- +1
收购Arm,推出80G超级A100:2020年,英伟达还有一招没出
原创 Synced 机器之心
机器之心原创
作者:泽南
400 亿美元收购 Arm,把业界顶级显卡性能一次提升 20 倍,市值超越英特尔成为第一大芯片公司……2020 年的科技界大新闻,英伟达一家就占了好几条。
说起英伟达,很多人都知道这家公司最新推出的消费级显卡 RTX 3080,以及它一卡难求的火爆景象。实际上,由于 GPU 在高性能计算、AI 等领域的大规模应用,英伟达出品已经成为了很多工作中不可或缺的一部分。
英伟达快速发展的技术,为人们带来了近乎无穷的算力,也让其自身业绩节节攀升。在过去 20 个季度中,英伟达已有 18 个季度的财务业绩超过了华尔街分析师们的预期。
当然不断的成功并没有让英伟达放缓推出新卡的步伐。

就在自家消费级 GPU RTX 3080 显卡抢占「最强 AI 计算芯片」的名头后不久,11 月份英伟达又为旗下的最强 AI 训练计算卡 A100 系列进行了升级。
回想今年五月份,英伟达在 GTC 大会上发布了 7nm 安培架构(NVIDIA Ampere)的 A100 GPU 产品,其中 40GB,带宽为 1.6TB/s 的 HBM2 显存令人印象深刻。11 月 16 日,竞争对手 AMD 带来了 7nm CDNA 架构的 MI100 加速卡,英伟达继续出招,推出了 A100 80GB GPU,显存翻倍,性能大幅提升。

A100 搭载了英伟达特有的第三代 Tensor Core 人工智能计算单元,对稀疏张量运算进行了特别加速,执行速度提高了一倍,也支持 FP64、 TF32、FP16、BFLOAT16、INT8 和 INT4 等精度的加速。通过全新的 TF32,A100 将上一代 Volta 架构的 AI 吞吐量提高多达 20 倍。
新款 A100 计算卡的主要升级之处在于 HBM2 显存:从之前的 40GB 直接翻倍达到 80GB,显存类型升级为更先进的 HBM2e。同时显存频率从之前的 2.4Gbps 提升到 3.2Gbps,带宽也从 1.6TB/s 提升到史无前例的 2TB/s。通过配合英伟达多实例 GPU(MIG)技术,每个实例在训练时获得的内存可以增加一倍,单卡最多可提供七个 MIG(每个 10 GB)。
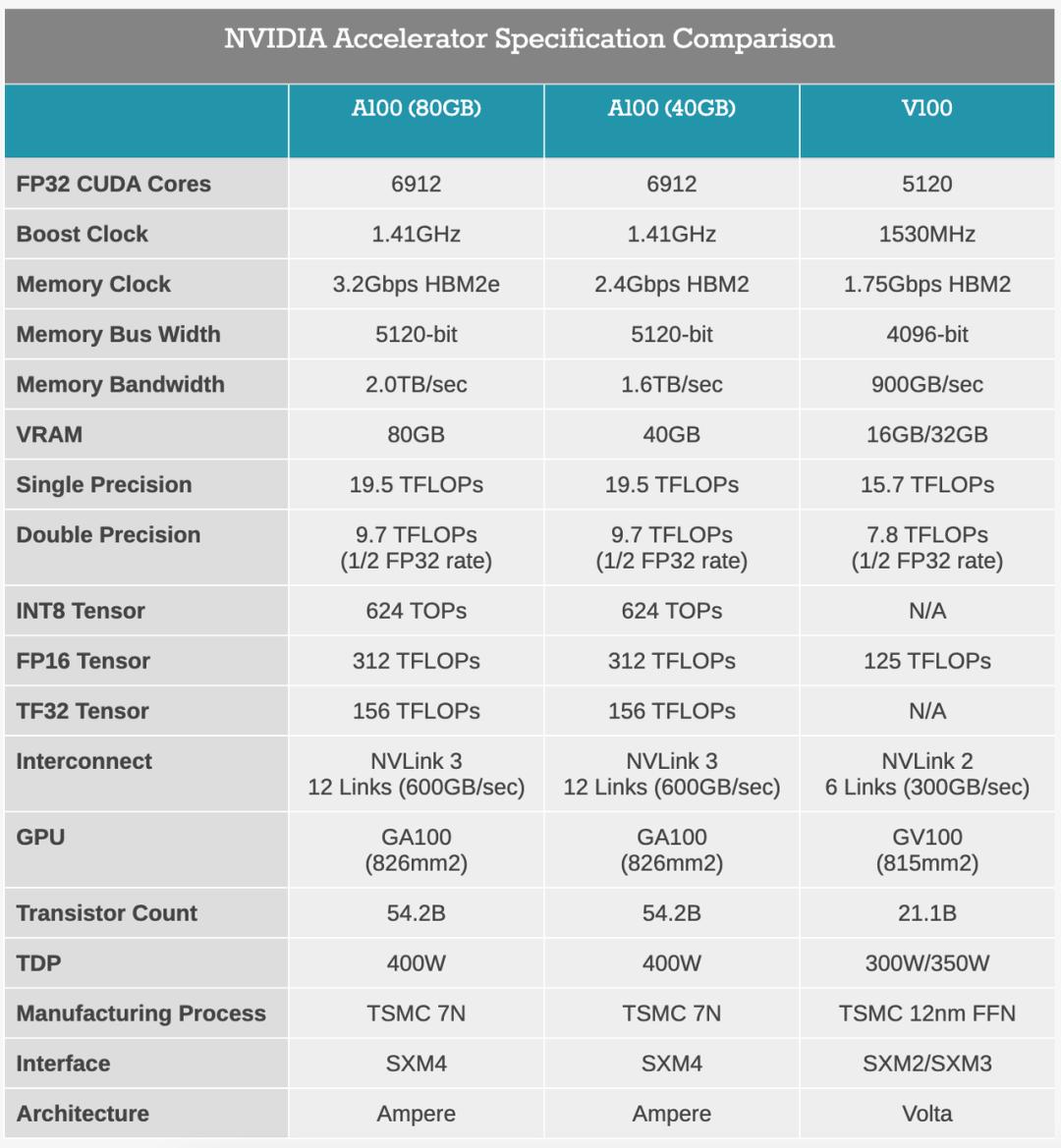
在 A100 上应用的技术还包括第三代 NVLink 和 NVSwitch 功能,相比上代,它们提供了两倍的 GPU 到 GPU 带宽,并将数据密集型工作负载到 GPU 的数据传输加速到每秒 600 GB。
通过硬件与软件的优化提升,A100 80G 可以在大型仿真系统中提供相比六个月前刚刚发布的 A100「标准版」1.8 倍性能的提升。在材料模拟软件 Quantum Espresso 上,单节点 A100 80GB 也实现了近 2 倍的吞吐量提升。
这使得数据可以快速传输到全球最快的数据中心 GPU A100 上,使研究人员能够更快地加速其应用,处理最大规模的模型和数据集,如类似 GPT-3 这样的大规模预训练模型,很大程度上避免了对于数据或模型并行架构的需求。
在深度学习等很多领域中,研究人员对于 AI 算力的需求几乎是无止境的,据英伟达在今年 5 月的统计,自 2017 年底发布 V100 之后,训练业界机器学习模型的算力需求增长了 3000 倍。在五月底 Open AI 的 GPT-3 推出以后,这一数字再次被抬高了不少。

这种思想获得了很多人的赞同,也引来了争议。虽然一直有人认为,找到与人类思考方式类似的因果推理范式才能真正地通往强人工智能,但基于深度学习的方法在近年来已掌握了国际象棋、围棋,实现了不少人类专家也难以企及的能力。除了前沿探索之外,更多的深度学习应用正在路上。
与此同时,英伟达还发布了「全球唯一」的千万亿次级工作组服务器 NVIDIA DGX Station A100,其配备四块新款 A100 GPU,具有高达 320GB 的 GPU 内存,输出算力 2.5 petaflops。在执行 BERT 等大模型时,新一代设备的效率相比过去提高了三倍。
虽然有超算级别的能力,但 DGX Station A100 无需配备数据中心级电源或散热系统,而且年底即开始供货。搭载 A100 80GB 的第三方成套系统则预计会在 2021 年上半年出货。

GPU 在高性能计算领域能有如今的覆盖率,显然是因为有很大需求:在 SC2020 大会上,有超算界诺贝尔奖美称的「戈登 · 贝尔奖」颁给了由 UC Berkeley、北京大学、普林斯顿大学组成的研究团队,他们的研究被认为是当今计算科学中最令人兴奋领域的重大进展。
研究团队引入基于机器学习的分子动力学方法模拟原子运动,每天能够模拟 1 亿原子超过 1 纳秒的轨迹。该研究是在美国橡树岭国家实验室的前世界第一超算 Summit 两万八千块英伟达 V100 上完成的。

将人工智能算法引入到 HPC 领域,并将边界拓展至数据中心之外,是高性能计算领域里正在进行的一项重大变革。而在这个过程中,英伟达将会继续扮演举足轻重的角色。
今年 5 月份的 GTC 2020 大会上,黄仁勋发布了 7nm 安培架构和 A100;9 月份的 GTC 大会上,又为我们揭晓了「PC 游戏领域自 1999 年以来最大突破」——RTX 30 系列显卡。
这还没有完,在今年 12 月,GTC 大会还有一站。
12 月 15-19 日,英伟达行业盛会 GTC 中国站将在线上开幕,大会期间,所有注册参会者可通过登陆,定制个人参会日程、设置参会提醒、查看积分并兑换,换取电商购物券、拉杆箱、NVIDIA Jetson Nano 等好礼。观看主题演讲还将有机会赢得 GeForce RTX 3070 显卡!所有福利仅限注册用户!即刻扫描海报二维码,免费注册,赢取大奖!
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《收购Arm,推出80G超级A100:2020年,英伟达还有一招没出》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

