法
图 9. 模型在合成逻辑回归、EMNIST 和 Shakespeare 上的准确度。OU 客户端抽样策略始终优于竞争方法最后,作者评估了通信节省的情况。如图 10 所示,本文基于 OU 采样和估计的通信阈值策略需要较小的通信量就能够达到与基线(即与使用全部客户端更新的方案)相当的准确度。zero 估计策略在所有情况下的通信代价都与 OU 类似,但其收敛速度较慢,最终准确度较差。在所有策略中,ignore 策略实现了最高的通信代价节约,但其准确度无法与 OU 策略相比。作者分析,ignore 策略的沟通率较低,是因为其忽略了某些客户端,而这些客户端在后续的迭代中会继续保持较高范数,从而进一步降低通信阈值导致下一轮的客户端更少。
虽然随机丢弃客户端的方式也能够实现低通信速率,但随机客户端选择方案在异质和非凸环境中存在准确度下降的问题。在异质、非凸的环境中,从客户端子集估计真实梯度要困难得多,因此随机丢弃客户端会减慢收敛速度。这在一定程度上也是由于在最佳值附近放弃了太多的客户端,而在最佳值附近,梯度范数可能会变小。自适应通信阈值策略通过在每一轮中根据客户端的更新范数改变通信阈值来克服上述问题。通过通信阈值和使用 MSE 估计器,本文以最优的方式纳入了缺失的客户端。本文实验结果表明,在 FL 中的准确度可以保持甚至超越,同时通过使用较少的客户端来减少通信量。然而,这些客户端必须经过仔细的选择,并且它们的更新必须仔细地纳入新的模型中。
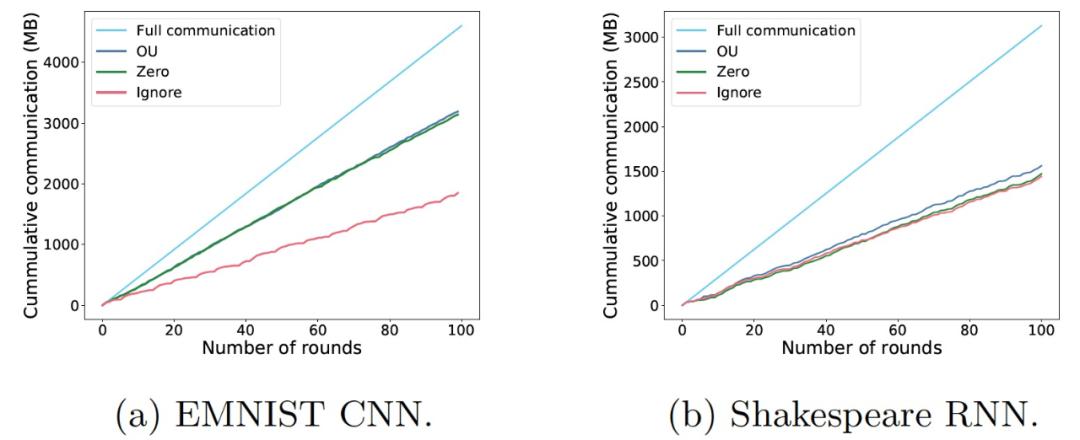 图 10. 训练期间各系统的累计通信量以发送的总 KB 数衡量
图 10. 训练期间各系统的累计通信量以发送的总 KB 数衡量表 2 中的结果表明,虽然没有一种方法在探索准确度 - 通信权衡方面具有绝对的优势,但阈值化策略是一种有效的方法,可以在不明显降低准确度的情况下对客户端进行再选择。
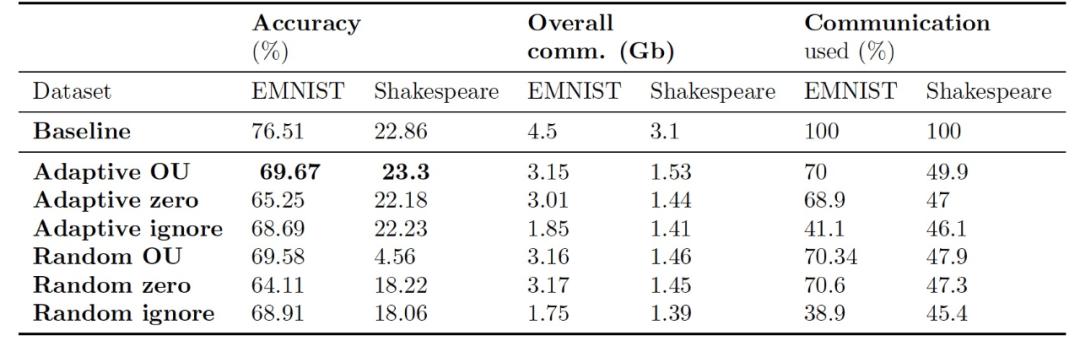 表 2. EMNIST 和 Shakespeare 数据库实验中通信缩减策略的准确性和通信成本
表 2. EMNIST 和 Shakespeare 数据库实验中通信缩减策略的准确性和通信成本3 可扩展联邦学习的参与者选择[5]
 本文目前也是一篇 ArXiv 预印文章。本文提出了 Oort,一种通过引导参与者选择以提高联邦训练和测试的性能的方法。为了提高模型的 time-to-accuracy 性能,Oort 优先使用那些既拥有对提高模型准确度有较大作用的数据,又具备快速执行训练能力的客户端。为了使 FL 开发人员能够在模型测试中解释他们的结果,Oort 强制执行对参与者数据分布的要求,同时通过客户端选择来提高联邦测试的持续时间。
本文目前也是一篇 ArXiv 预印文章。本文提出了 Oort,一种通过引导参与者选择以提高联邦训练和测试的性能的方法。为了提高模型的 time-to-accuracy 性能,Oort 优先使用那些既拥有对提高模型准确度有较大作用的数据,又具备快速执行训练能力的客户端。为了使 FL 开发人员能够在模型测试中解释他们的结果,Oort 强制执行对参与者数据分布的要求,同时通过客户端选择来提高联邦测试的持续时间。3.1 方法介绍
Oort 通过选择参与者同时使 FL 开发人员能够指定数据选择标准,从而提高 FL 训练和测试性能。Oort 位于 FL 框架的协调器内,并与 FL 执行驱动交互。给定开发者指定的标准,Oort 会响应一个参与者的列表,而驱动程序则负责在 Oort 选择的远程参与者上启动和管理执行。
图 11 显示了 Oort 与开发者和 FL 执行框架的交互方式。1 作业提交:开发者向云端的 FL 协调器提交并指定参与者选择标准。2 参与者选择:协调器查询符合资格条件的客户端(如电池水平),并将其特征(如活跃度)转发给 Oort。给定开发人员的需求(在训练 2a 的情况下是执行反馈),Oort 根据给定的标准选择参与者,并将这个参与者的选择通知协调器( 2b )。3 执行:协调器将相关的配置文件(如模型)分发给这些参与者,然后每个参与者在他 / 她的数据上独立计算结果(如训练中的模型权重)。4 聚合:当参与者完成计算后,协调器聚合参与者的更新。
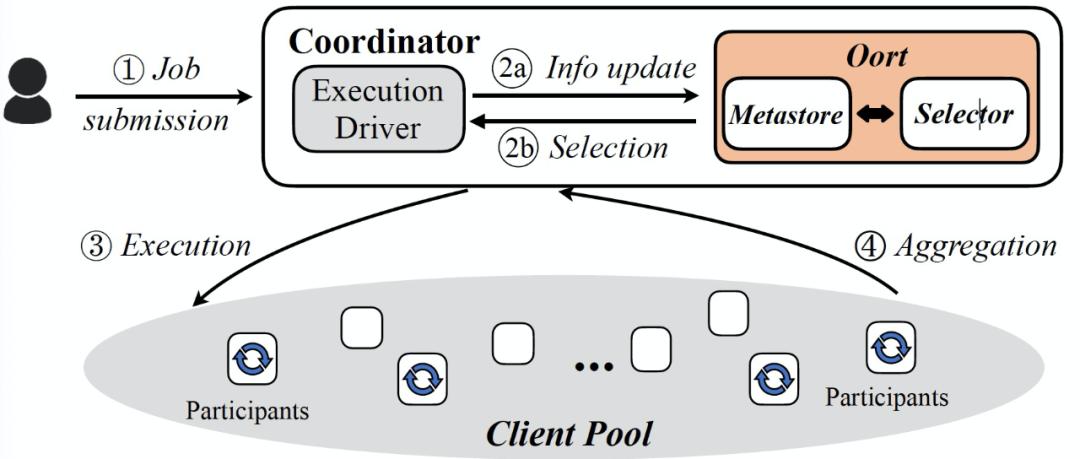 图 11. Oort 架构。FL 框架的驱动程序使用客户端库与 Oort 进行交互
图 11. Oort 架构。FL 框架的驱动程序使用客户端库与 Oort 进行交互3.1.1 联邦模型训练
首先,这篇文章的作者也讨论了统计效率和系统效率之间的权衡问题,即达到目标准确度所需要的轮次数量和每轮训练持续时间之间的权衡。为了提高 time-to-accuracy 性能,Oort 的目标是通过将每个客户端的效用与优化每一种效率形式联系起来,在权衡中找到一个最优点。作者考虑,这主要需要解决三个问题:
1. 每一轮,如何在尊重客户端隐私的前提下,确定哪些客户端的数据最有助于提高训练的统计效率?
2. 如何考虑客户端的系统性能,以优化全局系统效率?
3. 在训练过程中,如何解释我们没有为所有客户端提供最新的实用价值的事实?
首先,关于客户端统计效率的问题,作者考虑引入重要性采样 (importance sampling)的方法。假设每个客户端 i 本地存储了一个 bin B_i 的训练样本。那么,为了通过重要性抽样来提高轮次准确度性能,最佳方案是以与其重要性成正比的概率来选取 bin B_i。
不过,上式在实际应用中是根本无法计算的。作者引入了一个实用的统计效用近似值来进行代替。梯度是通过取训练损失相对于当前模型权重的导数得出的,其中训练损失衡量的是模型预测与真实值之间的估计误差。将客户端 i 的统计效用 U(i)定义为:
其中,训练过程中自动生成样本 k 的训练损失 Loss(k),收集开销可以忽略不计。
作者进一步提供了三种保护客户端隐私的方法。首先,我们聚合训练损失,它是由客户端在其所有样本中本地计算的,不会透露单个样本的损失分布。其次,当聚合后的总损失引起隐私问题时,客户端可以在上传前为其损失值添加噪声。第三,Oort 可以灵活地适应一般参与者选择框架中会使用到的其他统计效用定义。
简单地选择统计效用高的客户端会阻碍系统效率的提高。为了协调两种效率的需求,作者提出应该最大限度地提高单位时间内所能达到的统计效用(即统计效用与其系统速度的乘积)。因此,我们通过将客户端 i 的统计效用与每轮训练时间的全局系统效用关联起来,来确定客户端 i 的效用:
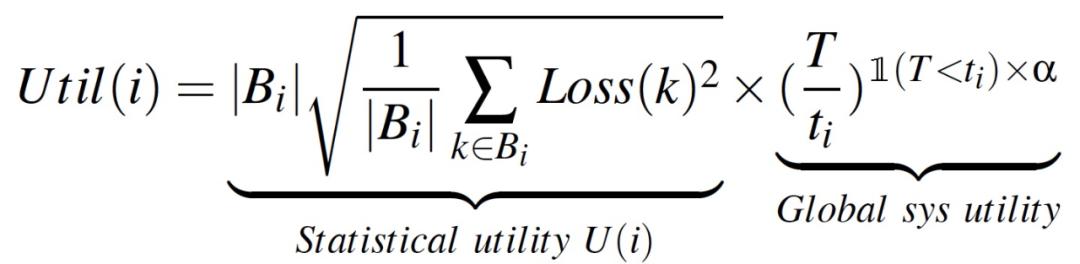 其中,T 是开发者首选的每一轮的持续时间,t_i 是客户端 i 训练所需的时间。这样一来,那些可能是当前回合理想速度瓶颈的客户端的效用将受到开发者指定的因子α的惩罚,但我们不会奖励 non-straggler 客户端,因为他们的完成度不会影响一个轮次的持续时间。
其中,T 是开发者首选的每一轮的持续时间,t_i 是客户端 i 训练所需的时间。这样一来,那些可能是当前回合理想速度瓶颈的客户端的效用将受到开发者指定的因子α的惩罚,但我们不会奖励 non-straggler 客户端,因为他们的完成度不会影响一个轮次的持续时间。确定 T 是比较困难的一件事。为了实现最佳的权衡:即在不牺牲系统效率的前提下,最大限度地提高总的统计效用,本文提出的 Oort 采用了一个节奏器(Pacer)来确定运行时的首选持续时间 T。当过去几轮累积的统计效用降低时,Pacer 允许以更大的 T← T+Δ再次与统计效率进行平衡。Algorithm 1 中给出详细说明。
 基于上述客户端效用的定义,我们需要解决以下问题,以便在每轮训练中选择效用最高的参与者:
基于上述客户端效用的定义,我们需要解决以下问题,以便在每轮训练中选择效用最高的参与者:可扩展性:一个客户端只有在参加训练后才能确定其效用,如何在规模化的客户端中进行选择,而不必把所有客户端都试一遍?
陈旧度:由于不是每个客户端都参与了每一轮的交易,那么如何核算客户端自上次参与后的效用变化?
稳健性:如何在客户端损坏的情况下,对异常值进行稳健性处理(如有噪声数据)?
为了解决上述问题,本文开发了一种探索利用(exploration-exploitation strategy)策略来选择参与者(如上述 Algorithm 1 所示)。作者提出,在众多客户端中选择参与者的问题可以建模为一个多臂赌博机问题(a Multi-armed bandit problem),每个客户端都是赌博机的 "摇臂",获得的效用就是 "报酬"。为了实现长期报酬的最大化,我们可以自适应地平衡不同摇臂的探索和利用。
与赌博机设计类似,Oort 在空间变化下有效地挖掘潜在的参与者,同时在时间变化下智能地利用观察到的高效用参与者。在每一轮选择开始时,Oort 会收到上一轮训练的反馈信息,并更新客户端的统计效用和系统性能(Line 6)。对于被探索(explored)的客户端,Oort 计算其客户端效用,并通过利用高效用参与者来缩小选择范围(Line 9-15)。同时,Oort 对ε(∈[0,1])比例的部分参与者进行采样,以探索之前未被选择的潜在参与者(Line 16)。虽然我们无法得知尚未尝试的客户端的统计效用,但可以决定在可能的情况下,优先考虑系统速度较快的未探索客户端(例如,通过设备模型推断),而不是进行随机探索(Line 16)。
Oort 采用两种策略来应对客户端效用随时间的动态变化。首先,受到用于衡量赌博机奖励不确定性的置信区间的启发,我们引入了一个与赌博机解的置信度类似的激励项(第 10 行),即如果客户端长期被忽略,我们将逐步增加它的效用。其次,我们不是确定性地选取 Top-k 效用的客户端,而是允许在 cut-off 效用上设置一个置信区间 c(Line 13-14 默认为 95%)。即,最终采用的客户端其效用大于 Top((1-ε)xK)个参与者的 比例 c。在这个高效用池中,Oort 以与效用成正比的概率对参与者进行抽样(Line 15)。这种自适应开发通过对参与者进行优先级排序来应对客户端效用的不确定性,同时保持整体的高质量。
简单地优先处理高实用性客户端的方法在不利的环境中容易出现异常值。例如,被破坏的客户端中可能包含噪声数据从而导致较高的训练损失,甚至故意报告任意的高训练损失。为了保证稳健性,Oort:(i)在给定轮次的客户端被选中后在选择列表中删除它;(ii)通过对客户端的效用值进行剪辑,使其不超过上限(如效用分布中的 95% 值)。
本文提出的自适应参与者选择方法是通用的,以适用于不同效用定义的多样化选择标准。作者在文中展示了 Oort 通过优先考虑高损失客户端,可以实现比现有方法更公平的客户端精准度分配。Oort 可以通过将客户端 i 的当前效用定义替换为以下方式来执行他们的要求:
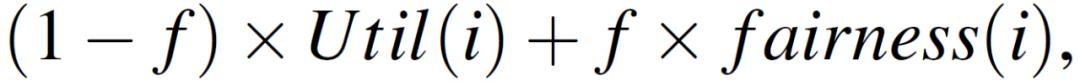 其中,f∈[0,1],随着 f→1,Algorithm 1 会自然地优先处理公平性需求最大的客户端。
其中,f∈[0,1],随着 f→1,Algorithm 1 会自然地优先处理公平性需求最大的客户端。3.1.2 联邦模型测试
学习单个数据特征(如分类分布)可能过于昂贵甚至是被禁止。在不了解数据特征的情况下,开发人员必须保守地选择许多参与者,以获得更多的置信度来查询 "一个与全局数据偏差小于 X% 的测试集"。然而,由于系统的异构性,选择太多的参与者可能会使预算膨胀和 / 或耗时太长。接下来,作者将展示 Oort 如何通过确定保证该偏差目标所需的参与者数量来实现引导式参与者选择。
本文使用 L1 距离(FL 中流行的距离度量)来考虑所有参与者形成的数据与全局数据库的偏差。对于类别 X,它的 L1 距离捕获了所有参与者的平均样本数与所有客户端的平均样本数之间的偏差。由于客户端 n 持有的样本数 X_n 在客户端之间是独立的,因此可以将其视为从变量 X 的分布中抽样的随机实例。给定开发者指定的数据偏差ε和置信区间δ,我们的目标是估计所需的参与者数量,使得与代表性分类分布的偏差是有界的。为此,作者将其表述为一个随机变量的抽样问题,并应用集中理论(Concentration theory)来判断这种数据偏差在不同的参与者数量下是如何变化的。
即使个别数据特征不可用,开发者也可以指定它对全局分类分布偏差的容忍度ε,Oort 据此输出保持这种偏好所需的参与者数量。为了使用我们的模型,开发者需要输入一个客户端所能容纳的样本数量的全局范围(即全局最大值 - 全局最小值),以及客户端的总数量。
我们的模型不需要收集任何全局(全部客户端)或参与者数据的分布。根据当事人参与者的选择(straw-man participant selection)设计,开发者可以将模型随机分配给这个由 Oort 确定的参与者数量。从这个数量的参与者中收集结果后,她 / 他可以确认计算数据的代表性。当提供单个数据特征时,Oort 可以在特定的分类分布上强制执行精确的数据偏好,并通过挑选参与者来改善测试的持续时间。为了实现更好的扩展性,作者提出了一种贪婪的启发式方法来缩减 straw-man 的搜索空间。具体包括:(1)首先对可行的客户端的子集进行分组,以满足偏好约束。为此,我们将所有尚未满足的类别中样本数最多的客户端迭代添加到我们的子集中,并通过该客户端对应的容量来扣除每个类别的偏好约束条件。当满足偏好时停止这种贪婪的分组,如果超过预算则会申请新的预算。(2)在这个客户端子集中用简化的混合整数线性规划(Mixed Integer Linear Programming,MILP)优化作业持续时间,其中,作者去掉了预算约束,减少了客户端的搜索空间。
3.2 实验分析
3.2.1 实现方法
作者实现了 Oort 的 Python 库,共包含 2617 行代码,以友好地支持 FL 开发者。Oort 提供了简单的 API 来抽象参与者选择的问题,开发者可以在其应用代码库中导入 Oort,并与 FL 引擎(如 PySyft 或 TensorFlow Federated)进行交互。作者已经将 Oort 与 PySyft 整合在一起。Oort 在 FL 开发者和 PySyft 在运行时反馈的客户端元数据(如数据分布或系统性能)上运行并更新。
Oort 中每个客户端的元数据是一个内存占用较小的对象。Oort 在执行过程中会将这些对象缓存在内存中,并定期将其备份到持久化存储中。如果出现故障,执行驱动会启动新的 Oort 选择器,并加载最新的检查点来追回进度。采用 Gurobi 求解器来解决 MILP。使用 xmlrpc 库连接到协调器,来自协调器的更新会激活 Oort 将这些更新写入它的元存储中。
3.2.2 结果分析
作者在四个 CV 和 NLP 数据库上评估了 Oort 对四个不同 ML 模型的有效性。具体四个数据库包括:语音识别(Speech Recognition)、图像分类(Image Classification)、语言模型(Language Modeling)(包括 StackOverflow 和 Reddit)。对于模型训练任务,实验评估 time-to-accuracy 性能和最终模型准确度。对于模型测试,实验评估的是端到端的测试持续时间,它包括解决方案的计算开销和实际计算的持续时间。
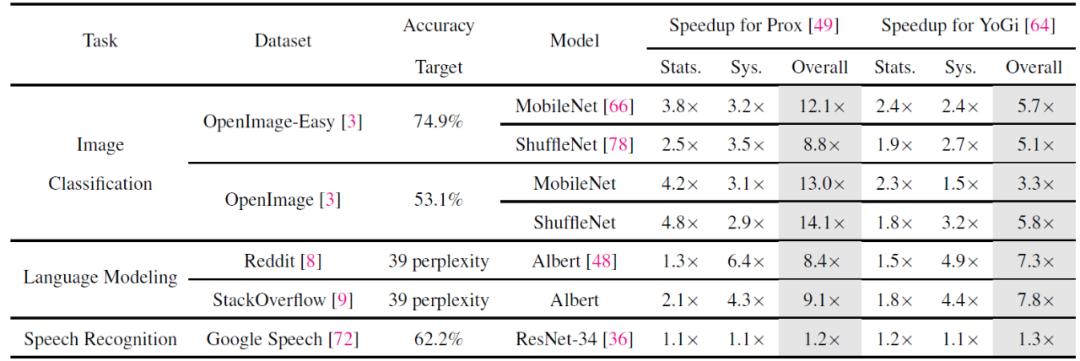 表 3. Time-to-accuracy 性能
表 3. Time-to-accuracy 性能表 3 给出了不同数据库中 time-to-accuracy 性能。Oort 实现了较大的数据提升以达到目标准确度。这些 time-to-accuracy 的改进来自于统计模型效率和系统效率方面的效益。
图 12 给出了达到不同准确度的训练时间。当模型收敛后,Oort 在 OpenImage 数据集上的最终准确度提高了 6.6%-9.8%。由于客户端规模较小,Google Speech 数据库中的这一改进也较小。这些改进都归功于高统计效用客户端的开发,即统计模型的准确性是由全局聚合质量决定的。
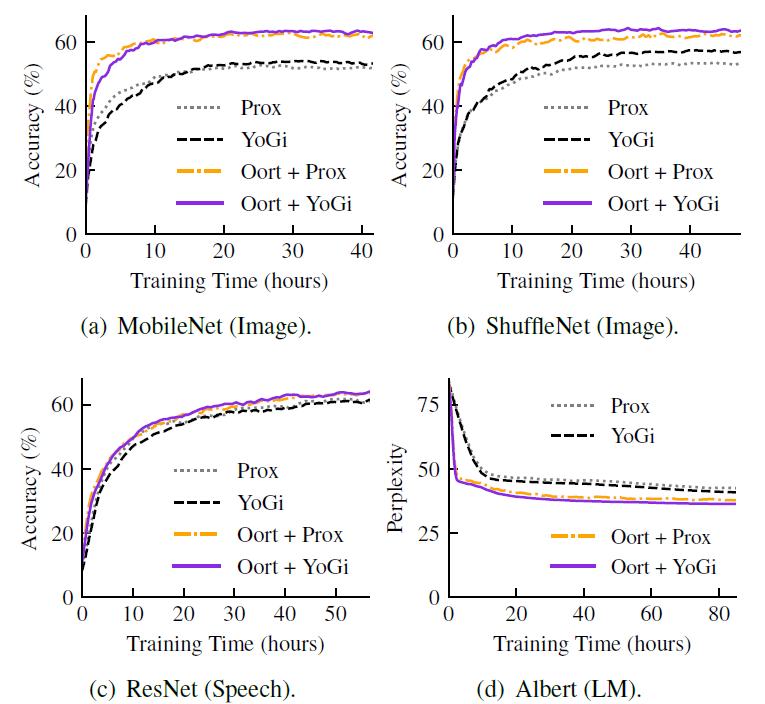 图 12. time-to-accuracy 性能
图 12. time-to-accuracy 性能关于联邦学习测试问题,图 13 报告了 Oort 在服务不同偏差目标上的表现。选定的客户端数量从 10 到 4k,随机选择每个给定数量的参与者超过 1k 次以搜索其可能的偏差。对于一个给定的偏差目标,(i)不同的工作负载需要不同数量的参与者。例如,为了达到 0.05 的差异目标,语音数据库使用的参与者比 Reddit 少 6 人,这是因为 Reddit 的异质性较小。(ii)在 Oort 确定参与者数量的情况下没有任何经验偏差会超过目标,说明 Oort 在满足偏差目标方面是有效的,据此,Oort 降低了任意扩大参与者集的成本,提高了测试持续的时间。
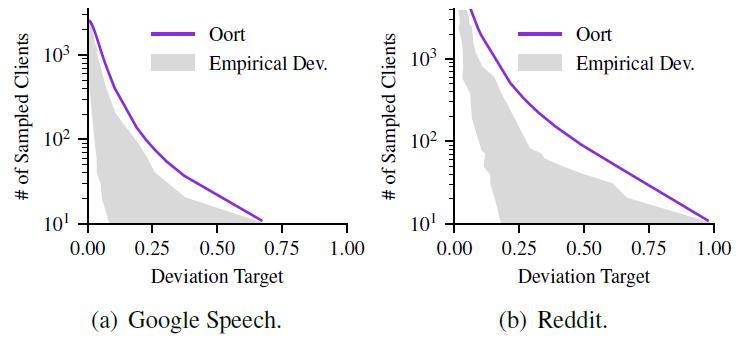 图 13. Oort 可以限制所有目标的数据偏差。阴影表示给定 y 轴输入的 1000 次运行中 x 轴值的经验 [min,max] 范围
图 13. Oort 可以限制所有目标的数据偏差。阴影表示给定 y 轴输入的 1000 次运行中 x 轴值的经验 [min,max] 范围图 14(a)给出了端到端的测试时间。我们观察到 Oort 的性能平均比 MILP 高出 4.7 倍。这是因为 Oort 通过贪婪地减少 MILP 的搜索空间,几乎没有计算开销。由图 14(b),MILP 完成参与者选择平均需要 274 秒,而 Oort 只需要 15 秒。
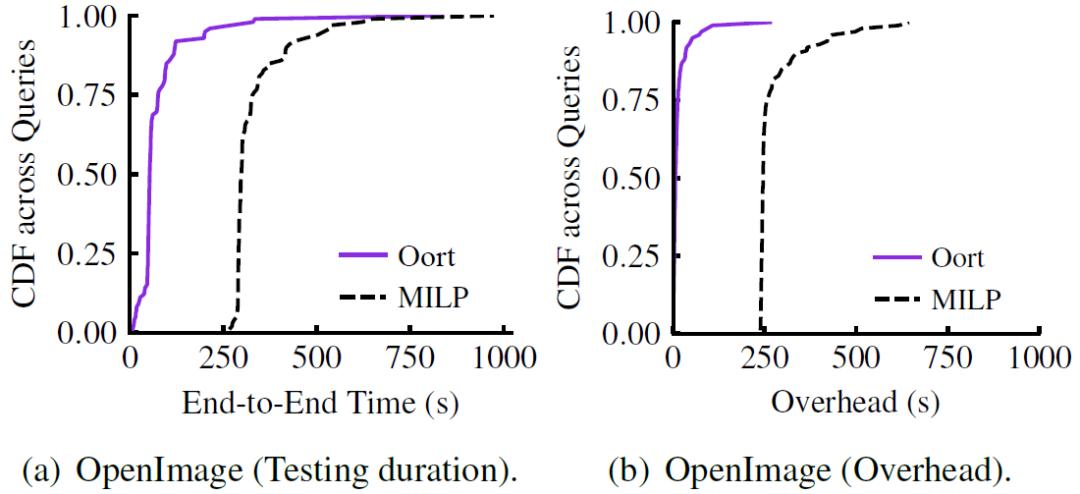 图 14. Oort 在 FL 测试中性能优于 MILP
图 14. Oort 在 FL 测试中性能优于 MILP4 基于强化学习的 Non-IID 数据联邦学习优化[6]
 本文是 IEEE INFOCOM 2020 中的一篇文章,聚焦的是 FL 环境中不同客户端设备中 Non-IID 数据对最终模型性能的影响。作者认为,现有的联邦学习方法并没有解决异构局部数据库带来的统计挑战。由于不同的用户有不同的设备使用模式,位于任何一个客户端设备上的数据样本和标签可能遵循不同的分布,无法代表全局数据分布。在存在 Non-IID 数据的情况下,联邦学习的模型准确度和达到收敛所需的通信轮数方面的性能都显著下降。随机选取的局部数据库可能无法反映全局视图中的真实数据分布,这就不可避免地给全局模型更新带来了偏差。此外,在 Non-IID 数据上局部训练的模型相互之间可能会存在显著差异。将这些不同的模型聚合在一起,就可能会出现收敛速度减速减慢或模型准确度大幅降低的问题。
本文是 IEEE INFOCOM 2020 中的一篇文章,聚焦的是 FL 环境中不同客户端设备中 Non-IID 数据对最终模型性能的影响。作者认为,现有的联邦学习方法并没有解决异构局部数据库带来的统计挑战。由于不同的用户有不同的设备使用模式,位于任何一个客户端设备上的数据样本和标签可能遵循不同的分布,无法代表全局数据分布。在存在 Non-IID 数据的情况下,联邦学习的模型准确度和达到收敛所需的通信轮数方面的性能都显著下降。随机选取的局部数据库可能无法反映全局视图中的真实数据分布,这就不可避免地给全局模型更新带来了偏差。此外,在 Non-IID 数据上局部训练的模型相互之间可能会存在显著差异。将这些不同的模型聚合在一起,就可能会出现收敛速度减速减慢或模型准确度大幅降低的问题。本文提出了一个通过智能设备选择来提高联邦学习性能的 FAVOR 控制框架。基于强化学习的理念,FAVOR 旨在通过学习来加速和稳定联邦学习过程,即在每一轮通信中主动选择最佳的设备子集,以抵消 Non-IID 数据引入的偏差。
4.1 FL 中 Non-IID 数据带来的问题
当 FL 的客户端设备中局部数据为 Non-IID 时,经典 FL 方法变得不稳定甚至可能出现偏离。作者分析,这是由于本地执行的 SGD 算法与全局目标不一致,SGD 算法的目标是最小化每个客户端设备上 m(k)个本地样本上的损失值,而全局目标是最小化所有数据样本上的总体损失。当我们不断基于不同客户端设备上对异质局部数据拟合模型时,这些局部模型的权重 w(k)之间的偏差会不断累积,最终会降低学习性能,导致训练需要更多的通信轮次才能达到收敛。减少联邦学习中的通信轮次数,对于计算能力和通信带宽有限的移动设备来说是至关重要的。
作者用一个实验来证明,如果在每一轮模型聚合中随机选择参与的客户端设备,Non-IID 数据可能会减慢联邦学习的收敛速度。在实验中使用聚类算法选择设备可以代替随机选择,这种处理方式有助于均匀数据分布,加快收敛速度。
作者使用 PyTorch 在 MNIST 数据库(包含 60000 个样本)上训练一个两层 CNN 模型,直到模型达到 99% 的测试准确度。作者在实验中一共使用了 100 台设备(客户端),每台设备在不同的线程上运行。分别在 IID 和 Non-IID 设置下训练 CNN 模型。对于 IID 设置,60000 个样本随机分布在 100 个设备中,这样每个设备拥有 600 个样本。对于 Non-IID 设置,每个设备仍然拥有 600 个样本,但是其中 80% 的样本来自优势类(dominant class),其余 20% 属于其它类。例如,一个以 "0" 为主的设备有 480 个数据样本的标签为 "0",而其余 120 个数据样本的标签均匀分布在 "1" 到 "9"。在每一轮中,选择十个设备参与联邦学习。FL 在每一轮只选择所有设备的一个子集,以平衡计算复杂度和收敛速度,并避免模型聚合的等待时间过长。
经典 FL 方法 FEDAVG 随机抽取 10 台设备参加每轮训练。如图 15 所示,IID 设置下 FEDAVG 需要 47 个通信轮次以达到目标准确度。但是,在 Non-IID 数据中 FEDAVG 需要 163 轮次才能达到 99% 的准确度。为了减少 Non-IID 设置所需的通信轮次,作者对设备选择策略进行调整。虽然在 FL 中,我们无法得到每个设备的数据分布,但设备上的数据分布和在该设备上训练的模型权重之间存在隐性联系。因此,作者提出可以通过第一轮之后的本地模型权重来进一步分析每个设备。给定初始的全局模型权重ω_init,在 SGD 的一个 epoch 后,设备 k 上的局部权重可以用以下方式表示:
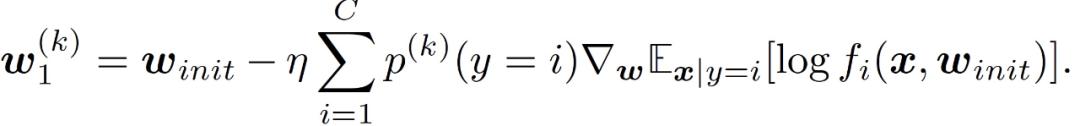 设备 k 和 k’中的权重偏差可以表示为:
设备 k 和 k’中的权重偏差可以表示为:作者给出了根据第一轮次权重偏差推导出的边界:
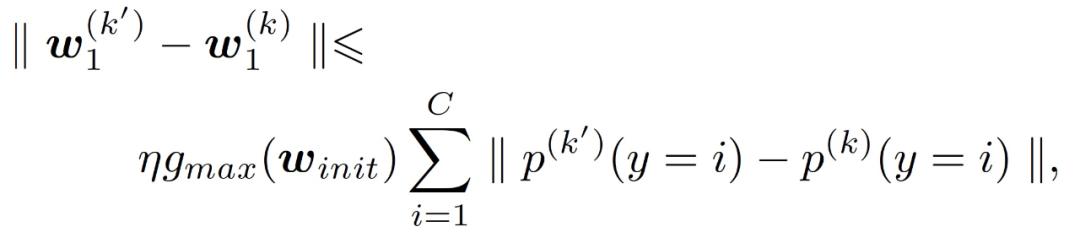 这意味着,即使局部模型以相同的初始权重ω_init 进行训练,根据下式及权重偏差,设备 k 和 k’上的数据分布差异之间也存在隐性联系:
这意味着,即使局部模型以相同的初始权重ω_init 进行训练,根据下式及权重偏差,设备 k 和 k’上的数据分布差异之间也存在隐性联系: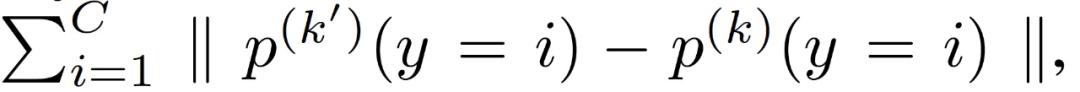 基于上述分析,作者先让 100 台设备各自下载相同的初始全局权重(随机生成),并根据本地数据进行一个 epoch 的 SGD 以得到:ω_1^(k),k=1,...,100。之后利用 K 中心 (K-Center) 聚类方法将 100 台设备聚类到 10 个组。在每一轮中,从每组中随机选取一台设备参与 FL 训练,结果每轮仍有 10 台设备同时参与。在 Non-IID 设置下,K 中心聚类算法需要 131 轮能够达到目标准确度,比经典的 FEDAVG 算法少 32 轮。该实验表明,通过在每一轮中仔细选择参与设备的集合,特别是在 Non-IID 数据环境下,有可能改进联邦学习的性能。
基于上述分析,作者先让 100 台设备各自下载相同的初始全局权重(随机生成),并根据本地数据进行一个 epoch 的 SGD 以得到:ω_1^(k),k=1,...,100。之后利用 K 中心 (K-Center) 聚类方法将 100 台设备聚类到 10 个组。在每一轮中,从每组中随机选取一台设备参与 FL 训练,结果每轮仍有 10 台设备同时参与。在 Non-IID 设置下,K 中心聚类算法需要 131 轮能够达到目标准确度,比经典的 FEDAVG 算法少 32 轮。该实验表明,通过在每一轮中仔细选择参与设备的集合,特别是在 Non-IID 数据环境下,有可能改进联邦学习的性能。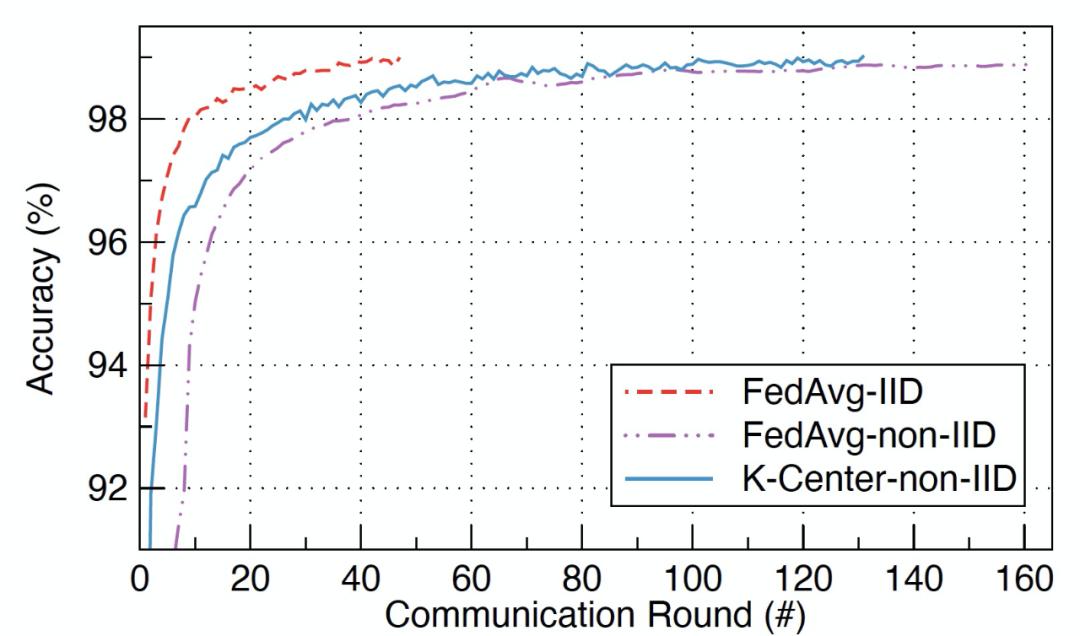 图 15. 在 Non-IID MNIST 数据上训练 CNN 模型
图 15. 在 Non-IID MNIST 数据上训练 CNN 模型4.2 方法介绍
作者将联邦学习中的设备选择看做一个深度强化学习 (deep reinforcement learning,DRL) 问题。作者提出了一个由 DRL 驱动的联邦学习工作流。然后,作者介绍了在联邦学习中处理高维模型的挑战。最后,作者描述了使用 double Deep Q-Learning Network(DDQN)训练 DRL agent。
每轮 FL 过程可以建模为一个马尔科夫决策过程(Markov Decision Process, MDP),状态 s 由全局模型权重和每轮中每个客户端设备的模型权重表示。给定一个状态,DRL agent 采取一个动作 a 来选择一个进行局部训练的设备子集并更新全局模型。然后可以得到一个奖励信号 r,它是全局模型到目前为止在一个 held-out 的验证集上所达到的测试准确度函数。DRL 的目标是训练 DRL agent 尽快收敛到联邦学习的目标准确度。
在所提出的框架中,agent 不需要收集或检查任何来自移动设备的数据样本—只传递了模型权重—因此能够保证与原始 FL 相同的隐私水平。它仅仅依靠模型权重信息来确定哪个设备可以最大程度地改进全局模型,因为设备上的数据分布与其对这些数据执行 SGD 所获得的局部模型权重之间存在隐性联系。
4.2.1 基于 Deep Q-Network 的 agent
假设在 N 个可用设备上有一个联邦学习作业,目标准确度为 Ω。在每一轮中,使用 DeepQ-Network(DQN)选择 K 个设备参与训练。考虑到联邦学习作业的可用 traces 有限,与策略梯度方法(policy gradient method)和 actor-critic 方法相比,DQN 可以更有效地进行训练,并且可以更有效地重用数据。
状态(state):令第 t 轮的状态为 s_t=(ω_t, ω_t^(1),...,ω_t^(N))。其中,ω_t 表示轮次 t 后全局模型的权重。ω_t, ω_t^(1), ..., ω_t^(N)分别为 N 台设备的模型权重。agent 与 FL 中央服务器对接,并维护一个模型权重的列表。只有当客户端 k 被选中在某轮次中权重ω^(k)才会更新,并将结果Δ_t^(k)发送至中央服务器。因此,并没有为设备引入额外的通信开销。
由此产生的状态空间可能是巨大的,例如,一个 CNN 模型可能包含数百万个权重。在如此大的状态空间中训练一个 DQN 是一个非常大的挑战。在实践中,作者提出在状态空间上应用一种有效的轻量级降维技术,例如,可以在模型权重上应用降维技术。
动作(Action):在每一轮 t 开始时,agent 需要决定从 N 个设备中选择 K 个设备的哪个子集。这种选择将导致一个很大的动作空间 ,这使得 RL 训练变得非常复杂。作者提出了一个方法能够在保持较小行动空间的同时仍然利用 DRL agent 提供的智能控制。
具体来说,每轮 agent 根据 DQN 在 N 个设备中只选择一个设备参与 FL 进行训练,而在测试和应用中,agent 会抽取一批 top-K 的客户端参与 FL。也就是说,DQN agent 通过神经网络学习最优行动值函数 Q*(s_t, a)的近似器,从 s_t 开始估计能够保证预期收益最大化的行动,由此可以降低动作空间。一旦 DQN 被训练成近似 Q*(s_t, a),在测试过程中,第 t 轮 DQN agent 将为所有 N 个动作计算:{Q*(s_t, a)|a∈[N]}。每个动作值表示 agent 在状态 s_t 选择特定动作 a 所能获得的最大预期收益。然后,选择 K 个设备,每个设备对应一个不同的动作 a,以得到 top-K 个值 Q*(s_t, a)。
奖励(Reward):设定每轮结束时观察到的奖励为
其中ω_t 表示全局模型在第 t 轮之后对 held-out 验证集的测试准确度,Ω为目标准确度,Ξ表示正常量以保证 r_t 指数级逼近测试准确度ω_t。当ω_t=Ω,联邦学习过程停止。根据下式,训练 DQN agent 能够最大限度地提高累积折价奖励的期望值:
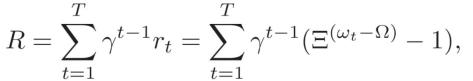 4.2.2 工作流
4.2.2 工作流图 16 给出 FAVOR 利用 DRL agent 在每一轮中选择客户端设备以执行联邦学习的过程。
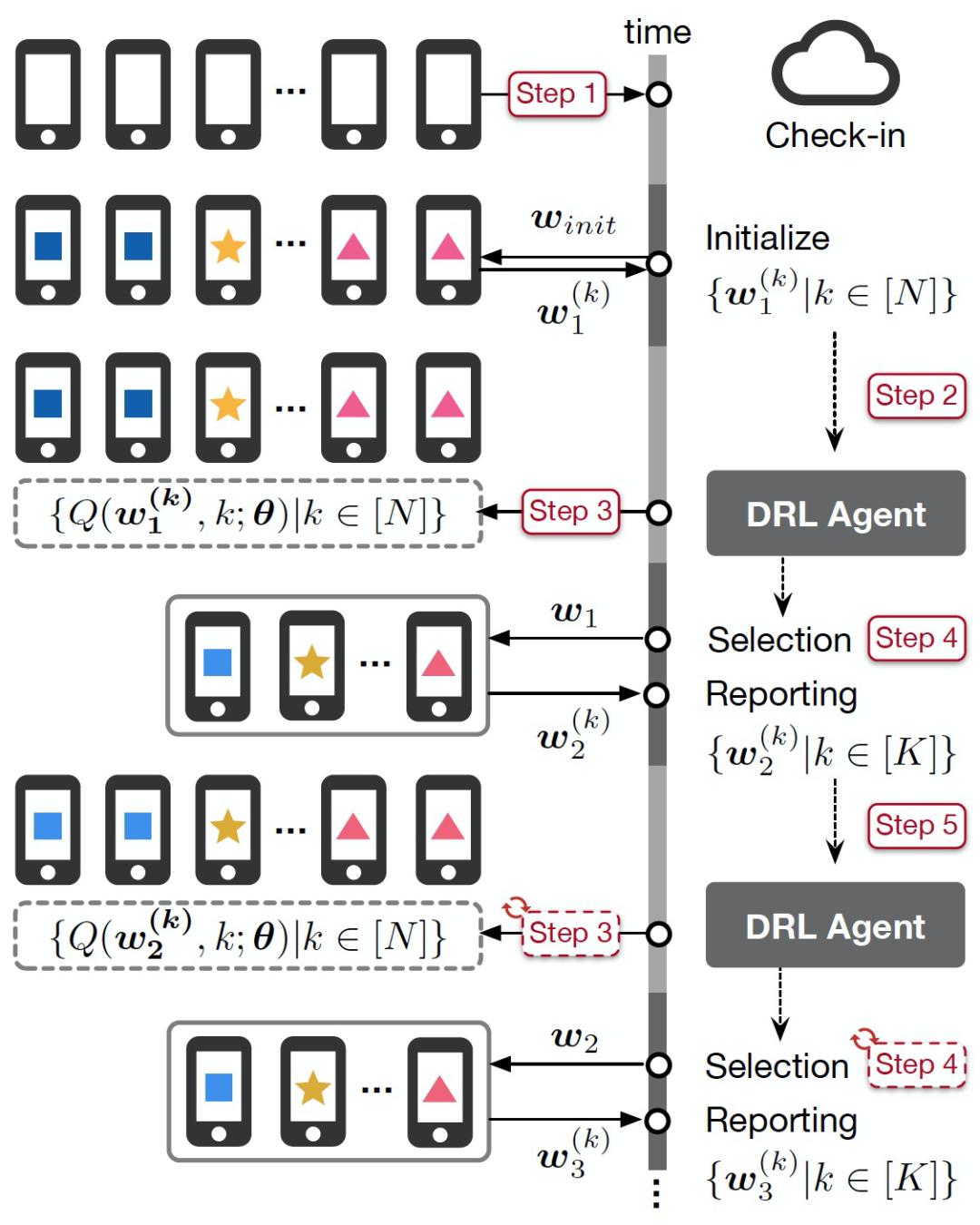 图 16 FAVOR 工作流
图 16 FAVOR 工作流第一步:所有符合条件的 N 个设备在 FL 中央服务器上签到。
第二步:每个设备从中央服务器下载初始随机模型的权重ω_init,在一个 epoch 中执行局部 SGD,并将结果模型权重 {ω_1^(k),k∈[N]} 发送至中央服务器。
第三步:轮次 t 中, 响应于接收到上传的局部权重,中央服务器更新已存储的相对应的局部权重。DQN 为每台客户端设备 a 计算 Q(s_t, a;θ);
第四步:DQN agent 根据 top-K 个 Q(s_t, a;θ)的值选择 K 个客户端设备。这 K 台设备下载最新的全局模型权重ω_k,之后进行一个 epoch 的 SGD 局部更新以得到{(ω_(t+1))^k | k∈[K]}。
第五步:将 {(ω_(t+1))^k | k∈[K]} 报告(上传至)中央服务器以经典 FL 的方式计算得到ω_(k+1)。重复执行第 3-5 步以进入下轮 t+1。
上述工作流程可以很方便的进行调整,让每个选定的客户端在不改变底层逻辑的基础上上传模型差异Δ(与本地模型的最后一个版本相比),而不是新的本地模型本身。FL 服务器可以随时使用Δ来重建其上存储的相应本地模型的副本。
当设备 k 有新的训练数据时,它将请求全局模型权重ω_k,并进行一个 epoch 的局部 SGD 训练(第二步),生成新的局部模型权重ω_t^k。然后,设备 k 将ω_t^k 推送至 FL 中央服务器,中央服务器更新状态 s_t 以使得 DRL agent 意识到数据更新。在 DRL 训练过程中,每个设备上的数据保持不变,以确保训练遵循马尔科夫决策过程。上述步骤引入的开销是很小的,这是因为没有向设备添加额外的计算 / 通信开销。唯一的开销是,现在的 FL 中央服务器需要存储每个设备最新的本地模型权重的副本,以形成状态 s_t。FL 中央服务器一般都部署在云中,具备提供足够的按需计算和存储能力 。
4.2.3 降维
本文提出的 DQN agent 存在一个问题:它使用全局模型和所有局部模型的权重作为状态,这就生成了一个非常大的状态空间。深度神经网络 (如 CNN) 有数百万个权重,使得在如此高维的状态空间中训练 DQN agent 非常具有挑战性。针对这一问题,作者提出将主成分分析 (Principal Component Analysis,PCA) 应用于模型权重,使用压缩后的模型权重来代替状态。
我们只根据局部模型权重计算不同主成分的 PCA 加载向量。在随后的几轮中,这样的加载向量可以被重新使用,通过线性变换得到前几个主成分而不需要再次拟合 PCA 模型。因此,在随后的几轮中压缩模型权重的开销可以忽略不计。作者通过一个简单的实验来证明使用 PCA 压缩后得到的模型权重来区分数据分布的有效性。实验在 100 台设备上运行 PyTorch,在 MNIST 数据库上使用联邦学习训练一个两层 CNN 模型(共 431,080 个模型权重)。每个客户端有 80% 的数据样本类别标签为 dominant class,而其余 20% 的样本标签为 random class。在第 1 轮本地 SGD 训练 5 个 epochs 后,将 100 台设备的模型权重向量投射到第一和第二主成分的二维空间。如图 17 所示,不同的形状(或颜色)表示在具有不同 dominant 标签的设备上训练的局部模型。例如,所有黄色的 "+" 号表示第 1 轮中压缩的局部模型来自那些具有 dominant 标签 "6" 的设备。即使从 431,080 个维度减少到只有 2 个维度,甚至在第 1 轮时我们也可以从图中观察到局部模型根据其 dominant 标签的聚类效应。
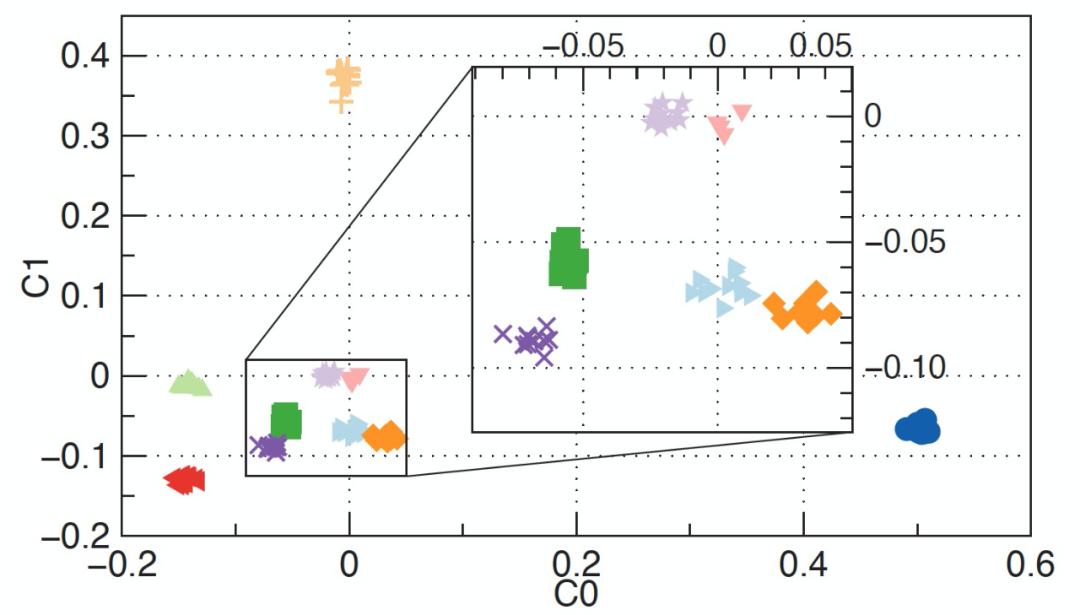 图 17. MNIST 数据库上 CNN 权重的 PCA 结果
图 17. MNIST 数据库上 CNN 权重的 PCA 结果4.2.4 使用 DDQN 训练 agent
最后,作者提出使用 double deep Q-learning network(DDQN)学习 Q*(s_t, a)。Q-learning 基于选定的设备为状态 s_t 下的每个潜在动作 a 提供一个价值估计。然而,原始的 Q-learning 可能是不稳定的,因为它们通过学习最优动作价值函数 Q*(s, a)的近似 Q(s, a)来间接优化 agent 的性能。DDQN 增加了另外一个价值函数 Q(s, a; θ’_t)来稳定动作价值函数的估计。为了训练 DRL agent,FL 中央服务器首先执行随机设备选择来初始化状态。如图 18 所示,状态输入到 DDQN 之一,DQN 产生一个动作 a 来为 FL 中央服务器选择设备。经过几轮 FL 训练后,DRL agent 通过解决下式已经取样了一些动作状态对:
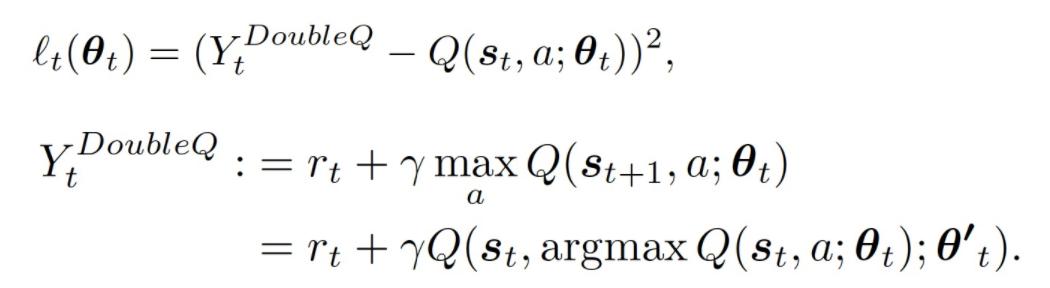 最后,利用下式更新价值函数 Q(s_(t+1), a; θ_t):
最后,利用下式更新价值函数 Q(s_(t+1), a; θ_t):4.3 实验分析
作者使用 PyTorch 实现了约 2000 行代码的 FAVOR,并将其作为一个开源项目发布。通过 Python 线程库,FAVOR 可以用轻量级线程模拟大量的设备,每个设备都可以运行真实世界的 PyTorch 模型。通过在三个基准数据库上训练 CNN 模型来评估 FAVOR,包括 MNIST、Fashion MNIST 和 CIFAR-10,以 FEDAVG 和 K 中心聚类(K-Center)作为对比组。在联邦学习中,由于移动设备的计算能力和网络带宽有限,减少通信轮数是至关重要的。因此,作者将通信轮数作为 FAVOR 的性能指标。
作者通过在不同级别的 Non-IID 数据中的实验来证明 FAVOR 的有效性。作者将 FEDAVG 和 K-Center 的性能作为比较基线。在每一轮中选择设备的数量 K 被设置为 10。使用四个不同级别的 No-IID 数据来表示:σ =1.0 表示每个设备上的数据只属于一个标签类别。σ=0.8 表示每个设备上的数据有 80% 属于一个标签类别,而其余 20% 属于另外一个标签类别。σ=0.5 表示每个设备上的数据有 50% 属于一个标签类别,而其余 50% 属于另外一个标签类别。σ =0 表示每台设备上的数据是独立同分布的(IID),σ =H 表示每个设备上的数据平均属于两个标签类别。作者报告了三个基准库上的联邦学习 “测试准确度 vs 通讯轮数” 实验结果(图 18 - 图 20)。实验结果表明,K-Cente 并不能保证一定优于 FEDAVG。与 FEDAVG 随机选择的设备相比,从 K-Center 集群中选择的设备可能会给联邦学习引入更多的偏差。不过,与 FEDAVG 相比 FAVOR 在 MNIST 上减少了高达 49% 的通信轮数,在 FashionMNIST 上减少了 23%,在 CIFAR-10 上减少了 42%。
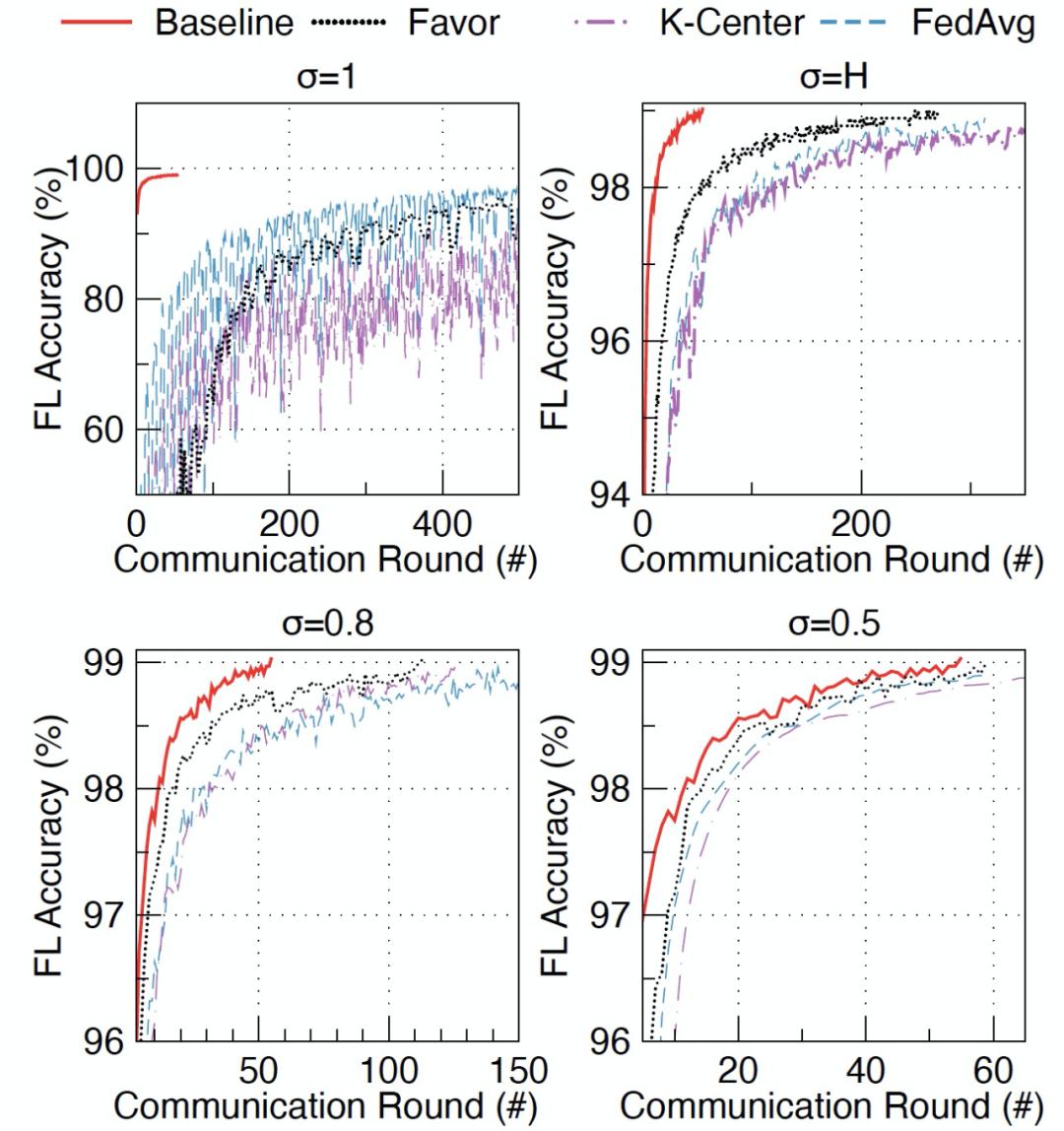 图 18. MNIST 库中不同级别 Non-IID 数据中 准确度 vs 通讯轮数 对比
图 18. MNIST 库中不同级别 Non-IID 数据中 准确度 vs 通讯轮数 对比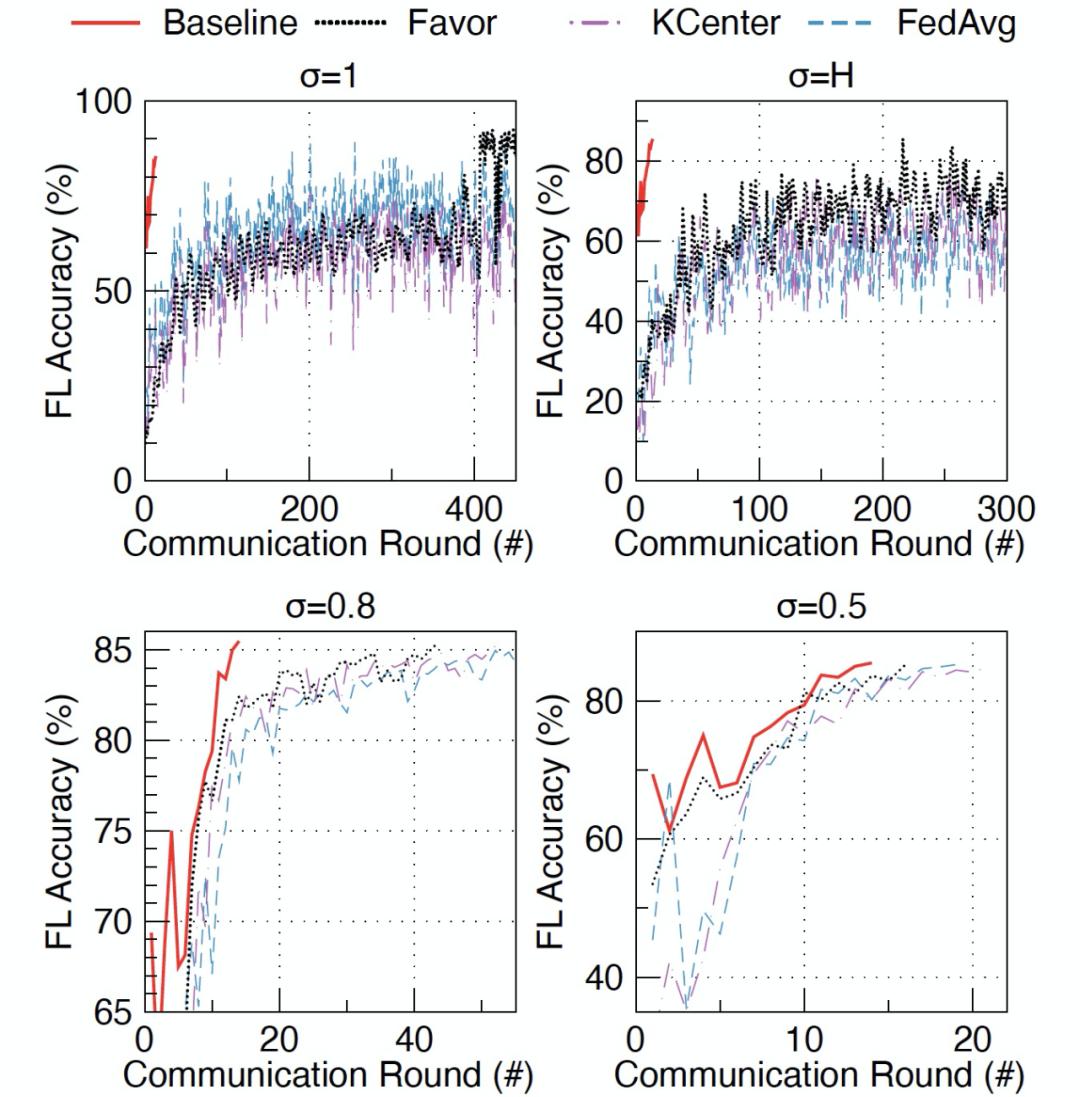 图 19. FashionMNIST 库中不同级别 Non-IID 数据中 准确度 vs 通讯轮数 对比
图 19. FashionMNIST 库中不同级别 Non-IID 数据中 准确度 vs 通讯轮数 对比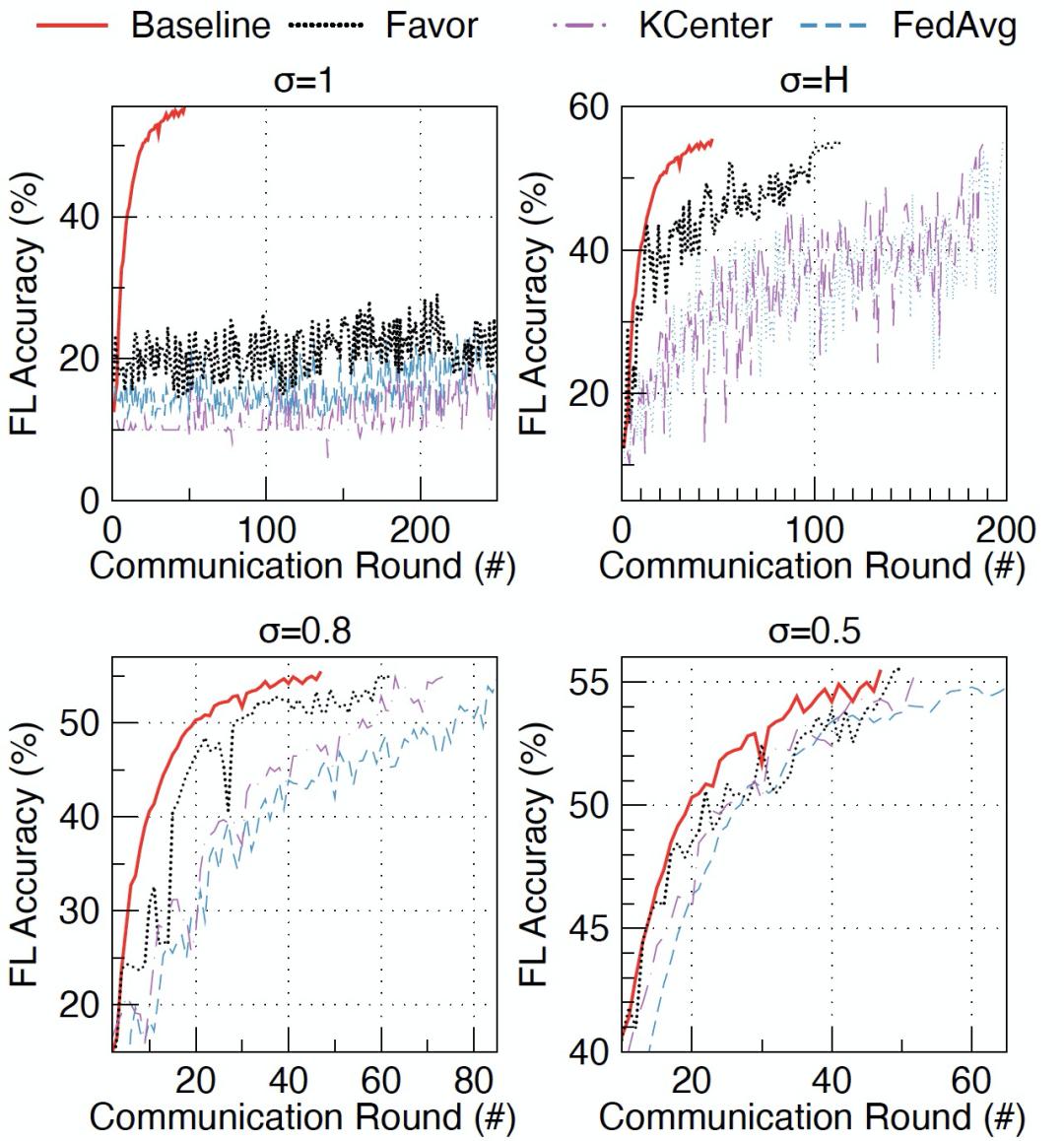 图 20. CIFAR-10 库中不同级别 Non-IID 数据中 准确度 vs 通讯轮数 对比
图 20. CIFAR-10 库中不同级别 Non-IID 数据中 准确度 vs 通讯轮数 对比作者在 MNIST 上训练两层 CNN,每一轮保存全局模型权重和局部模型权重,权重σ=0.8。将保存的模型权重通过 PCA 降维为二维向量,并绘制在图 21 中。对比分别用 FEDAVG 和 FAVOR 训练的模型权重可以发现,FAVOR 能够在早期训练轮次中以更大的权重更新来更新全局模型的权重,从而使得其收敛速度比 FEDAVG 更快。
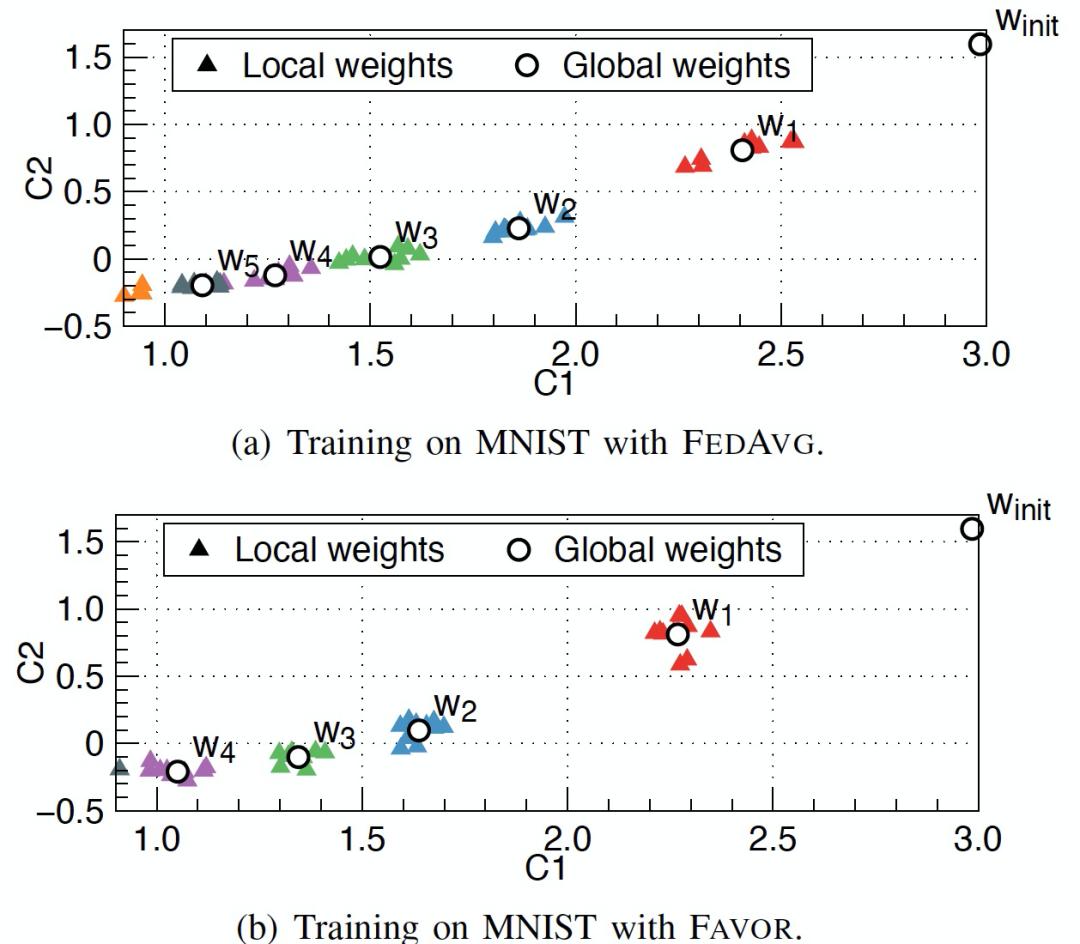 图 21. MNIST 库中对 FL 训练的模型权重进行 PCA 分析,ω_1,ω_2,...,ω_5 分别表示第 1-5 轮的全局模型权重
图 21. MNIST 库中对 FL 训练的模型权重进行 PCA 分析,ω_1,ω_2,...,ω_5 分别表示第 1-5 轮的全局模型权重5、一种延迟梯度的混合联邦学习算法[7]
 本文是 2021 年最新的一篇 ArXiv 预印文章。本文聚焦联邦学习中的 Stragglers,即联邦学习的低计算能力或通信带宽的物联网设备,特别是异构优化问题。分布式网络中的 Stragglers 大大降低了现有同步 FL 方法的训练速度,因为现有方法训练速度实际上是由最慢的设备决定的。为了减轻 stragglers 的影响, 本文提出了一种新型的 FL 算法,即混合联邦学习(Hybrid Federated Learning,HFL),以实现学习效率和效果的平衡 ------- 既考虑正常设备的同步学习,也考虑慢速设备(即 stragglers)的异步学习。
本文是 2021 年最新的一篇 ArXiv 预印文章。本文聚焦联邦学习中的 Stragglers,即联邦学习的低计算能力或通信带宽的物联网设备,特别是异构优化问题。分布式网络中的 Stragglers 大大降低了现有同步 FL 方法的训练速度,因为现有方法训练速度实际上是由最慢的设备决定的。为了减轻 stragglers 的影响, 本文提出了一种新型的 FL 算法,即混合联邦学习(Hybrid Federated Learning,HFL),以实现学习效率和效果的平衡 ------- 既考虑正常设备的同步学习,也考虑慢速设备(即 stragglers)的异步学习。5.1 方法介绍
经典 FL 中,所选的远程客户端设备从中央服务器接收当前的联邦模型,并通过随机梯度下降 (SGD) 进行本地训练,具体如下:
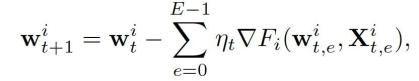 其中,(w_t)^i 表明第 t 轮收到的联合模型,η_t 为第 t 轮的学习效率,η_t 为中央服务器决定的,e 为局部训练 epoch 的指数,X^i 为训练样本。
其中,(w_t)^i 表明第 t 轮收到的联合模型,η_t 为第 t 轮的学习效率,η_t 为中央服务器决定的,e 为局部训练 epoch 的指数,X^i 为训练样本。在 HFL 中,中央服务器根据通信和计算性能将与其连接的远程设备分为两类:正常设备和 Stragglers。通常可以通过分析它们的历史行为来鉴别两类设备。使用 S1 表示正常设备的集合,S2 表示 Stragglers 的集合,其中 | S1|+|S2|=N。HFL 由两部分组成:同步内核(synchronous kernel),它在每一轮通信中与正常设备进行通信;异步更新器(asynchronous updater),它包含了来自 Stragglers 的延迟模型更新(即神经网络梯度)。
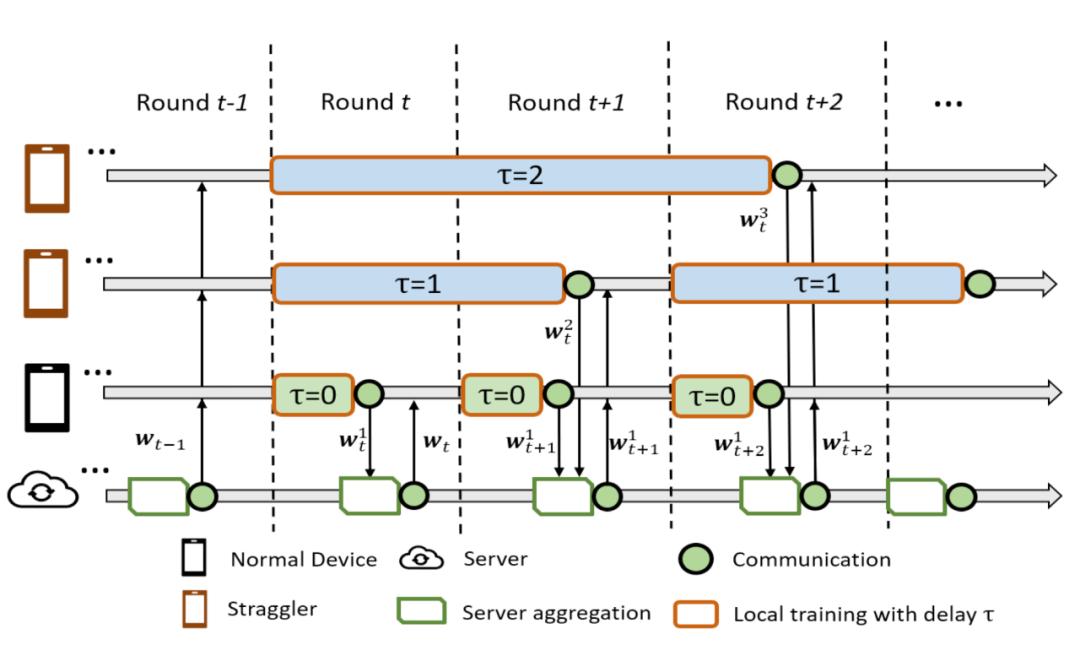 图 22. 在存在 Stragglers 的情况下,使用同步内核和异步更新器的 HFL 的联邦学习过程
图 22. 在存在 Stragglers 的情况下,使用同步内核和异步更新器的 HFL 的联邦学习过程首先,同步内核的模型更新过程为一序列局部更新的加权和。对于每个 Straggler,使用τ_i 表示当前序列的通信轮数。τ_i=0 表示正常设备。同步内核和异步更新器的联合模型为:
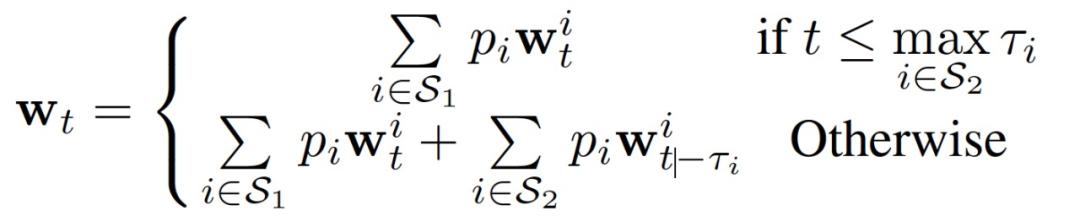 图 22 说明了在存在 Stragglers 的情况下,使用同步内核和异步更新器对所提出的 HFL 进行联合学习的过程,图中仅以一个正常设备和两个 Stragglers 为例。t=0 时,中央服务器初始化一个联合模型(joint model)并将其广播给所有设备。t=1 时,只有普通设备完成本地训练,并将其模型更新返回给中央服务器同步更新联合模型,由同步内核处理。t = 2 和 t = 3 时,当一个 Straggler 完成其局部训练时,异步更新器可以将延迟的模型更新纳入到联合模型中。显然,这种情况下主要的挑战是如何利用延迟的模型更新来完成当前联合模型的训练。上式所示的更新机制存在的问题是,在第 t 轮通信中,第 i 个 Stragglers 实际上会发回一个延迟的梯度。为了达到ω_t 的最优解,我们需要接近 "最新的" 梯度 ,这也是异步 SGD 优化领域的一个著名问题。此外,FL 网络中的 Stragglers 可能具有各种计算能力,这导致τ的分布极不平衡,因此,本文作者开发了一种自适应近似方案来解决这个问题。
图 22 说明了在存在 Stragglers 的情况下,使用同步内核和异步更新器对所提出的 HFL 进行联合学习的过程,图中仅以一个正常设备和两个 Stragglers 为例。t=0 时,中央服务器初始化一个联合模型(joint model)并将其广播给所有设备。t=1 时,只有普通设备完成本地训练,并将其模型更新返回给中央服务器同步更新联合模型,由同步内核处理。t = 2 和 t = 3 时,当一个 Straggler 完成其局部训练时,异步更新器可以将延迟的模型更新纳入到联合模型中。显然,这种情况下主要的挑战是如何利用延迟的模型更新来完成当前联合模型的训练。上式所示的更新机制存在的问题是,在第 t 轮通信中,第 i 个 Stragglers 实际上会发回一个延迟的梯度。为了达到ω_t 的最优解,我们需要接近 "最新的" 梯度 ,这也是异步 SGD 优化领域的一个著名问题。此外,FL 网络中的 Stragglers 可能具有各种计算能力,这导致τ的分布极不平衡,因此,本文作者开发了一种自适应近似方案来解决这个问题。首先,作者介绍自适应近似法。为便于表述,本文其余部分省略指数 i。
Taylor Expansion。作者应用 Taylor Expansion 对当前联合模型在 (t- τ) 步时的梯度更新 g(w_t)进行如下展开:
其中,I_n 为 n 为全 1 向量。梯度为:
在 g(w_t)的 Taylor expansion g(w_(t-τ))为零阶项。而预期模型梯度 g(w_t)和延迟模型梯度 g(w_(t-τ))之间的主要差异来自于高阶分量。我们可以使用上式中的 full Taylor expansion 逼近 g(w_t)。然而,由于其计算成本非常高这种做法是不现实的。此外,即使求解一阶项也是非常困难的,这一般被认为是一个联合损失函数的 Hessian 矩阵 H(w_(t-τ))。
Hessian 矩阵的逼近。由于在 FL 网络中 Hessisan 矩阵的计算成本非常高,我们考虑采用另一种方法,在有限的计算资源下解决这个问题。使用局部训练过程中计算出的联合模型 g(w_(t-τ))的梯度。具体的, 得到外积矩阵如下:
外积矩阵和 Hessian 矩阵是计算 fisher 信息矩阵的两种等效方法,因为在这种情况下,交叉熵损失相对于 softmax 函数是负对数似然。利用梯度外积来逼近 Hessian 矩阵,最佳梯度 g(w_t)可以表示如下:
然而,由于在 Taylor expansion 中忽略了高阶项,这种近似仍然可能存在问题,特别是当延迟τ较大时问题可能会更加严重。而在 FL 网络设置中, 这种设备出现的延迟是非常常见的现象。为了减少来自不同 Stragglers 的影响,作者引入了一个自适应的超参数来控制近似在联合模型聚合中的权重,该超参数与延迟τ和训练轮次 t 的值有关。主要思想是,一个较慢的 Stragglers(即较大的延迟τ)对联合模型训练的贡献较小,当通信回合的轮次增加 (即 t) 时,这个贡献不断减少,以减小学习收敛时的振荡。本文的 AD-SGD(Adaptive -SGD)方法引入了一个在 t 和τ上指数衰减函数的超参数λ_t,如下所示:
其中,λ_0 为用户自定义参数,本文实验中使用λ_0=10。利用 AD-SGD 方法,HFL 算法的联合模型更新为:
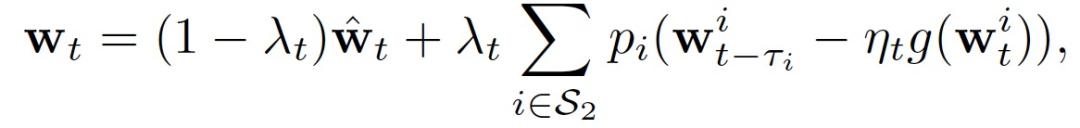 作者使用 AD-SGD 方法来解决 FL 中 Stragglers 的延迟梯度和最佳梯度之间的差距问题。具体的,使用计算成本较低的外积梯度来逼近 Hessian 矩阵,在上文作者已经证明其与 Fisher 信息矩阵的计算是等价的。在 AD-SGD 的帮助下,当 FL 中存在 Stragglers 时能够实现学习效率和效果的平衡。
作者使用 AD-SGD 方法来解决 FL 中 Stragglers 的延迟梯度和最佳梯度之间的差距问题。具体的,使用计算成本较低的外积梯度来逼近 Hessian 矩阵,在上文作者已经证明其与 Fisher 信息矩阵的计算是等价的。在 AD-SGD 的帮助下,当 FL 中存在 Stragglers 时能够实现学习效率和效果的平衡。作者将提出的 HFL 算法总结为 Algorithm 1 和 Algorithm 2,其中 Algorithm 1 介绍了局部学习过程,Algorithm 2 给出了联合模型更新机制。根据 Algorithm 1,第 t 轮中第 i 个远程设备从中央服务器接收到当前的联合模型 w_t,以 E 个 epoch 执行本地训练过程,并在第 (t+τ_i) 轮将模型更新发送回中央服务器,同时对 Stragglers 有不同的延迟。对于中央服务器端,与现有的 FL 方法不同的是,中央服务器在第 t 轮时,当 straggler 接收到联合模型时会存储一个备份模型。当中央服务器在 (t+τ ) 轮接收到延迟梯度时,中央服务器根据更新规则更新联合模型
 与现有的同步 FL 算法相比,在 HFL 中没有额外的通信轮次和额外的远程设备计算需求。特别是,近似成本主要来自于中央服务器上额外存储的几个以前的联合模型。不过,对前一个联合模型的备份并不违反 FL 网络的隐私设置。
与现有的同步 FL 算法相比,在 HFL 中没有额外的通信轮次和额外的远程设备计算需求。特别是,近似成本主要来自于中央服务器上额外存储的几个以前的联合模型。不过,对前一个联合模型的备份并不违反 FL 网络的隐私设置。5.2 实验分析
为了评估所提出的 HFL 算法的性能,作者在多个数据库上进行了凸优化和非凸优化问题的实验。对于凸优化,作者在 FasionMNIST 和合成数据集上设计了逻辑回归模型的实验。作者将训练样本按照幂律分布分配到不同的远程设备上,以得到 Non-IID 分布式学习数据。对于非凸优化,作者选择使用 LSTM 分类器的 Sent140 和 Shakespeare。对比方法包括 Sequential SGD(S-SGD)、经典 FedAvg 和 FedProx(FedProx 是 FedAvg 的一个流行变体,它增加了一个二次近似项以限制异构网络中本地更新的影响)。
5.2.1 凸优化问题
图 23 比较了使用逻辑回归的合成数据库和 FashionMNIST 数据库的凸优化学习性能。结果表明,与其他方法相比 HFL 达到了最好的整体测试准确度。对于 FashionMNIST 数据库,使用 S-SGD 方法对 FashionMNIST 的上界测试准确度为 84.58%,而 HFL 达到 83.41% 的测试准确度。同时,FedAvg 的收敛准确度只有 71.92%,FedProx 的收敛准确度只有 75.49%。HFL 的学习曲线存在一些明显的振荡,作者分析这主要来自于从延迟梯度对最优模型的逼近。对于合成数据集,作者评估了 HFL 在两种γ和ξ设置下的性能,即 Synthetic(0, 0)和 Synthetic(1, 1),结果如图 23b-23c 所示。与 FashionMNIST 数据库的结果相比,HFL 在两个合成数据库上的性能提升都大于其它方法。同时,HFL 的收敛速度在 Synthetic(1,1)中比 Synthetic(0,0)慢。作者分析原因可能是数据异质性的增加会使收敛速度更依赖于延迟值 。
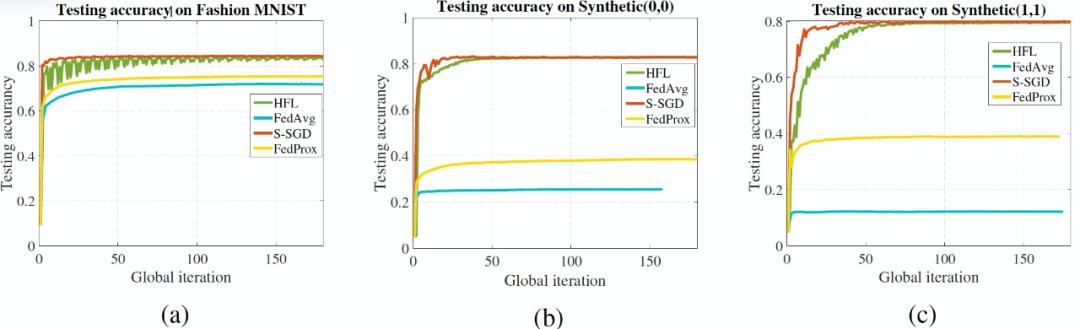 图 23. 凸数据集上的实验结果
图 23. 凸数据集上的实验结果5.2.2 非凸优化问题
作者评估了 HFL 在非凸优化问题上的性能,提供了 HFL 与现有 FL 方法在 Sent140 和 Shakespeare 数据库上训练 LSTM 分类器的对比结果。图 24a 和 24b 中的结果表明,HFL 在 Sent140 上与现有的 FL 算法相比,整体测试准确度和训练损失都是最好的。特别是图 24a 中的结果表明,虽然 HFL 与 FedAvg 和 FedProx 相比收敛速度较慢,但测试准确度却明显提高。虽然在 HFL 的训练过程中存在明显的振荡,但作者认为 HFL 振荡的幅度与其他 FL 算法相比是可以容忍。
图 24c-24d 显示了在 Shakespeare 数据库上的比较结果。与 FedAvg 和 FedProx 相比,HFL 获得的测试准确度和训练损失都有所提高。虽然结果显示 HFL 与 S-SGD 方法有明显的差距,且在该数据库中 HFL 的收敛速度较慢,但 HFL 仍优于 FedAvg 和 FedProx,因为其训练损失无过拟合,测试准确度至少提高了 12%。综上所述,作者认为所提出的 HFL 与其他 FL 方法相比,在求解非凸优化问题时具有更好的性能。
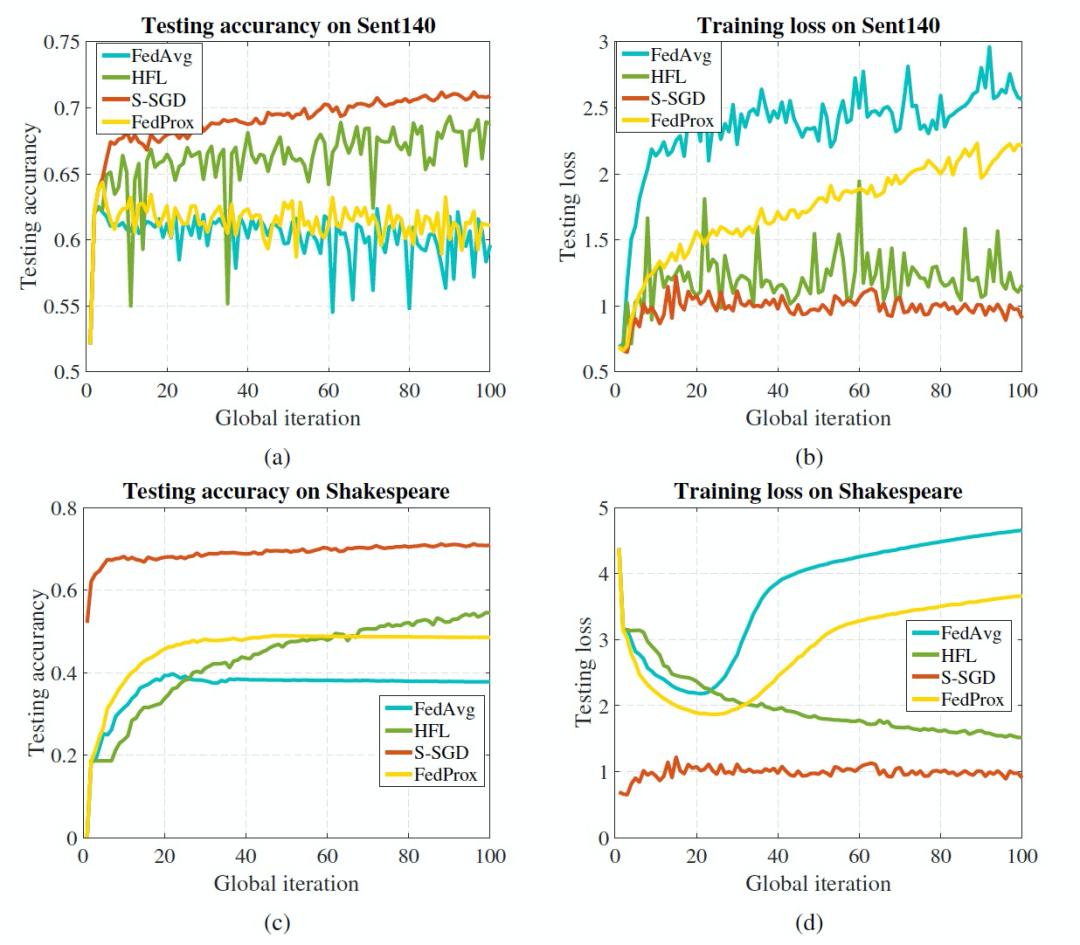 图 24. HFL 与现有方法在非凸数据库上的学习性能比较
图 24. HFL 与现有方法在非凸数据库上的学习性能比较6、联邦学习中的选择:聚合分析和选择权选择策略[9]
 本文是 CMU 研究人员在 2020 年发表的预印本文章。在异构环境中,通过优先选择本地模型损耗值(loss value)较高的客户端,可以急剧加速误差收敛从而提升通信效率,因此分析和理解有偏客户端选择策略非常重要。在我们分析的第二篇文章《Communication-efficient Federated Learning via Optimal Client Sampling》中就提出了根据客户端权重进行客户端选择的方法。不过这篇文章的作者认为该方案仅限于经验证明,没有严格分析选择偏差如何影响收敛速度。
本文是 CMU 研究人员在 2020 年发表的预印本文章。在异构环境中,通过优先选择本地模型损耗值(loss value)较高的客户端,可以急剧加速误差收敛从而提升通信效率,因此分析和理解有偏客户端选择策略非常重要。在我们分析的第二篇文章《Communication-efficient Federated Learning via Optimal Client Sampling》中就提出了根据客户端权重进行客户端选择的方法。不过这篇文章的作者认为该方案仅限于经验证明,没有严格分析选择偏差如何影响收敛速度。本文提出了(据作者所知)第一个有偏客户端选择的联邦学习的收敛性分析。作者发现,与无偏客户端选择的方法相比,偏向选择本地损失较高的客户端会提高收敛速度。
6.1 问题分析过程
考虑一个 K 个客户端的联邦学习问题,其中有 k 个客户端拥有 B_k 本地数据库 | B_k|=D_k。中央服务器聚合客户端并试图找到最小化经验风险的模型参数 w:
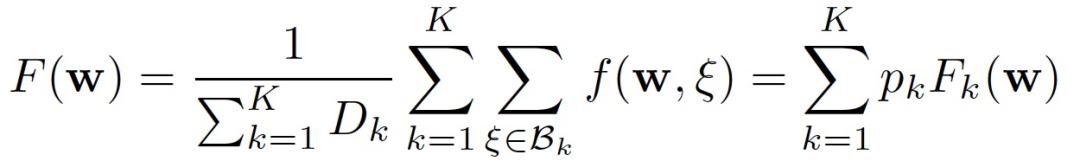 其中,f(w,ξ)为样本ξ和参数向量 w 组成的复合损失函数。在联邦学习问题中,满足 F(w)最优化的 w * 和满足 F_k(w)最优化的 w*_k 可能区别很大。
其中,f(w,ξ)为样本ξ和参数向量 w 组成的复合损失函数。在联邦学习问题中,满足 F(w)最优化的 w * 和满足 F_k(w)最优化的 w*_k 可能区别很大。经典联邦学习方法(例如 FedAvg)将训练分为几轮通信。在每一轮,为了节省中央服务器的通信成本,只选择 m=C*K 个客户端(C 为选择比例)参加训练。每个选定的 / 活跃的客户端执行本地 SGD 的迭代,并将其本地更新的模型送回中央服务器。然后,中央服务器使用本地模型更新全局模型,并将全局模型广播给一组新的活跃客户端。
比如,第 t 轮更新中的活跃客户端集合为 S^(t)。每台活跃客户端进行τ步局部更新,因此,S^(t)在每τ次迭代过程中保持恒定,即每τ次迭代中 FL 中央服务器不会重新挑选活跃的客户端。即
即,FedAvg 的更新规则为:
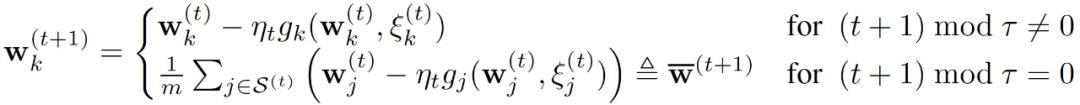 其中,当 (t+1) mod τ ≠ 0 时,进行本地模型更新;当(t+1) mod τ = 0 时,进行全局模型更新,同时设备获得更新后的全局模型。根据客户端 k 的局部数据库 B_k 随机抽样得到的大小为 b 的 mini-batch ξ_k^(t) 的随机梯度为:
其中,当 (t+1) mod τ ≠ 0 时,进行本地模型更新;当(t+1) mod τ = 0 时,进行全局模型更新,同时设备获得更新后的全局模型。根据客户端 k 的局部数据库 B_k 随机抽样得到的大小为 b 的 mini-batch ξ_k^(t) 的随机梯度为:中央服务器中的全局模型更新过程为:
FedAvg 中以概率 p_k 随机选择客户端 k,每次选择 m 个客户端参与训练。这种抽样方案是无偏的,因此,它具有与局部更新 SGD 方法相同的收敛特性。
本文考虑了一种能够认知全局训练进度的有偏客户端选择策略。如图 24 所示,在两个客户端的场景下我们做如下设定:
即保证所选客户端中,单个客户端的局部损失函数值最高。具体的,如图 25 中以 F1(w)、F2(w)为局部目标,F(w)=(F1(w)+F2(w))/2 为全局目标函数,全局最小值为 w∗。在每一轮中,只选择一个客户端进行局部更新。如图 25 (a)损失较大的抽样客户的模型更新。图 25(b)中,均匀随机抽取客户端的本地模型更新(图中按 2,2,1,1,2 的顺序选择客户端)。
在该示例中,客户端选择策略不能保证更新等于全部客户端参与情况下的期望。然而,它比随机选择策略的收敛速度更快,可以达到全局最小值。由此,作者将客户端选择策略π定义为将当前的全局模型 w 映射到选定的客户端集 S(π;w)的函数。
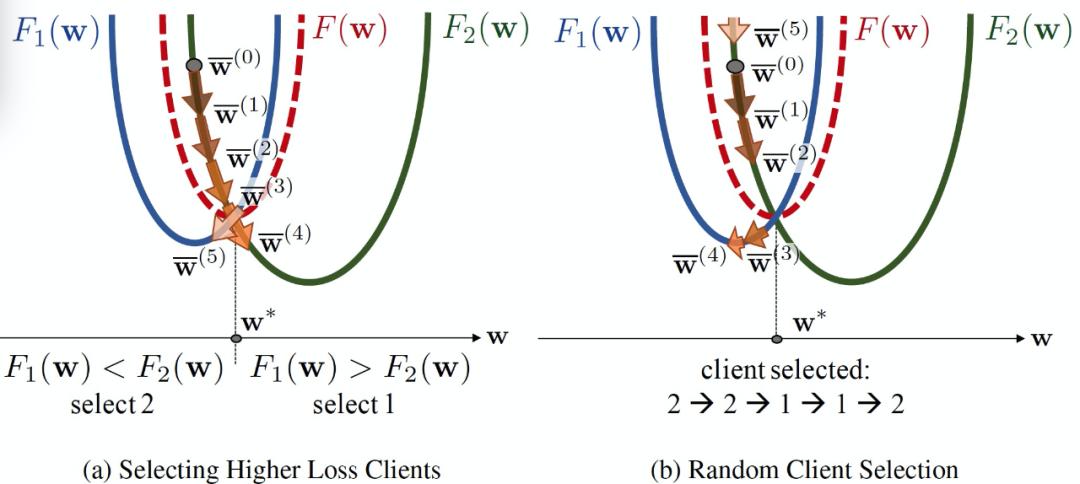 图 25. 有偏客户端选择示例
图 25. 有偏客户端选择示例作者在原文中分析了任意客户端选择策略π的联邦聚合方法的收敛性。作者分析表示,有偏客户端选择可以导致更快的收敛,尽管在真正的最优方案之间仍存在着不消失差距(non-vanishing gap)的风险:
详细的数学论证过程我们在这里不赘述,感兴趣的读者可以阅读原文。
对于全局最优 w * 和局部最优 w*_k,作者定义了局部 - 全局目标差距(Local-Global Objective Gap)为:
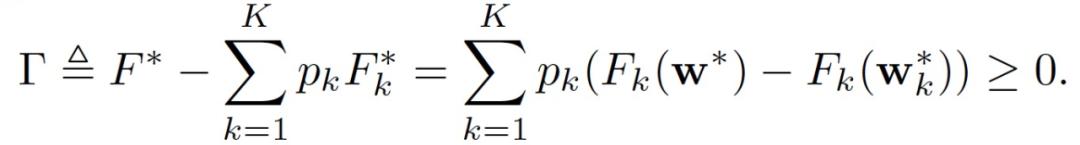 其中,Γ表示局部和全局目标函数的固有属性,与客户端选择策略无关。Γ越大意味着数据的异质性越高。如果Γ=0,则意味着局部最优值和全局最优值是一致的,不存在由于客户端选择策略而导致的解偏差。接下来,作者定义了另一个度量方法称为选择偏斜(Selction skew),它反映了客户端选择策略对局部 - 全局目标差距的影响:
其中,Γ表示局部和全局目标函数的固有属性,与客户端选择策略无关。Γ越大意味着数据的异质性越高。如果Γ=0,则意味着局部最优值和全局最优值是一致的,不存在由于客户端选择策略而导致的解偏差。接下来,作者定义了另一个度量方法称为选择偏斜(Selction skew),它反映了客户端选择策略对局部 - 全局目标差距的影响: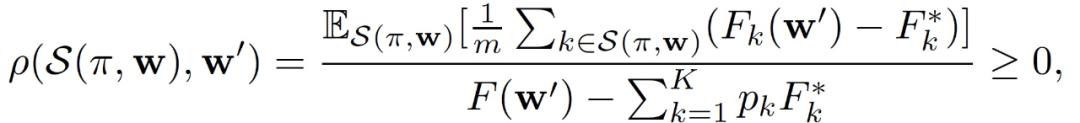 ρ反映了客户选择策略π的倾斜性(skew)。ρ(S(π,w),w’)是全局模型 w 和 w’的函数,在训练过程中发生变化。作者定义与 w 和 w’无关的两个度量标准如下,这两个标准能够表征收敛性分析的保守误差范围:
ρ反映了客户选择策略π的倾斜性(skew)。ρ(S(π,w),w’)是全局模型 w 和 w’的函数,在训练过程中发生变化。作者定义与 w 和 w’无关的两个度量标准如下,这两个标准能够表征收敛性分析的保守误差范围: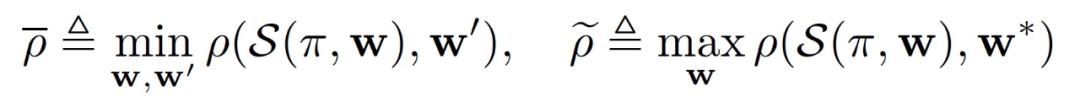 由作者的分析可知,一个优先选择较大 F_k(w)-F*_k 客户端的选择策略π,将会导致更大的ρ并产生更快的收敛速度。因此,客户端选择策略可以简单确定为选择局部损失最大的客户端 F_k(w)。然而,较大的选择偏斜可能导致较大的不消失误差项。这种简单的选择策略还有一个缺点是:要找到当前的局部损失 F_k(w),需要将当前的全局模型发送给所有 K 个客户端,让他们评估 F_k 后再发回至中央服务器。这种额外的通信和计算成本可能会非常高,因为客户端 K 的数量通常非常大,而这些客户端的通信和计算能力有限。
由作者的分析可知,一个优先选择较大 F_k(w)-F*_k 客户端的选择策略π,将会导致更大的ρ并产生更快的收敛速度。因此,客户端选择策略可以简单确定为选择局部损失最大的客户端 F_k(w)。然而,较大的选择偏斜可能导致较大的不消失误差项。这种简单的选择策略还有一个缺点是:要找到当前的局部损失 F_k(w),需要将当前的全局模型发送给所有 K 个客户端,让他们评估 F_k 后再发回至中央服务器。这种额外的通信和计算成本可能会非常高,因为客户端 K 的数量通常非常大,而这些客户端的通信和计算能力有限。作者根据这些关于收敛速度、解偏差和通信 / 计算开销之间权衡的分析,提出了 Power-of-Choice 客户端选择策略(记做π_pow-d)。Power-of-Choice 是一种基于 d 个选择的幂级负载均衡策略,该策略在队列系统中得到了广泛的应用。在 Power-of-Choice 客户端选择策略中,中央服务器选择活跃客户端集 S^(t),具体如下:
1. 对候选客户端集进行采样。中央服务器对 d 个客户端的候选集 A 进行采样而不进行替换操作,这样选择客户端 k 的概率为 p_k,即第 k 个客户端的数据分数。
2. 估计本地损耗。中央服务器将当前的全局模型 w^(t)发送给候选集 A 中的客户端,这些客户端计算并将其本地损失 F_k(w^(t))反馈给中央服务器。
3. 选择损失最大的客户端。从候选集 A 中,中央服务器通过选择 m = max(CK, 1)个具有最大值 F_k(w)的客户端构建活跃客户端集 S^(t)。
π_pow-d 的可变性。π_pow-d 的三个步骤可以根据实际情况灵活修改。例如,在步骤 1 中,可以通过仅从该轮中的可用客户端集构建集 A 来核算间歇性客户端的可用性。本文介绍了两种变体方法:π_cpow-d 和π_rpow-d。
高效计算的变种π_cpow-d:为了节省局部计算成本,作者不通过遍历整个局部数据集 B_k 的方式评估 F_k(w),而是使用如下估计值:
其中的ξ_k 为 B_k 中采样的 b 个样本的 mini-batch。
有效传输和高效计算的变种π_rpow-d:为了节省本地计算和通信成本,每一轮选定的客户端向中央服务器发送本地模型时都会发送其在本地迭代中的累计平均损失:
Power-of-Choice 策略的选择偏斜度。候选客户集 A 的大小 d 是一个重要的参数,它控制着收敛速度和求解偏差之间的权衡。在 d=m 的情况下,我们按 p_k 的比例进行无替换的随机抽样。随着 d 的增加,这些选择偏斜度增加误差收敛速度加快,但有可能出现较高的误差底线。在实际应用中,训练阶段的收敛速度和解的偏差变化由以下因素决定:
随着 π_pow-d 偏向于较高的局部损失,作者期望通过训练过程减少选择偏斜ρ(w, w’)。
6.2 实验分析
本文通过三组实验验证所提出方法的有效性:(1)二次优化,(2)合成联邦数据库上的逻辑回归,Synthetic(1,1),(3)Non-IID 分区的 FMNIST 数据库上训练 DNN。其中,π_cpow-d 和π_rpow-d 分别为π_pow-d 的变体,π_rand 为随机选择客户端的方法,π_afl 为主动联邦学习方法[10]。
由图 26(a),在客户端数量较少的情况下(K=30),π_pow-d 比π_rand 收敛速度快,而较小 d 的偏差几乎可以忽略不计。收敛速度随着 d 的增大而增加,但相应的代价是由于解偏差而导致误差底线的提高。K=100 时,π_pow-d 的收敛速度与 K=30 时一样,但偏差较小。图 26(b)给出分别表征收敛分析中的收敛速度和解的偏差的理论值。与π_rand 相比,π_pow-d 具有较高的收敛速度理论值,表明π_pow-d 其收敛速度较快。通过改变 d,我们可以得到收敛速度和偏差之间的不同权衡结果。d=15、K=100 时,π_pow-d 和π_rand 解的偏差的理论值几乎相等,而π_pow-d 的收敛速度理论值较大,表明π_pow-d 能够在几乎可忽略的解偏差的情况下以较快速度收敛。
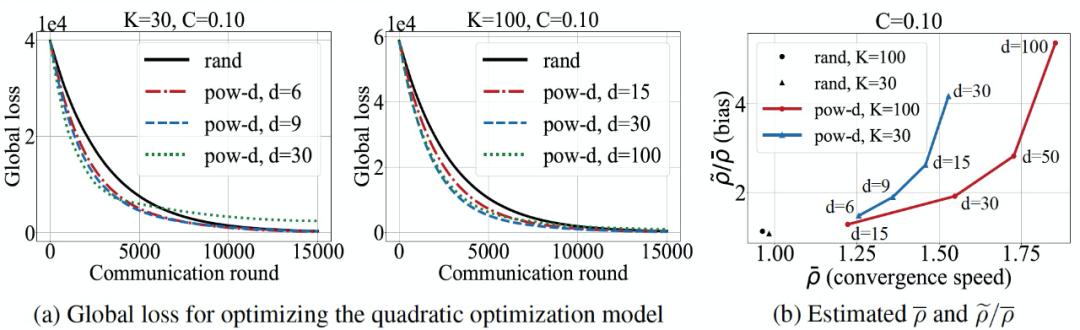 图 26. 二次优化实验中π_pow-d 的性能
图 26. 二次优化实验中π_pow-d 的性能图 27 中给出了合成数据库中的实验结果,具体为不同 d 和 m 取值情况下π_pow-d 和π_rand 的全局损失。当 d=10m 时,π_pow-d 收敛到全局损失约为 0.5 的速度比π_rand 快三倍,误差底线略高。d=2m 时,π_pow-d 收敛到全局损失约 0.5 的速度比π_rand 快约两倍。
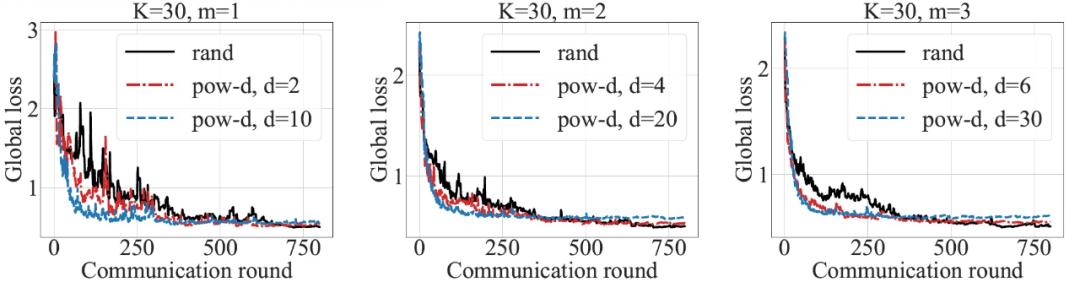 图 27. 合成数据库上逻辑回归的全局损失
图 27. 合成数据库上逻辑回归的全局损失参数α决定了不同客户端的数据异质性程度,较小的α表征较大的异质性。图 28 中展示了 FMNIST 库中α=0.3 和α=2 的不同采样策略的测试准确度和训练损失。我们可以看出,α=0.3 和α=2 时,与π_rand 和π_afl 相比π_pow-d 能够分别获得 10% 和 5% 的测试准确度提升。对于较大的α值来说(数据异质性程度较低),较大的 d 值(更多的选择偏斜)比较小 d 值的性能要好。图 28(a)显示这种由于 d 的增大而带来的性能改善最终会趋于一致。对于较小的α ,如图 28(b)所示,较小的 d=6 比较大的 d 表现更好,这说明在数据异质性存在的情况下,过多的求解偏差对性能是不利的。训练损失的观察结果与测试准确度结果一致。
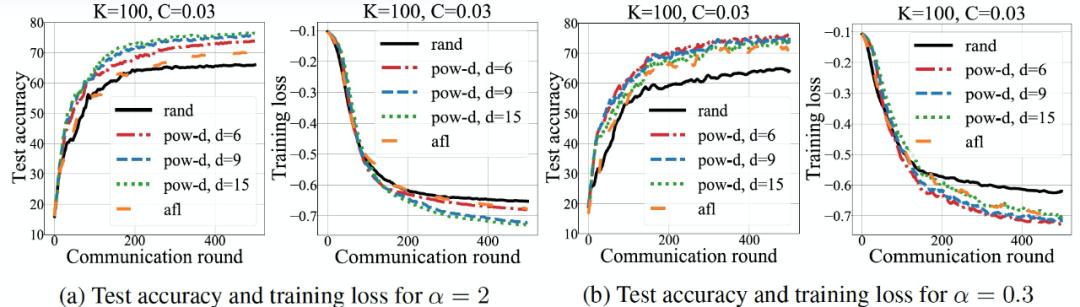 图 28. 在 FMNIST 数据库上不同 d 值情况下不同采样策略的测试准确度和训练损失,K=100,C=0.03
图 28. 在 FMNIST 数据库上不同 d 值情况下不同采样策略的测试准确度和训练损失,K=100,C=0.03最后,作者通过实验验证了两种变体方法的有效性。如图 29 所示,α=2,π_rpow-d 和π_cpow-d 的准确率分别比π_rand 高约 5% 和 6%,但两者的准确率都低于利用最高计算和通信资源的π_pow-d。α=3,π_cpow-d 和π_rpow-d 的性能与π_pow-d 相当,比π_rand 的准确度提高了 10%。此外,π_pow-d、π_rpow-d 和π_cpow-d 都比π_alf 具有更高的准确度和更快的收敛性。
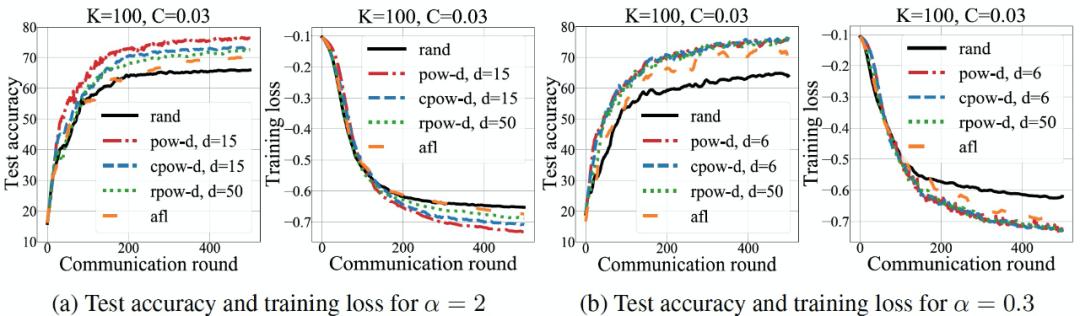 图 29. 不同抽样策略的测试准确度和训练损失
图 29. 不同抽样策略的测试准确度和训练损失7、 本文小结
我们通过六篇近期发表的论文详细讨论了联邦学习中的客户端选择问题。
第一篇文章主要考虑的是联邦学习环境中不同客户端存在的资源异构性问题,在这种异构性的前提下无差别的随机选择客户端会影响 FL 的性能。作者针对这个问题进行了充分的理论分析和量化实验验证。作者的分析过程能够帮助我们快速的了解这一问题。作者的应对方法是根据训练时间将客户端进行分层,再对每层级中的客户端进行控制选择。
第二篇文章的关注点是“高效通信的联邦学习 ”,因此其出发点是解决 FL 中客户端与中央服务器之间的通信问题。作者解决通信问题的思路是有效选择每轮参与的客户端。作者提出了一种简单、高效的在通信约束环境下更新全局模型的方法:阈值化的从有信息更新的客户端中收集模型,并估计没有进行通信的客户端中的局部更新,即只有当客户端的模型更新的范数超过一个预先确定的通信阈值时(表征有信息更新),客户端才会将其计算得到的模型权重传送给中央服务器。。由文中给出的分析和实验结果,作者表示并没有一种方法在探索准确度 - 通信权衡方面具有绝对的优势。但本文提出的阈值化策略是一种有效的方法,可以在不明显降低准确度的情况下对客户端进行再选择。
第三篇文章提出了一种通过引导参与者选择以提高联邦训练和测试的性能的方法。Oort 优先使用那些既拥有对提高模型准确度有较大作用的数据,又具备快速执行训练能力的客户端。作者引入重要性采样的方法进行客户端选择,即通过效用来选择客户端。此外,本文还开发了一种探索利用(exploration-exploitation strategy)策略来选择参与者。在众多客户端中选择参与者的问题可以建模为一个多臂赌博机问题(a multi-armed bandit problem),每个客户端都是赌博机的 "摇臂",获得的效用就是 "报酬"。为了实现长期报酬的最大化,我们可以自适应地平衡不同摇臂的探索和利用。
第四篇文章聚焦的是 FL 环境中不同客户端设备中 Non-IID 数据对最终模型性能的影响,即 Non-IID 客户端数据造成了任何一个客户端都无法完全代表全局、基于各个客户端本地数据训练得到的模型聚合性能较差。因此作者提出了一个通过智能设备选择来提高联邦学习性能的 Favor 控制框架。该框架引入了强化学习的理念,通过在每一轮通信中学习选择最佳设备子集替代传统的随机选择方法,以抵消 Non-IID 数据引入的偏差。
第五篇文章中提出了一个混合式联邦学习框架(HFL),主要针对的是联邦学习环境中的 Stragglers 问题。HFL 包括一个同步内核和一个异步更新器,同步内核局部更新序列的加权求和,异步更新器将 stragglers 的模型更新纳入到联邦模型训练过程中。这样 HFL 做到了既考虑正常设备的同步学习,也考虑慢速设备(即 stragglers)的异步学习。
最后一篇文章针对有偏客户端选择的联邦学习进行了收敛性分析。这篇文章是根据本地损失来进行客户端选择的,引入了队列系统中常用的 Power-of-Choice 策略,该策略是一种基于 d 个选择的幂级负载均衡策略。作者通过理论分析和实验验证了与无偏客户端选择的方法相比,这种有偏客户端选择方式能够提高整个模型的收敛速度,能够实现收敛速度、解偏差和通信 / 计算开销之间权衡。
在我们介绍的六篇文章中,多位作者都分析和验证了随机选择客户端会对联邦学习带来的通信时间增长、模型准确度降低等问题。我们可以看到,在实际的应用场景中有选择的确定每轮参与训练的客户端对于提升 FL 的性能是非常重要的。随着联邦学习的不断发展和推广,客户端选择可能会成为技术落地的关键。
本文参考引用的文献
[1] Peter Kairouz, H. Brendan McMahan, et al. Advances and Open Problems in Federated Learning, https://arxiv.org/pdf/1912.04977.pdf
[2] T. Nishio and R. Yonetani. Client selection for federated learning with heterogeneous resources in mobile edge. In ICC 2019 - 2019 IEEE International Conference on Communications (ICC), pages 1-7, 2019. https://arxiv.org/pdf/1804.08333.pdf
[3] Zheng Chai, Ahsan Ali, et.al. TiFL: A Tier-based Federated Learning System, HPDC '20: Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing, June 2020 Pages 125–136. https://arxiv.org/pdf/2001.09249.pdf
[4] Monica Ribero, Haris Vikalo, Communication-Efficient Federated Learning via Optimal Client Sampling,https://arxiv.org/abs/2007.15197
[5] Fan Lai,Xiangfeng Zhu,Oort: Informed Participant Selection for Scalable Federated Learning,https://arxiv.org/abs/2010.06081
[6] Hao Wang, Zakhary Kaplan, Di Niu, Baochun Li. Optimizing Federated Learning on Non-IID Data with Reinforcement Learning. IEEE INFOCOM 2020.
[7] Xingyu Li, Zhe Qu, Bo Tang, Zhuo Lu, Stragglers Are Not Disaster: A Hybrid Federated Learning Algorithm with Delayed Gradients,https://arxiv.org/abs/2102.06329
[8] N. Guo and V. Kostina. Optimal causal rate-constrained sampling for a class of continuous markov processes. arXiv preprint arXiv:2002.01581, 2020.
[9] Yae Jee Cho, Jianyu Wang, Gauri Joshi, Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies, https://arxiv.org/abs/2007.15197
[10] Jack Goetz, Kshitiz Malik, Duc Bui, Seungwhan Moon, Honglei Liu, and Anuj Kumar. Active federated learning. ArXiv, 2019.
分析师介绍:
本文作者为仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
原标题:《加入联邦学习的客户端设备——随机选择真的好吗?》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

