- +1
数据科学很性感?不,其实它非常枯燥

来源:medium
编译:睡不着的iris
很多人把数据科学(或者机器学习)工作描绘的令人向往,激励自己和别人加入其行列。大家把数据科学想得非常完美,事实上它容易让人感到“枯燥”。一旦感到枯燥,你就容易焦虑。如此,导致数据科学工作的离职率非常高。
本文作者将告诉大家自己如何应对“数据科学中那些枯燥的工作”。
希望能够对你有所帮助,让你对数据科学有一个正确的认识,让你在决定走上数据科学的征途时,好好享受这场漫长的游戏!
第一课
我的表弟Shawn是个年轻英俊的小伙,最近他来了加拿大攻读计算机硕士学位。和很多学生一样,Shawn对机器学习充满热情。他希望过2年毕业的时候,可以成为一名数据科学家,或从事其他与机器学习有关的工作。

即便这些话会让Shawn感到失望,我还是有义务把事实告诉他。希望他对自己选择的职业道路有充分的了解。更重要的是,我不希望凌晨3点会接到我妈和叔叔的电话,告诉我作为家庭一员,有义务花耐心去好好指导晚辈。
Shawn十分聪明、积极进取且富有好奇心,他让我详细地给他说说,数据科学到底多枯燥。因此,我写了这篇帖子。
一些背景说明
首先,为了便于理解本文,我先介绍下自己是怎么进入数据科学行业(具体可以看我的领英)。作为一名数据科学经理,我不仅负责领导团队为财富100企业部署机器学习系统,还要管理客户关系,自己也会承担一部分的技术工作。
更重要的概率是:机器学习系统应是用于解决特定业务领域问题的一整套方案,除去机器学习组件,还要处理其他与人或系统相关事情。
部署系统意味着解决方案对实际业务运营有效。举例来说,搭建实验环境用于训练和验证机器学习模型称不上是部署,但如果搭建一个每月邮件发送产品服务的推荐引擎可以算是部署。相比较构建一个好的机器学习模型,部署机器学习系统需要攻克更多的难题。若是感兴趣,可以点击此处详细了解。
所以,我不会介绍如何在谷歌或其他高科技公司,从一名初级开发人员成长为技术经理。虽然这些公司在机器学习颇有成就,但他们只能代表“前1%”的公司。因为其他财富100企业在技术成熟度、技术采用的速度以及投资工具和工程人才储备方面都相对滞后。
AI学术让我们仔细看看
不少年轻数据科学家花费很多时间思考如何构建完美的机器学习模型,或者采用丰富多彩的视化手段向大家展示具有突破性的商业洞察。当然,这些确实算一部分工作。
然而,随着数据科学被广泛使用,企业更关注其实际的应用价值。企业想要部署越来越多的机器学习系统,但他们不关注系统使用了多少新的模型或者酷炫的仪表板。因此,数据科学家需要处理一堆与机器学习无关的工作,从此工作就变得枯燥起来。
数据科学有多枯燥?看看我周一到周五做点什么就知道了。接下来,我把日常工作进行分类阐述,从期望和现实两方面对比说明,并分享我的应对策略。
下面列举的案例都源自过往实验和团队项目,我将以“我们”的口吻来叙述。虽然这些案例可能并不详尽,但也足以论证我的观点。
设计(占5-10%时间)
在设计阶段,我们发挥各自最“高”智慧来解决问题和提出卓越的想法。这些想法可以包括新的模型体系结构、数据特性和系统设计等。但很快,我们就陷入低谷,受时间因素或受其他重要事情影响,我们只能采用最简单(通常也是最无聊)的解决方案。
期望:
我们的想法将被收录于著名的机器学习杂志,如NIPS、谷歌AI项目(Google AI Research)等,还幻想赢得下一届诺贝尔奖。
现实:
部署后一切正常运行。不错的白板绘图会拍照记录下来,作为参考框架。
应对策略:
1)不断与外行朋友谈论我们疯狂的想法,他们会十分诚实(甚至是粗鲁)地劝我打消那些疯狂、愚蠢的念头;
2)把看似疯狂的好想法作为附带项目;
3)结果发现,大部分疯狂的想法不起作用,或者只是比简单方法稍微好一点点。
所以,遵循简单原则(KISS,Keep-It-Simple-Stupid),让我如释重负。
编程(占20-70%时间,取决于你的开发角色)
此处不必多讲,想象你戴上耳机,喝一个口咖啡,拉伸你的手指,坐在在电脑屏幕前,敲打出一行行漂亮的代码后,坐等奇迹发生。
我们的代码分为5部分(此处用代码行数占比说明):数据管道(50-70%),系统和集成(10-20%),机器学习模型(5-10%),调试和演示支持(5-10%)。其他同行基本也是这么认为的,这里有一幅大图可以说明此:
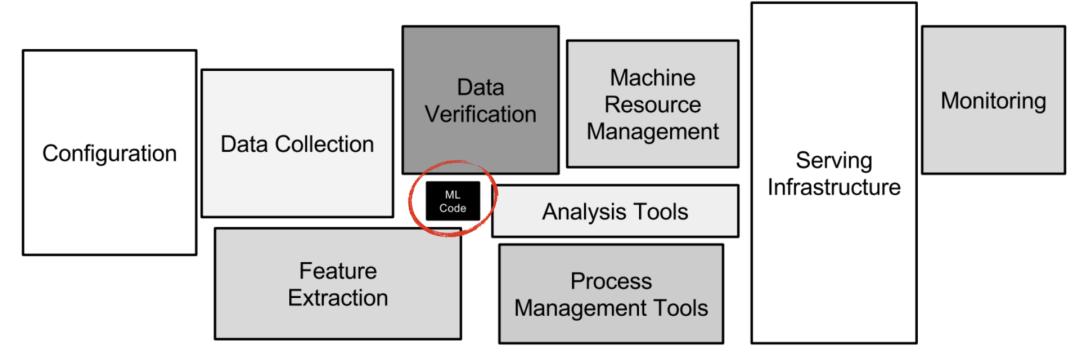
如你所见,我们大部分时间在处理与机器学习无关的事务。虽然机器学习组件非常重要,流行框架和编程语言(如Keras、XGBoost、Python的sklearn等)已经帮助我们减轻了许多繁杂的工作。为了达到目的,我们不需要很重的代码库,工作流已经是标准化和相对完善。虽说做底层优化不同,但其影响也就1%。
期望:
大部分时间我们在开发和重塑机器学习组件,其他人关注剩余部分。
现实:
没人愿意
1)做自己不想做的事情;
2)把所有事都留给自己做;
还有3)花费大量不成比例的时间去优化已经足够完善的工作流程。
应对策略:
我们依据各自的专业特长做设计决策,除了完成自己的开发工作,同时还会支持其他人。(例如,贡献想法、亲手写代码或者做质量评估)。我们互相学习,从而提升团队水平。更重要的是,如此可以缓解这份“性感工作”所带来的焦虑。
质量评估、调试和修复问题(起码占65%时间)
在我看来,这所有技术工作里最没劲、最痛苦的部分。部署机器学习系统也不例外。
一个机器学习系统有2类常见的bug:不好的结果和常见软件问题。不好的结果可能是模型得分太低(例如:准确性和精准度)或难以解释的预测结果(例如:基于业务经验的预测概率呈现偏态分布)。代码没有问题,只是结果不具有解释性或者不够好。常见软件问题则是诸如代码无法运行,系统配置等。
期望:
我们用更聪明的方法构建一个优化的模型就可以解决结果不佳的问题。这个过程需要一些智慧,如果想法可以凑效,那还是非常令人欣慰的。
现实:
在质量评估、调试和处理缺陷的过程中,我们有近70-90%时间在处理常见软件问题。通常,我们构建端到端的训练和验证管道后,可以很快得到好结果。然而,实际我们更关注系统问题,模型则次之。
应对策略:
我用GitHub的issue功能建立了一个游戏化的“奖杯板”。每次关闭问题卡片的时候,我都非常兴奋。看到我们“征服”的问题,我会感到十分骄傲。当然,如果我点击“启动”一切都能够奇迹般的正常运行,我会更加骄傲。虽然这一幕只在大学提交编程作业的时候出现过。我一生都记得那一刻的感觉。如果现实生活中再次发生,那可能是什么东西出错了。
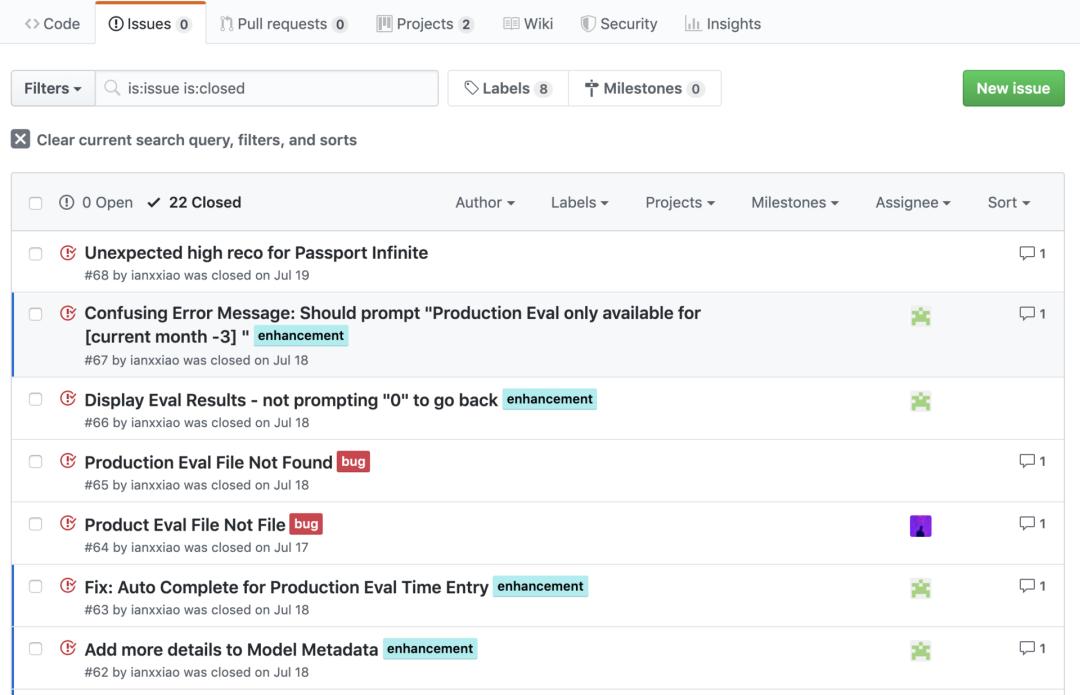
救火(占10-50%时间)
再周全的时间计划,总会发生一些让你偏离正轨的意外。不仅是数据科学,对于任何交付团队经理来说,这就是一场噩梦。具体来说,意外可以分为3类:
a)外部因素,如范围变更、上游系统依赖和客户抱怨;
b)内部团队问题,如恼人的bug需要更多的时间解决、团队成员离职但没有做好交接、人力不足、个人冲突等;
c)以及自己的无知,包含一切五花八门的“其他”事情。
期望:
从头到尾巡检一遍,搞定后,迎接客户、领导、团队的击掌庆祝和拥抱。
现实:
意料之外的事情总是在最不合时宜的时候发生。意外会有一些规律可循,但没有解决问题的万能良方,这让人太心烦了。
应对策略:
1)遇到高技术问题或跨团队协作,最好将时间周期延长至2到2.5倍,预留足够的空间;
2)在团队内部设立激进的里程碑;
3)在心里大骂来平衡情绪,时儿也口头说说发泄;
4)深呼吸、保持微笑、学会倾听;
5)和团队一起探索所有可能的方案,依据可行性、所需投入、难易程度确定方案优先级;
6)都不能起作用,不要再等待了,寻找帮助!
7)继续推进。以上都不能算是策略,但是在实践过程中可以发挥作用。
总结
本文都在论述真实世界中,从事数据科学工作会遇到哪些困难。有志于从事机器学习工作的人需要知道除了构建模型,事实上还有很多其他要做的。与其他工作一样,你最终都会感到枯燥、受挫。当然,这很正常。但更重要的是,你应该建立一套自己的应对策略,那你就可以长期在这个赛道上,享受沿途的小成就,奔向最终的胜利。
相关报道:
https://towardsdatascience.com/data-science-is-boring-1d43473e353e
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn
志愿者介绍
原标题:《数据科学很性感?不,其实它非常枯燥!》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

