- +1
告别视频通话“渣画质”,英伟达新算法最高压缩90%流量
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
为了让网速慢的用户用上高清通话,英伟达可谓绞尽脑汁。他们开发的新AI算法,可以将视频通话的流量最高压缩90%以上。


H.264视频所需的带宽是这种新算法的2~12倍,从前面的演示也能看出,如果让二者使用相同比特率,那么H.264视频几乎不可用。

英伟达提供了一个试用Demo,可以在Pitch(俯仰角)、Yaw(偏航角)、Roll(翻滚角)三个方向上任意旋转。
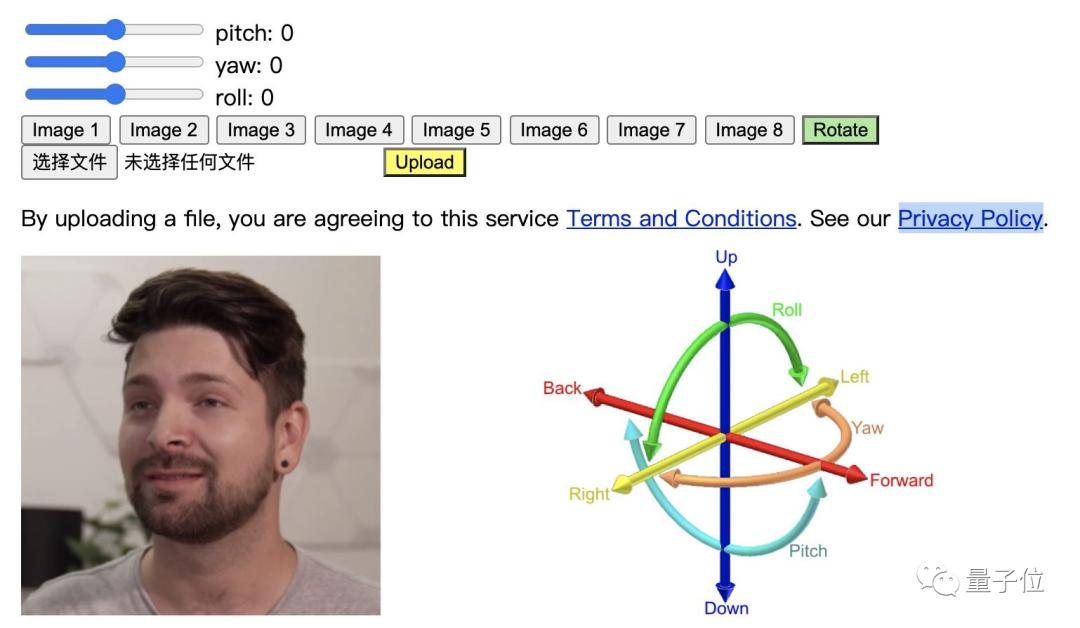


合成面部视频
我们把上传的清晰照片作为源图像,从中获取外貌特征。然后把视频中一帧帧画面作为重构视频的依据,从中提取出面部表情和头部姿势等信息。
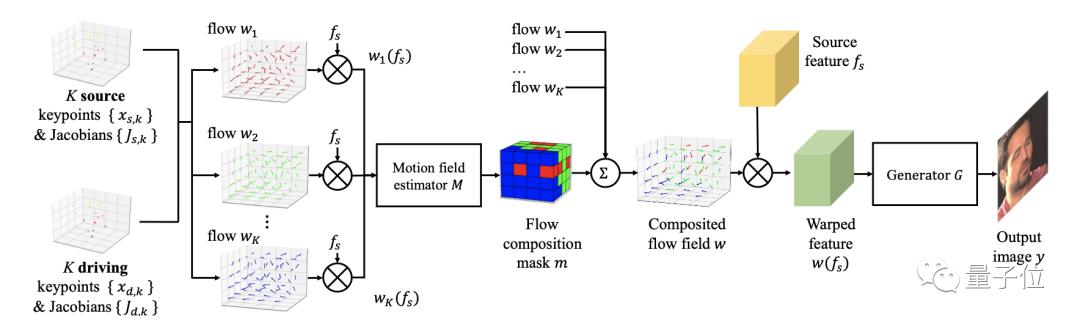
而表情和姿势这两个数据可以通过关键点进行编码,这样就分离了人物身份信息和运动信息。在传输视频时只要有运动信息即可,从而节约了流量。
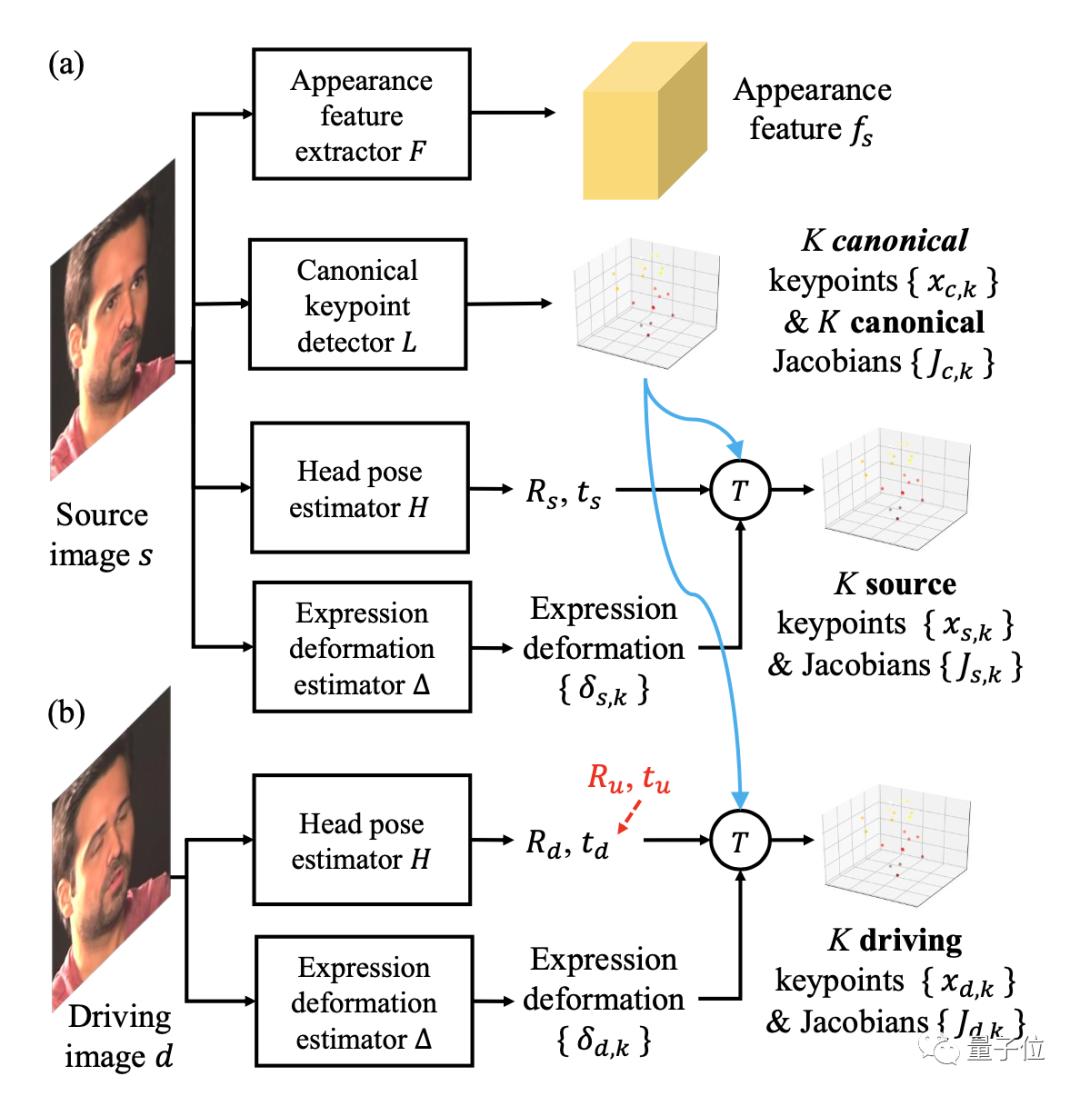
其中,雅可比矩阵表示如何通过仿射变换将关键点周围的局部补丁转换为另一幅图像中的补丁。如果是恒等雅可比矩阵,则补丁将直接复制并粘贴到新位置。
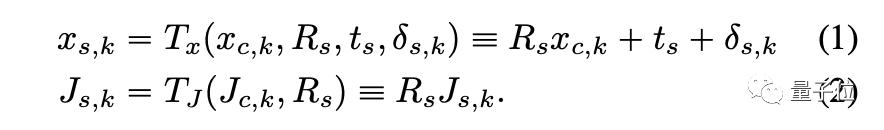
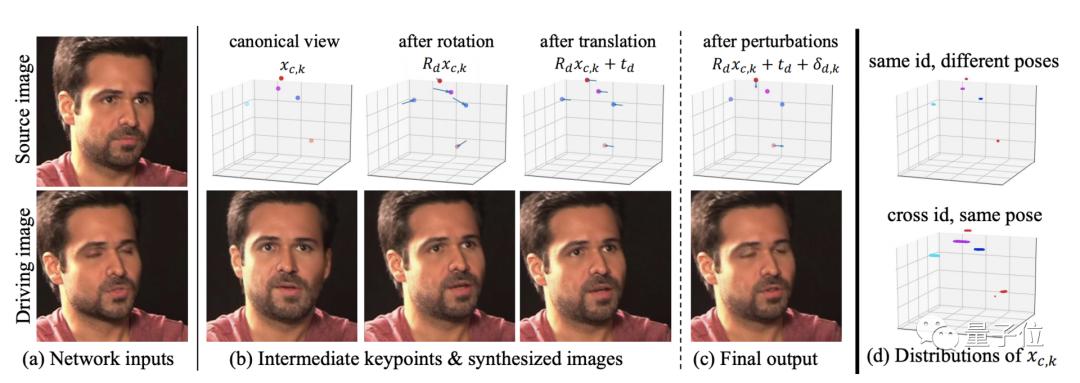
接下来开始合成视频。使用源和运动的关键点与其雅可比矩阵来估计流wk,从生成流组合成掩码m,将这两组进行线性组合即可产生合成流场w。
这种方法不仅能用于视频通话,也有其他“新玩法”。
比如觉得人物头像有点歪,可以手动输入纠正后的数据,从而将面部转正。


这篇文章的第一作者是来自英伟达的高级研究员Ting-Chun Wang。



两人之前已经有过多次合作。比如。无监督图像迁移网络(NIPS 2017),还有从涂鸦生成照片的GauGAN(CVPR 2019),都是出自这二位之手。
项目页面:
https://nvlabs.github.io/face-vid2vid/
论文地址:
https://arxiv.org/abs/2011.15126
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
原标题:《告别视频通话“渣画质”,英伟达新算法最高压缩90%流量》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

