- +1
如何实现算法决策公平?
原创 贾小双 定量群学

引言
随着人工智能的发展,算法决策系统越来越多地被用于辅助甚至是替代人的决策,例如使用算法进行信贷审批、人才招聘、犯罪风险评定等等。由于算法在决策中扮演的角色越来越重要,算法决策的公平性也愈发引起重视。本专题第二期推送为大家介绍了一种将人类意志与算法意志结合起来以提高算法决策公平性的方法,这一期我们将从算法本身出发,为大家介绍Zafar等人在Fairness constraints:Mechanisms for Fair Classification这篇论文中所提出的提高决策公平性的机器学习框架。
01
什么是算法决策的不公平性?
简单而言,算法决策系统的工作原理是使用大量(训练)数据训练出准确率很高的机器学习模型来对目标群体进行分类,从而根据预测结果进行决策。在这一过程中, 若不施加特殊限制,模型常常会将一些敏感特征(sensitive feature,如性别、种族等)纳入分类依据,并赋予较高的权重,从而导致决策结果对某些特定群体(如女性、黑人等)产生不公平的结果,即产生我们常说的“算法歧视”。
机器学习领域将算法决策结果的不公平性分为三种:差别性对待(disparate treatment),差别性影响(disparate impact)和差别性误待(disparate mistreatment)。作者使用了一个犯罪风险评定的例子来说明这三种算法不公平性的含义:
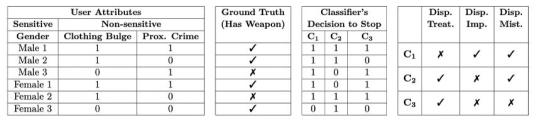
图 1:三种算法决策不公平性示例
如图1所示,C1,C2 ,C3是三种假想的算法,其决策的任务是根据行人的性别、衣服是否有常鼓起和是否接近可能的犯罪地点这三个特征来判断路过的行人是否携带武器,从而决定是否要将其拦下进行搜身。其中,性别是敏感性特征,衣服是否异常鼓起和是否接近犯罪地点为非敏感性特征。下面我们结合这个例子来看三种算法不公平性的含义。
Disparate treatment(DT):差别性对待,也叫直接歧视(direct discrimination),指的是在其他非敏感性特征相似的情况下,决策结果仅在敏感性特征不同的群体间有差异。例如Male1和Famle2的衣服都有鼓包并且都接近犯罪地点,但C2算法决定拦截男性而不拦截女性;同样,算法C3对拥有相同非敏感性特征的Male2和Famle2也做出了不同的决策,因此C2和C3算法都存在差别性对待。
Disparate impact(DI):差别性影响,指的是算法决策所造成的结果总是对某种敏感性特征上取某个值的群体更有利(或更不利)。例如性别这个敏感性特征有男性和女性两种取值,算法C1的决策更不利于男性,因为该算法决定拦截男性进行搜身的概率是100%,而拦截女性的概率只有66%。
Disparate mistreatment(DM):差别性误待,是指算法对某一个敏感性特征上取不同值的群体的预测准确性有差别。在机器学习中,通常用错误率来评估分类模型的准确性。表1展示了几种分类错误率的测量方式。在上述例子中,C1算法对男性和女性是否携带武器的预测的假阴率(false negative rate)分别为为0和0.5;而C2算法对男性和女性是否携带武器的预测的假阳率(false positive rate)分别为0和1,因此C1和C2算法都存在差别性误待。
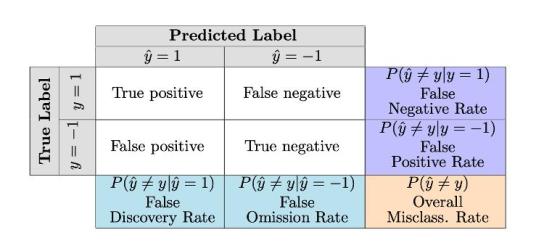
表1:机器学习模型分类错误率的测量
02
什么是公平的决策?
从上面的例子可以看出,在实际应用中,算法决策的本质是在对目标群体进行分类,因此,若要实现算法决策公平,就要使得分类模型能够避免上述三类不公平性的产生。从方法上而言,一个公平的分类模型需要满足[1]:
1 分类结果不存在差别性对待,即分类结果不受敏感性特征的影响,用公式表达为:
2 分类结果不存在差别性影响,即敏感性特征不同的群体有同样的概率被分到某一类,可表达为:
3 分类结果不存在差别性误待,即分类的(五种)错误率不受敏感性特征的影响,按照错误率的计算方式,可以将这一条件进行如下形式化定义:

03
如何实现决策公平
1.基于公平性约束的机器学习分类模型框架
在厘清了算法公平性的概念后,该团队尝试提出一种公平性决策(分类)算法框架,该框架的核心思想是在分类模型的训练过程中加入公平性约束(fairness constraints)。如下图所示,这框架包含两个部分:线性分类器的损失函数(classifier loss function)和公平性约束(fairness constraints)。前者是为了提高模型的预测准确性,后者是为了保证模型的公平性。

2.对公平性测量方式的改进
由于方程(3.2)-(3.7)对公平性的要求非常严格(方程全部使用等号,相当于要求完全不存在任何不公平性),现实情况往往难以满足,因此该团队提出了一种新的决策边界不公平性(decision boundary unfairness)的测量方式,在新的测量方式下:
(1)差别性影响所造成的决策边界不公平性被定义为“用户的敏感特征z”与“用户的特征向量(feature vectors)和决策边界之间的符号距离(singed distance)dθ(x) ”的协方差的均值。
(2)基于不同的分类错误率定义,差别性误待所造成的决策边界不公平性也有不同的测量方式。例如,整体整体错误率(overall misclassification rate)可以转化为“用户的敏感特征z”与“被分错类的用户的特征向量(feature vectors)和决策边界之间的符号距离(singed distance)dθ(x) ”的协方差;假阳性率(false positive rates)可以转化为“用户的敏感特征z”与“被分错类的且真实标签为阴性的用户的特征向量(feature vectors)和决策边界之间的符号距离(singed distance)dθ(x) ”的协方差,其他的错误率以此类推。
注:1差别性对待可以通过在训练时不使用敏感特征来进行避免。
2但可能真实的情况是敏感特征确实与真实的分类具有较高的相关性(例如男性携带武器的比例确实高于女性),在这种情况下,若要避免差别性影响,模型预测的准确性可能会打折扣。在要求保证模型分类准确性的情境下(business necessity clause),该团队也提出了如何对该框架进行调整来适应这种情境的方案。(见原文4.3)
3.如何基于这一框架来设计一个公平的分类模型?
在改进了不公平性的测量方式后,作者使用这一新的决策边界不公平性对(3.2)-(3.7)中公平性约束条件进行了相应的修改(详见方程(4.2)-(4.9)),放宽了(4.1)中公平性的约束。改进后的框架对公平性的约束条件为:当决策边界不公平性小于某个阈值时,便认为模型是公平的。基于这一框架,研究者在设计具体的分类模型时只需(4.1)中的Classifier loss fuction换成相应的分类模型(如logistic regression分类器,线性SVM和非线性SVM模型等)的损失函数,将Fairness constraints部分替换成具体的公平性限制函数(如对差别性影响的限制)来设置模型即可。例如,一个不存在差别性影响的logistic regression分类器可以表达为:

04
方法评估
为评估模型的效果,作者分别使用模拟数据和真实数据来评估这一分类方法在消除分类结果的差别性影响和差别性误待上的表现。
1.差别性影响评估;
(1)logistic regression classifier
如图2所示,作者首先生成了两个数据集,每个数据集各有4000个数据点,每一个点的真实标签(y=1或y=-1)与其敏感性特征(z=0或z=1)存在不同程度(φ)的相关(φ值越小,相关性越大),然后使用这两个数据集来训练基于公平性约束的logistic regression分类模型。
图中的实线表示只关注准确性的模型所训练出的分界线,我们把这一模型看作基准模型,蓝色和黑色虚线分别表示公平性约束的阈值(c)取不同值所训练出的分界线。可以发现,如果仅仅以准确性作为训练目标,模型的分类准确性会非常高(Acc=0.87),但分类结果会存在不同程度的差别性影响,且敏感性特征与真实标签的相关性越高(右图φ=π/8),分类所产生的差别性影响越大(|0.21-0.87|=0.66)。当加入不同程度的公平性限制时,分类模型(图中虚线)所产生的差别性影响变小。
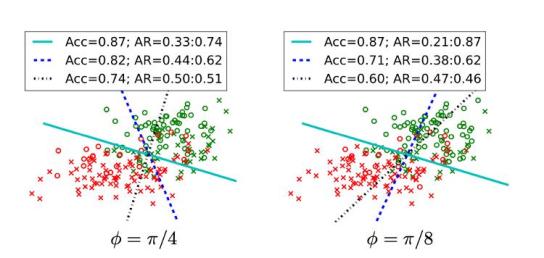
图 2 模型消除差别性影响效果评估(线性分类器)
注:Acc表示准确性(accuracy),图中绿色的点的真实类别y=1,红色的点为y=0. 圆圈表示敏感性特征z=1,十字表示敏感性特征z=0。AR(positive class acceptance rate)表示模型将z=0和z=1的数据点标注为y=1的概率。
(2)非线性SVM模型表现
作者同样生成了两个数据集用于训练非线性SVM分类模型。由图3可看出,在不进行任何公平性约束时(图a),SVM模型的分类准确率(Acc)可达0.94,但和上述线性分类器相似,没有公平性约束的模型也产生了不同程度的差别性影响。当模型完全限制差别性影响,即公平性约束的阈值取c=0时,模型所产生的差别性影响相对较小。
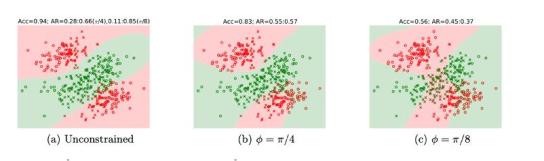
图3 模型消除差别性影响效果评估(非线性分类器)
注:无论对于线性还是非线性分类模型,当加入公平性限制时,模型的预测准确性都会降低。
2.差别性误待评估
作者模拟了两种情境,在第一种情境下,基准模型(训练模型时不施加公平性约束,只关注准确性)的分类的结果只表现为一种类型的差别性误待——模型对不同敏感特征群体分类结果的假阴性率不同或假阳性率不同(即公式3.3和3.4其中的一个不能满足);而在第二种情景下,这两种差别性误待同时存在。
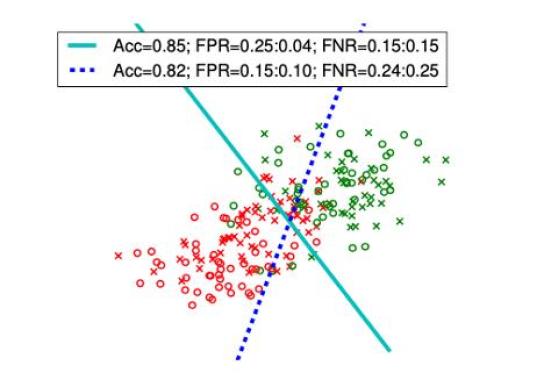
图4 模型消除差别性误待效果评估(情境一)
图4展示了基准模型(图中实线)的分类结果只存在假阳性率不同的情况下,对假阳性率加以约束后训练出的分类器(图中虚线)能够缩小模型对敏感性特征不同的群体分类结果的假阳性率的差异(从0.21降低为0.15),从而减轻分类结果所造成的差别性误待。

图5 模型消除差别性误待效果评估(情境二)
而图5则展示出当情景二中两种差别性误待同时讯在的情况下,在模型的训练过程中分别对假阳性率和假阴性率加以限制,或同时对二者加以限制,都能缩小不同敏感特征人群分类结果的假阴性率和假阳性率的差异,在一定程度上消除分类结果所造成的差别性误待,从而提高分类结果的公平性。
此外,为了评估本文提出的基于公平性约束的分类方法在真实数据上的表现,作者使用两个真实数据集(Adult income dataset和Bank marketing dataset)对模型消除差别性影响和差别性误待的效果进行了评估,并将本文所提出的方法与其他方法进行对比,结果显示,本文提出的分类框架能够较好地制约分类结果的不公平性,且加入公平性约束条件后对模型预测准确率的牺牲也较小。
05
总结
算法决策会导致三种不公平性:差别性对待、差别性影响和差别性误待;因此一个公平的决策模型需要避免决策结果存在这三种不公平性,在这篇论文中,作者对这三种不公平性的测量方式进行了改进,提出了测量决策边界不公平性(decision boundary unfairness)的方法,并在此基础上设计了一个促进公平决策的分类算法框架——将公平性约束加入分类模型的训练过程,在保证公平性的前提下对模型的准确性进行优化。基于这一框架而设计的线性和非线性分类模型在模拟数据和现实数据中的表现均优于现有的方法。
这篇文章的层次非常丰富,既介绍了“算法公平”领域的一般性的概念,又提出了一个具体的公平性算法框架,还对相关的研究进行了较为全面的综述,并对现有的模型进行了对比与总结,使得读者能够窥一斑而见全豹,不同类型的读者都能有所收获。对算法公平感兴趣的读者可以根据表3顺藤摸瓜去阅读更多的研究。
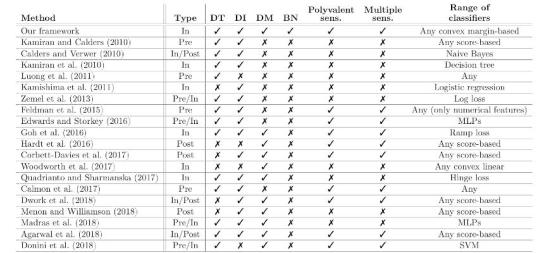
表3 不同公平性分类方法的比较
参考文献
[1]y^为模型预测的分类,y为真实的标签,z为敏感性特征,x为非敏感性特征
[2]Zafar, M. B., Valera, I., Rogriguez, M. G., & Gummadi, K. P. (2017, April). Fairness constraints: Mechanisms for fair classification. In Artificial Intelligence and Statistics (pp. 962-970). PMLR.
推荐人
贾小双,中山大学社会学系在读博士,研究方向为计算社会科学,关注机器学习中的因果推论、数据驱动的社会分层等传统与计算方法相结合的社会学研究。

原标题:《如何实现算法决策公平?》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

