- +1
AlphaGo之父对话《连线》:曾被导师劝阻研究强化学习,如今获得ACM计算奖
晓查 编译整理
量子位 报道 | 公众号 QbitAI
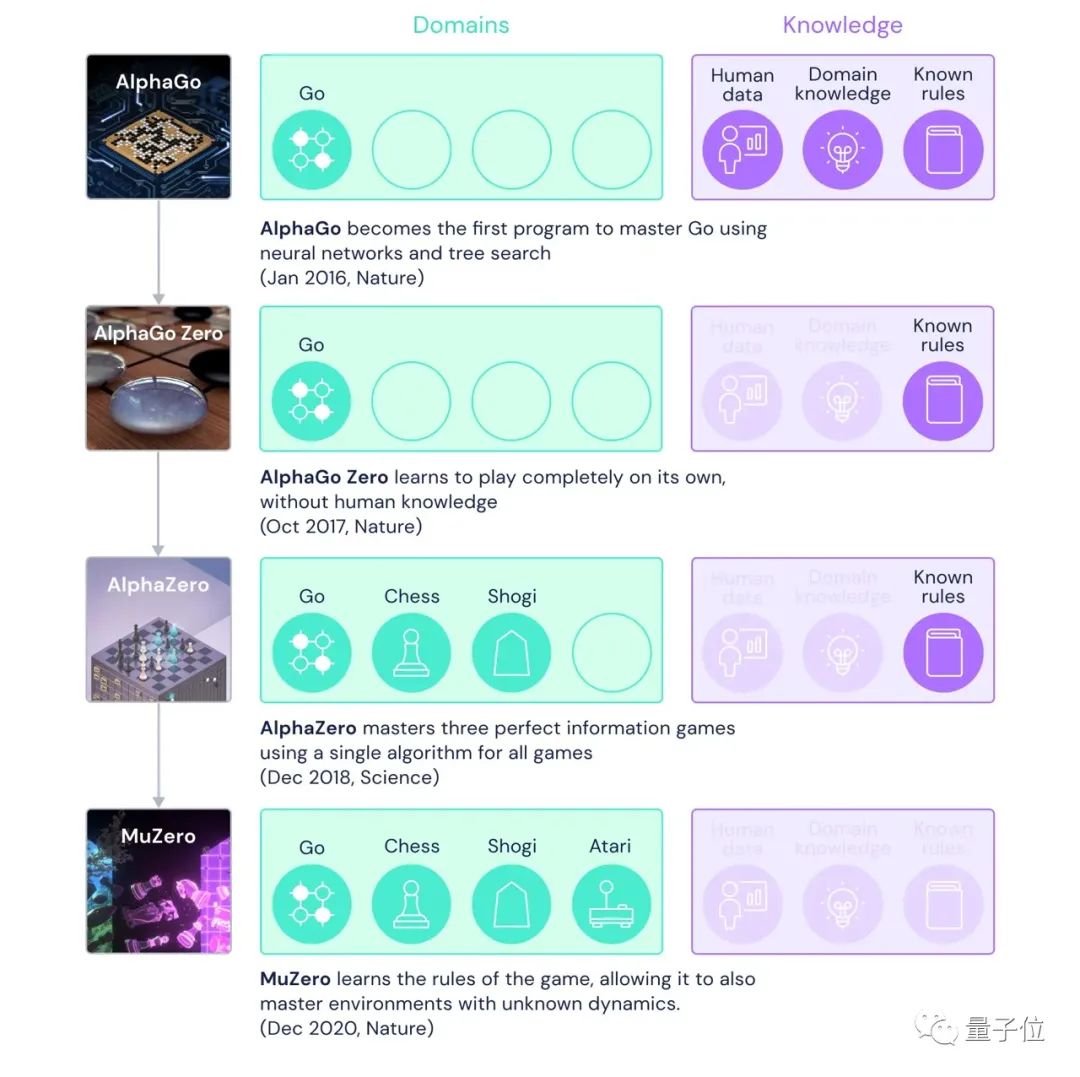
本周,DeepMind的MuZero通过了同行评审,发表在了最新一期的Nature杂志上。

MuZero是一个通用的游戏AI,它在围棋、象棋、将棋和57款Atari游戏上都超过了人类的表现。而且这个AI事先不需要事先知道规则。
近日,DeepMind的首席科学家、AlphaGo首席研究员David Silver接受了《连线》杂志的采访,讨论了MuZero、强化学习以及对未来通用人工智能的看法。

David Silver毕业于剑桥大学,在那里与DeepMind创始人Demis Hassabis成为朋友。
Silver曾领导DeepMind的强化学习研究小组,由于在计算机游戏领域的突破性进展,他获得了2019年ACM计算奖。
为何MuZero很重要
连线:MuZero发表在Nature杂志上。对于不了解此事人,告诉我们为什么它很重要。
David Silver:MuZero向前迈出的重要一步是,我们没有告诉它环境的动态。它必须自己想办法,让自己提前计划,想出最有效的策略。
我们希望拥有在现实世界中可以运行的算法,而现实世界却是复杂、混乱且未知的。所以你不能只向前看,就像下棋一样。你必须学会这个世界是如何运转的。

一些观察人士指出,MuZero、AlphaGo和AlphaZero并非真正零开始。它们使用聪明人设计的算法来学习如何执行特定任务。这是不是错过了重点?
我认为确实如此。从来没有真正的一片空白。机器学习中甚至有一个定理——没有自由午餐定理,就是说你必须从某件事开始,否则将一事无成。
但是在这种情况下,它是空白的。我们为它提供了一个神经网络,而神经网络必须从游戏的输赢或或分数的反馈中学会如何理解世界。
人们注意到的一件事是,我们告诉MuZero在每种情况下的合法举动。但是,如果你进行解决未知问题的强化学习,通常会告知智能体可以做什么。您必须告诉智能体它有哪些选择,然后让它再选择其中之一。
您可能会批评到目前为止我们已经做了什么。现实世界非常复杂,我们还没有建立像人类大脑那样可以适应所有这些事物的东西。所以这是一个公平的批评。
但是我认为MuZero确实自己找到了如何建立模型,并且从第一性原理去理解它。
MuZero有何实际用途
DeepMind最近宣布,已利用AlphaZero背后的技术解决了一个重要的实际问题:预测蛋白质折叠的形状。你认为MuZero将在哪方面产生首个重大影响?

当然,我们正在寻找将MuZero应用到现实世界中的方法,并且有一些令人鼓舞的初步结果。
举一个具体的例子,互联网上的流量主要是视频,而一个开放的大问题是如何尽可能有效地压缩这些视频。您可以将其视为强化学习问题,因为有许多非常复杂的程序可以压缩视频,但是你接下来看到的是未知的。
但是当你把像MuZero之类的东西应用于其中时,我们的初步结果显示,在节省大量数据方面它看起来很有希望,可能是压缩视频所用比特的5%左右。
从长远来看,您认为强化学习对哪些方面影响最大?
我认为有一个系统,可以帮助用户尽可能有效地实现目标。一个真正强大的系统,可以看到你看到的所有事物,具有与你相同的感官,能够帮助你实现人生目标。我认为那是非常重要的。
从长远来看,另一个变革性的东西可以提供个性化的医疗保健解决方案。有一些隐私和道德问题需要解决,但是它将具有巨大的变革价值;它将改变医学的面貌和人们的生活质量。
你认为机器在你的有生之年能学会做什么吗?
我不想给它设定一个时间表,但我想说,人类能做到的一切,我最终认为机器都能做到。大脑是一个计算过程,我认为那里没有任何魔法。
我们能达到像人脑一样理解和实现算法有效和强大的地步吗?嗯,我不知道时间表会是怎样。但是我认为这个旅程是令人兴奋的。
我们应该致力于实现这一目标。踏上这段旅程的第一步是试图理解获得智慧意味着什么?解决智力问题,我们在努力解决什么问题?
强化学习能否通向人工智能
你是否有信心可以从象棋和Atari等游戏到真正的智能?是什么让你认为强化学习会产生有常识理解的机器?
有一个假设,我们称其为“奖励足够”假设。这个假设说,智能的基本过程可以像一个寻求最大化其奖励的系统一样简单,而试图实现目标并试图最大化奖励的过程,足以产生我们在自然智能中看到的所有智能属性。
这是一个假设,我们不知道它是否正确,但这为研究提供了方向。
如果我们具体地理解常识,那么“奖励足够”的假设就很好地说明了这一点,如果常识对系统有用,则意味着它实际上应该帮助它更好地实现其目标。
听起来您认为您的专长领域强化学习,在某种意义上是理解或“解决”智力的基础。是这样吗?
我真的认为这非常必要。我认为最大的问题是,这是真的吗?
因为这显然违背了许多人对人工智能的看法,即智能中涉及到非常复杂的机制集合,每个机制都有自己要解决的问题或自己特殊的工作方式,或者甚至没有任何明确的问题定义,比如常识。
这个理论说,不,实际上可能有一个非常清晰和简单的方法来思考所有的智能,那就是它是一个目标优化系统。如果我们找到了真正优化目标的方法,那么所有这些其他的东西将会从这个过程中出现。
强化学习已经存在了数十年,但有一段时间似乎是死胡同。实际上,你的一位导师告诉我,她试图劝阻你不要从事这项工作。你为什么不理她继续往前走?
许多人认为,强化学习是可以用来解决在AI中许多问题的工具之一。我不这样认为,我把强化学习视为整体。如果我们想尝试并尽可能地描述智能,我认为强化学习本质上是我们真正意义上的智能的特征。
当您开始以这种方式看它时,我为何不能这样处理呢?如果这确实是最接近我们所说的智能的东西,那么如果我们解决它,我们就将破解它。
你看看我所做的工作,我将一直致力于解决这个问题。解决诸如围棋之类的问题时,在解决它的过程中,我们了解了智能在此过程中意味着什么。
你可以认为强化学习是一种能力,它使一个智能体能够获得所有需要的其他能力。
你可以在类似AlphaGo的东西中看到一点点,在那里我们要求它做的只是赢得游戏,然而它学到了人类过去曾专有的知识——比赛的结束和开局。
算力是否会限制AI发展
DeepMind是否有压力再做一次大型展示,例如AlphaGo?
这是个好问题。这个问题问得好。我觉得我们处于一个非常有利的位置,因为我们的位置和资金都很安全,所有这些都非常非常安全。
尝试进行一个新的大规模的展示,唯一的压力是推动通用智能的进步。这是一种真正的特权,当你在创业公司试图获得资金时,或者在学术界试图获得资助时,你就没有这种特权。

强大的AI系统现在需要大量的计算机能力才能工作。你是否担心这会阻碍进展?
让我们回到MuZero,这是一个算法的例子,它可以很好地随着计算而伸缩。我们在Atari进行了一项实验,结果表明即使使用非常少量的计算(大约相当于一个GPU运行几周),它的效果也非常好,并且获得了远远超过人类的性能。
有一些数字表明,如果把现在能利用的所有计算能力加起来,就能达到与人脑相当的水平。所以可能更多的是我们需要想出更聪明的算法。
而MuZero的美妙之处在于,它正在建立自己的模型,开始了解世界是如何运转的。这种想象力是利用计算开始展望未来,想象接下来会发生什么的一种方式。
人工智能伦理
一些军火商正在利用强化学习来建造更强的武器系统。你对此有何感想?你有没有想过你的一些作品不应该公开发表?
我反对在任何致命武器中使用AI,并希望我们在禁止致命自动武器方面取得更多进展。DeepMind及其联合创始人是《致命自动武器承诺》的签署方,攻击性技术应始终处于适当的人类控制之下。
然而,我们仍然相信,适当发布我们的方法是科学的基石,通用AI算法的发展将在众多积极应用中带来更大的整体社会效益。
原文链接:
https://www.wired.com/story/what-alphago-teach-how-people-learn/
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
原标题:《AlphaGo之父对话《连线》,曾被导师劝阻研究强化学习,如今获得ACM计算奖》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

