- +1
算法治理的参与框架
原创 张咏雪 定量群学

算法越来越多地代替人们进行决策,管理着信息、劳动力和各种资源的分配,协调着各方利益。但是算法治理可能损害社会公平,因为算法可能会优先考虑部分人的利益,而牺牲其他人的利益。当权威嵌入到技术本身而不是传统的治理形式中,治理算法就变成了引导、挑拨、控制、操纵和约束人类行为的算法。这些问题都不能通过纯技术方法来解决;算法的设计需要一个规范来引导。
一个理想化的算法,需要具备这些特点:1、理解公众的道德期望;2、符合各种公平的概念3、满足利益相关者的需要和要求。利益相关者参与决策是解决这个问题的最佳办法。它的优点包括:1、增强决策的合法性;2、增加信任和满意度,从而增强人们的需求;3、提高效率;4、有助于实现道德价值及其相关权衡,如公平和效率。于是这篇文章运用传统的参与性决策框架来解决算法的问题。
一、在算法中嵌入社会道德价值的困难
首先,已有的研究试图通过计算方式的设计,将道德和社会价值编码进算法之中,但这依赖人类的定义方法和算法的目标函数。
其次,社会价值的多元性使得目标无法在同一程度上得到满足,这需要做出权衡决策。例如,不能同时保证所有的公平原则都被体现;难以兼顾效率和公平。
最后,社会和道德价值取决于情境。不同的社会群体相信不同的公平原则,人们希望可以在不同的情境中按照不同的公平原则进行运作,公平原则必须根据具体情况而定。
二、参与式治理框架的合理性
参与式治理框架建立在社会选择理论之上。社会选择理论将人们的意见、效用和福利等方面进行量化定义,然后根据关键的特征将他们集合化,由此达成一个共识。投票是最常见的聚合方法之一,这种方法能选择出支持度最高的选项,同时将偏见最小化。
三、框架的建立
该框架的关键思想是建立一个代表每个利益相关者的计算模型,并让这些模型代表他们的创造者进行投票。这就像一群人一起做决定:每个人决策过程的计算模型为每个决策做出集体选择。
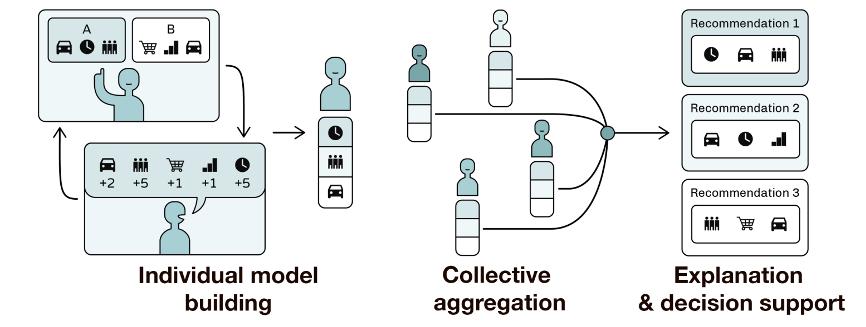
图1 WeBuildAI框架的展示
图1框架的解释,依次由左到右:
1.建立个人决策模型;
2.进行模型的集体聚合;
3.解释和进行决策。
WeBuildAI框架让利益相关者参与到算法设计的过程中,个人创建的计算模型体现了他们对算法政策的看法,并代表个人进行投票。
四、具体应用:捐赠分配匹配算法
“412食物救援”是一个非营利性组织,其连接食品供应方、零售商店、志愿者与一些需要食物救援的人。该研究与“412食物救援”组织合作,通过WeBuildAI框架对各方进行匹配,一旦做出了匹配的决定,该组织就会在他们的应用程序上发布救援信息,这样志愿者就可以注册,把捐赠物送到接受捐赠的组织。每一次救援服务的成功取决于所有利益相关者的参与——源源不断的捐赠、受赠组织接受捐赠的意愿、志愿者运送捐赠的努力,以及412食品救援行动的支持和监督。目前的服务量太大,人工的决策效率已经无法满足需求。
1、个人模型的构建
(1)特征选择。
通过访谈或调查来征求意见,确定算法中应该使用的特征集。所选的因素包括运输效率、受援者的需求和时间分配模式(表2)等。例如,贫困率是受助者需求的指标;受助者和捐赠者之间的距离是效率的衡量标准;每个受赠人最后一次收到捐款的时间是衡量一段时间内分配模式的指标。
表2 各种影响决策的因素

(2)建立模型。
此研究使用机器学习和显式规则模型两种方式。
A、机器学习模型。
为了训练一种能反映人们决策标准的算法,机器学习方法在前一步得到的特征集(表2),然后根据因素随机生成两个潜在受助者,并让人们选择哪个应该收到捐赠(图2a)。
利用随机效用模型,每个参与者对每个对象都有一个真实的效用分布,当被要求比较两个对象时,从每个分布中抽取一个值。对每个参与者i,学习一个单一的向量βi,这样每个潜在决策x的效用为µi(x) = βiT x。然后,通过标准梯度下降技术使用Normal Loss学习与βi有关的向量。
B、显式规则模型。
在这个方法中,参与者直接指定他们的原则和决策标准,会使用表2中所示的相同因素创建一个评分模型,要求参与者创建规则来给潜在的接受者打分,这样得分最高的接受者将被推荐。参与者给不同的特征赋值(图2b)。
如果进行了显式规则模型建模之后,他们的想法改变了,又会回到两两比较的机器学习训练中。然后对比新旧两个模型(如图3),选出更能体现自己观点的那个模型。有13名参与者在第二阶段之后选择回答另外50-100个问题来重新训练他们的机器学习模型。
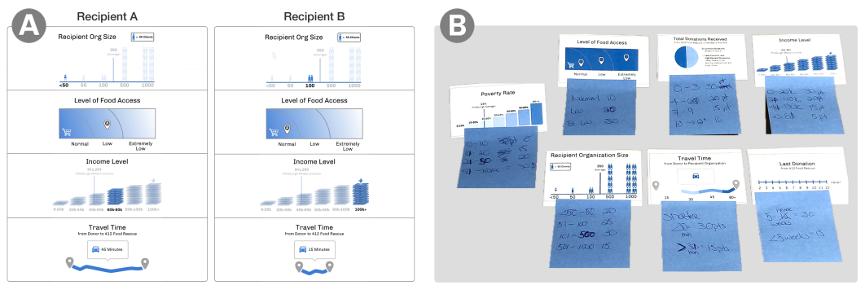
图2 机器学习模型与显式规则模型
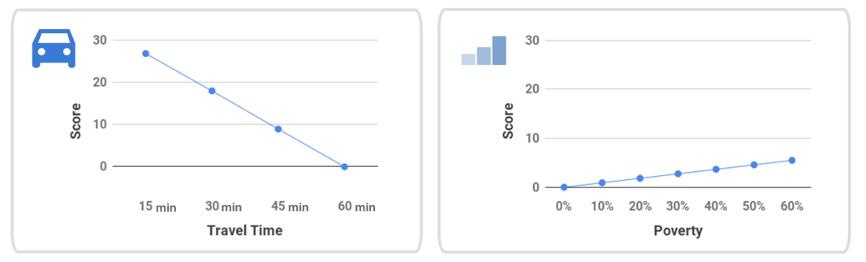
图3 模型结果中各因素与得分的关系可视化
(3)模型选择。
将两种模型进行可视化,以便参与者能够理解每个模型并且选择出最能代表他们想法的模型。在半结构化访谈中,询问他们的经验和选择最终模型的原因。研究者还分析了每个个体模型分配给每个因素的beta值(每个模型的标准化参数),或分配给每个因素的最高分数。由于所有的特征输入都被归一化了(从0到1),使用beta值的强度来对各因素在每个个体模型中的重要性进行排序。
15名参与者完成了所有的过程,并被要求选择更能代表他们想法的模型,其中10人选择了基于他们的两两对比训练的机器学习模型;其他人选择了他们明确指定的模型。机器学习模型比显式规则模型更能体现参与者的想法。
2、集体聚合
这个研究使用了Borda投票方法,因为它相对简单,并且在面对真实偏好的噪声估计时具有强大的理论保证。
Borda规则如下:
给定一组投票者和一组m的潜在分配,其中每个投票者都给出一个各种分配方式的排名,排在位置k的分配方式,得分为m-k。每种分配方式的博尔达分数是所有的得分总和。
当各个利益相关者创立了个体模型,这些模型被嵌入到AI系统中来代表他们。每个单独的模型对所有备选方案进行排序,再使用Borda规则聚合生成一个最终的排序列表。
3、算法决策与人类决策的比较
将算法决策的结果与人类决策进行比较。412食品救援的历史分配数据跨度为5个月(2018年3月-8月),169名捐赠者提供的共计1760份捐赠。在这个数据库中运行算法后,有380个符合条件的受赠者组织,其中277个在我们考虑的时间范围内接受了捐赠。将算法(AA)的结果与记录在历史数据中的人工分配记过(HA)进行比较(如图5所示,RA为随机匹配结果)。
结果表明,算法可以在不损害效率的情况下使捐赠分配更公平(图5)。Mann-Whitney U test显示,与人类决策相比(Median = 18.3%, SD = 13.73%),算法决策将食物分配给了贫困机率更大的地区(Median =21.6%, SD = 14.44% ,U =1303400, p < .00000001)。同时算法决策结果中捐赠方和受赠方的距离也显著比人类决策结果的要短 (U = 1646900, p = 0.001)。
所有参与者都认为在最终算法中给予不同利益相关者的权重应该取决于他们的角色。平均而言,参与者将46%的票投给412食品救援组织,24%分配给受援组织,19%分配给志愿者,11%分配给捐赠者。为了将这些权重转化为Borda聚合,研究者给每个利益相关者组分配了与其权重相称的总票数,并在每个组内将选票平均分配。
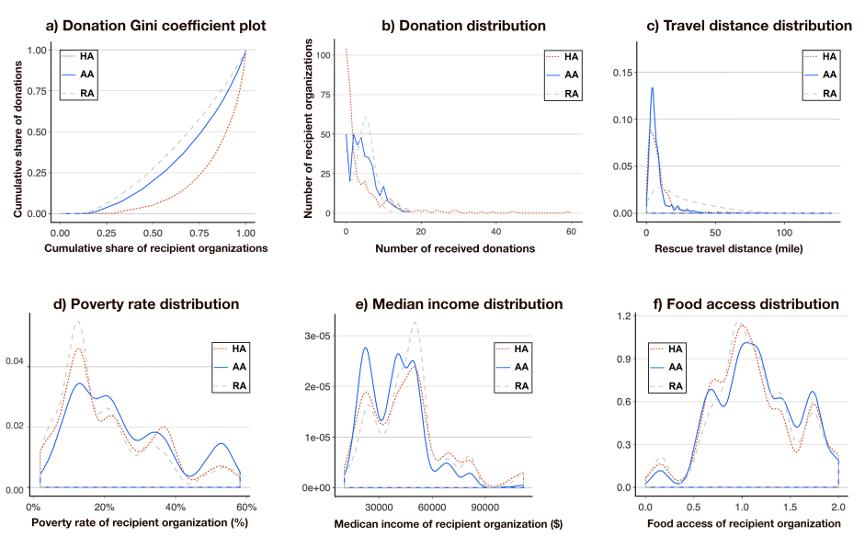
图5
推荐理由
算法决策的过程往往被形容为一个黑箱,而其通过数学公式和专业化术语的包装将一些潜在的人类偏见和权威偏向包含其中。除了作为设计者的算法工程师,算法决策的内部过程,看似是其他人类意志所无法企及的地方。然而这篇文章通过一个巧妙的设计和真实的案例应用,将人类意志与算法意志结合起来,让算法在保证效率的同时提高其公平性。在算法治理决策的设计中体现社会道德价值,一直是算法社会学研究同仁的美好愿景。我想这是一个很好的参考,可以通过更好地设计来实现科技向善,而这里面也有社会科学家可以努力的空间。
推荐人

张咏雪,中山大学社会学与人类学学院社会学系在读博士。研究方向:算法社会学,人因工程与社会互动。
参考文献
Lee, M. K., Kusbit, D., Kahng, A., Kim, J. T., Yuan, X., Chan, A., ... & Procaccia, A. D. (2019). WeBuildAI: Participatory framework for algorithmic governance. Proceedings of the ACM on Human-Computer Interaction, 3(CSCW), 1-35.
原标题:《算法治理的参与框架》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

