- +1
谷歌搜索的灵魂:BERT模型的崛起与荣耀
原创 子佩 智东西 收录于话题#人工智能20#谷歌1


刷榜各NLP任务、超70种语言搜索,起底搜索帝国谷歌的“引擎工程师”BERT!
作者 | 子佩
编辑 | Panken
如果你在谷歌上搜索“如何在没有马路的山上停车”,谷歌会告诉你什么?
如果是两年前,网页可能会教你怎么停车或怎么在山上停车,因为它检测到了“停车”、“山上”这些关键字,而忽略了那个看似无关紧要的小词“没有”。
但现在,它能在页面最显眼的位置,直接向你提供你最关心的问题:如何在没有车道的山坡上停车。因为它不仅学会找到这些关键词,也学会理解了这些词之间的联系。
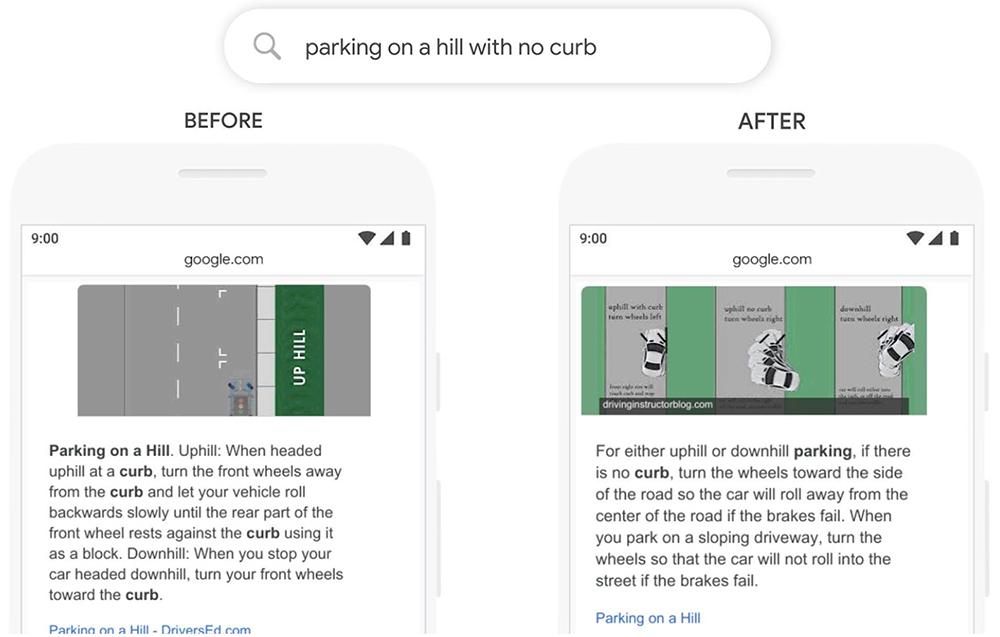
在搜索引擎“猜”透人心背后,是谷歌的BERT模型逐渐开始理解人类语言。
今年10月,谷歌在“Search On”活动中介绍了数千项AI领域的新应用,其中就包括BERT模型的新进展:已应用于谷歌上近乎所有的英文查询,适用范围也拓展至70多种语言,而去年这个时候,BERT在英文查询中的使用比例不超过10%。
使用比例翻十倍、涵盖语言增至70余种……自2018年诞生至今,是哪些硬技术赋予BERT“超人类”的语言理解能力,它在NLP届(自然语言处理,下称NLP)又有怎样的“江湖地位”?
今天,就让智东西和你一起,走过BERT这两年的进阶之路,看看NLP届如今的半壁江山。
本文福利:打开BERT模型的黑箱!推荐精品研报《舆情因子和BERT情感分类模型》,可在公众号聊天栏回复关键词【智东西143】获取。
01.
诞生即崛起,BERT的发家史
BERT最出圈的“荣耀时刻”是2018年:称霸机器理解测试SQuAD,横扫其他10项NLP测试,达成“全面超过人类”成就。
SQuAD是行业公认的机器阅读理解顶级测试,主要考察两个指标:EM和F1。
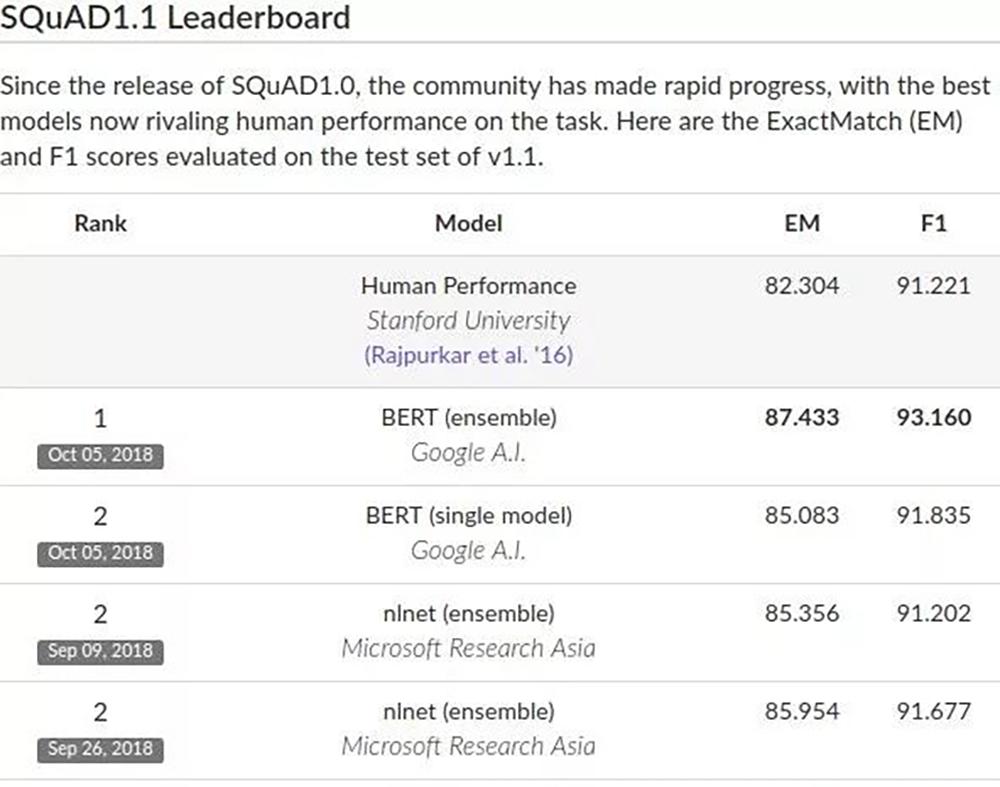
EM指的是模型答案与标准答案的匹配度;F1指的是模型的召回率和精确度。在这两项上,BERT得分分别87.433和93.160,超过人类的82.3和91.2,被不少研究人员认为,是自然语言领域的重大成就,将会改变NLP的研究方式。
BERT为什么这么牛?
那我们得先看看模型是怎样“学语言”的。
模型和人一样,在会说话能阅读之前,它也需要背单词、学语法,只是它不是通过语境去理解词义,而是将单词转化为可以计算的向量或者矩阵,再通过神经网络计算特征权重学会“语法”,从而“理解”人类语言。
BERT诞生于2018年,全名是Bidirectional Encoder Representations from Transformers,从名字上来看,BERT是基于Transformer模型建立的一个双向编码器。
Transformer模型起源于机器翻译领域,抛弃了循环神经网络(RNNs)中循环式网络结构方法,利用注意力机制构建每个词的特征,通过分析词之间的相互影响,得到每个词的特征权重。
这种基于注意力的Transformer模型关注的不单是个别词语,而是词与词之间的关系,比起单纯地提取词向量更“善解人意”。
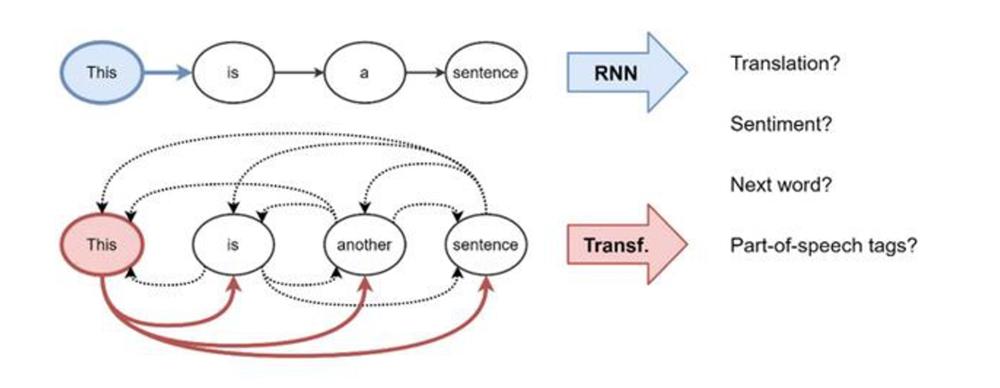
在解决了如何“背单词”的问题后,下面一步就是怎么学语法。
嵌在BERT名字里的双向编码就是它的答案。
如下图,OpenAI的GPT模型使用的是从左到右的Transformer,即通过分析上文得到下一词的特征权重,而不能通过下文验证前文的词义,而AllenNLP的ELMo通过将独立训练的两个方向结果串联,生成下游任务特征。
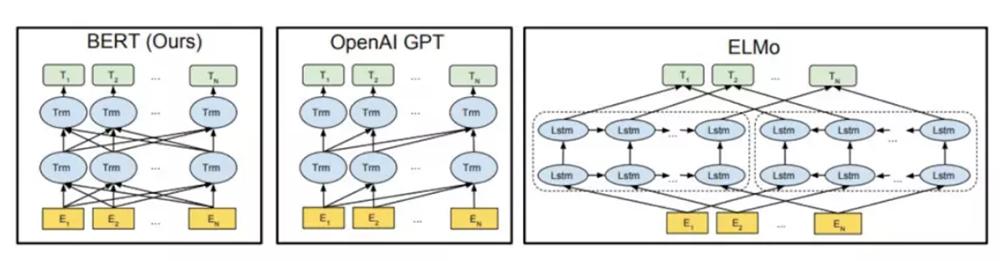
▲BERT与GPT、ELMo的比较
但BERT不仅能同时进行双向预测,还能通过上下文全向预测。
在BERT面世之前,NLP大厦头顶上有两片乌云:标记数据集不足和结果的低准确率。
前者,BERT在无标记数据集中用无监督学习解决;后者,BERT通过加深Transformer层数和双向编码的方法精进。
在出生时就带着横扫各大赛事的“战绩”,两年的实战更历经无数风雨,现如今的BERT不仅在学界具有里程碑意义,在实际应用这片广阔天地中更是大有作为。
02.
两年不止步,BERT的进阶史
要在网页搜索届呼风唤雨,谷歌的真本事当然不止BERT一个,用于搜索引擎优化的Panda、Penguin、Payday,打击垃圾邮件的Pigeon以及名声在外的网页排名算法Pagerank……每一块小模组都各司其职,组成了谷歌搜索的“最强大脑”。

BERT是在一岁时,也就是2019年10月15日,正式加入谷歌搜索的算法大脑,承担在美国境内的10%英文查询中。
“深网络”、“双通路”的BERT不仅能“猜心”,还能识错。
据谷歌统计,在每十次搜索中,就会出现一个拼写错误,如下图用户想搜索dinner,却误输成dibber,但BERT可以绕过这个错误,直接识别出用户意图,提供餐馆位置。
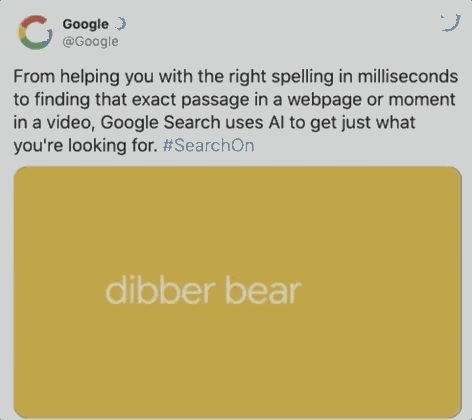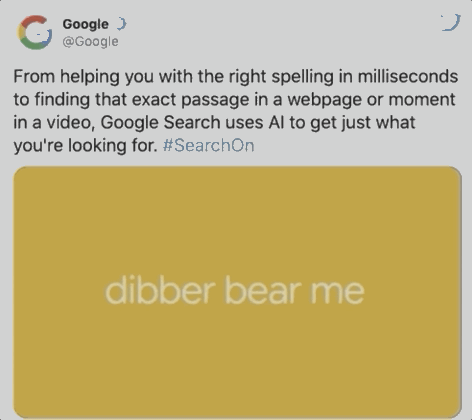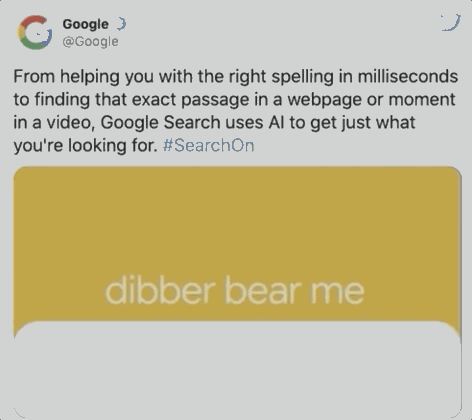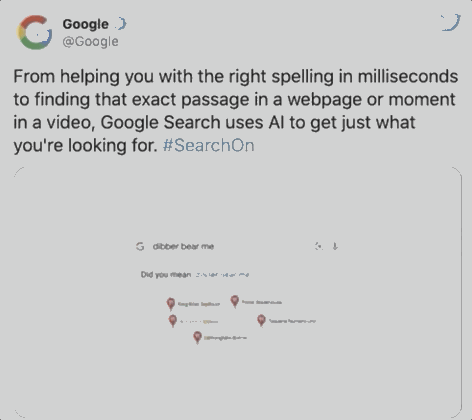
两个月后,BERT开始承担70多种语言的搜索任务。
一年后,BERT在谷歌搜索中使用比例近乎100%,凭借出色的理解能力,替代上一代查询工具RankBrain,成为搜索大脑的王牌。
在这“高分高能”的实绩背后,是BERT模型一直的默默进阶。
2019年12月,通过更加有效地分配模型容量、简化Transformer隐藏层中的参数和冗余度检查,BERT在性能提升的同时减少计算量,升级为更为轻量级ALBERT。
2020年3月,受生成对抗网络(GAN)的启发,BERT改进了预训练方式,减少了模型训练的时间,从而可以在更少的计算量内达到相同的文本识别效果,衍生出了ELECTRA模型。
2020年8月,BERT内引入了多语言嵌入模型,实现不同语言间互译,让用户可以在更大范围内搜索有效信息。
2020年10月,BERT着眼于减少模型本身的“偏见”,利用模型评估指标来调整预训练模型中的参数,减少搜索时可能出现的性别种族歧视。
从10%到100%,带着满分出生的BERT并没有固步自封,而是不断地顺应时代的需求,一次又一次地自我更新,用更少的训练时间、更小的计算量达到更为优越的性能。
今年十月,谷歌公布了BERT在搜索领域的表现,除了扩大应用范围和可应用的语言外,BERT将谷歌在学术检索上的准确率提高了7%。
谷歌也表示,会在未来利用BERT模型继续精进搜索算法,扩大搜索的范围,提高搜索的精度。
03.
BERT开球,百家争鸣
BERT的贡献远不止是提升谷歌搜索性能或者获得“机器超过人类”的名号,而是作为一个泛化性极强的通用模型,为今后NLP届开辟了一条光明的研究赛道。
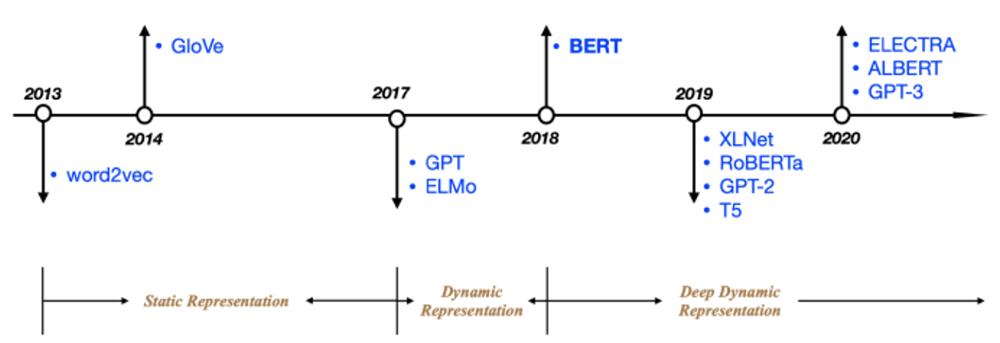
▲图源网络
以BERT为分界线,NLP领域可以分为动态表征模型(Dynamic Representation)时代和深度动态表征模型(Deep Dynamic Representation)时代,在前一个时代,标注数据集的不足和单向编码器限制了模型的可拓展性;而在后一个时代,基于BERT发展出来的方法,“支棱”起了NLP届半壁江山。
改进BERT的方法千千万,其中大概可以分为两个方向:一是纵向,通过改进Transformer层的结构或者调整参数,得到更加轻量级的模型,例如之前提及过的ALBERT模型;二是纵向,通过在BERT模型中延伸其他算法模型,拓展BERT模型的功能,如受GAN影响诞生的ELECTRA模型。
在BERT逐渐发挥影响力、实现应用落地的同时,NLP届的新秀也轮番亮相。
2019年出现的XLNet和2020年出现的GPT-3就是杀出重围的两员大将。
XLNet,在BERT的基础上,加入了自回归的预训练方法,得到一个既擅长语义理解也擅长语义生成的模型,补齐了BERT模型在长文阅读、以及文字生成方面的短板。
而GPT-3更是来势汹汹,作为OpenAI旗下第三代深度语言学习模型,它自带1705亿个参数,是前一代模型GPT-2的100倍,经过5000亿个单词的预训练,在无微调的情况下,取得多个NLP基准测试上的最高分数。
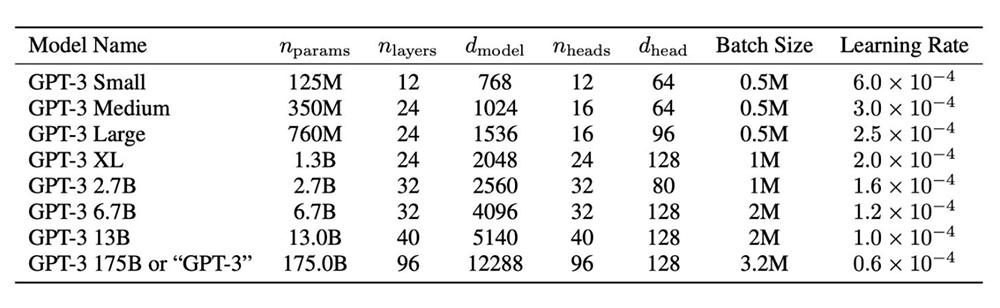
与此同时,GPT-3也解决了BERT模型存在的两个问题:对标注数据的依赖,以及对训练数据集的过拟合,旨在成为更通用的NLP模型。
基于更大的数据集和更多的参数,GPT-3不仅能搜索网页,还能答题、聊天、写小说、写曲谱,甚至还能自动编程。
在目前的调试阶段,GPT-3也暴露出了包括仇恨言论、错误信息等许多问题,所以纵使顶着NLP界最强后浪的名号,它目前暂时还无法像前辈BERT一样,落地应用,为人类带来价值。
04.
结语:NLP新时代,BERT不缺席
自然语言处理(NLP)领域有很多细分方向:文本分类、机器翻译、阅读理解、机器人聊天……每一个子题都对应着人工智能在现实生活中的实际应用:网页检索、自动推荐、智能客服……
如何让人工智能真正走入我们的生活,第一个要解决的问题就是如何让机器真正地理解我们想要什么。
BERT让我们迈出了一大步,基于自监督学习处理无标记数据,再通过双向编码理解文义,BERT打破了之前训练数据需要标记的“魔咒”,充分利用了大量无标记文本,是NLP届里程碑式的革新。
从诞生、进阶到衍生出一系列语言模型,已经两岁的BERT用时间证明了自己的巨大潜力,或许在未来,它将融合进新的应用,为我们带来意想不到的AI革命。
参考资料:谷歌AI blog、Rock Content、searchengineland
本文福利:打开BERT模型的黑箱!推荐精品研报《舆情因子和BERT情感分类模型》,可在公众号聊天栏回复关键词【智东西143】获取。
(本文系网易新闻•网易号特色内容激励计划签约账号【智东西】原创内容,未经账号授权,禁止随意转载。)
原标题:《谷歌搜索的灵魂!BERT模型的崛起与荣耀》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

