- +1
Transformer有可能替代CNN吗?未来有哪些研究方向?听听大家都怎么说
机器之心报道
机器之心编辑部
Transformer 有可能替代 CNN 吗?现在下结论还为时过早。
Transformer 的跨界之旅,从 2020 延续到了 2021。
2020 年 5 月,Facebook AI 推出了 Detection Transformer(DETR),用于目标检测和全景分割。这是第一个将 Transformer 成功整合为检测 pipeline 中心构建块的目标检测框架, 在大型目标上的检测性能要优于 Faster R-CNN。
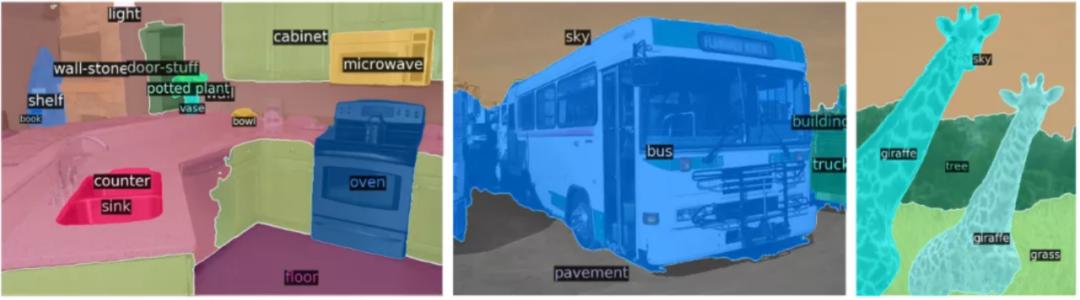
DETR-R101 处理的全景分割结果。
2020 年 10 月,谷歌提出了 (ViT),能直接利用 Transformer 对图像进行分类,而不需要卷积网络。该模型可以获得与当前最优卷积网络相媲美的结果,但其训练所需的计算资源大大减少。谷歌在论文中写道:这项研究表明,对 CNN 的依赖不是必需的。当直接应用于图像块序列时,transformer 也能很好地执行图像分类任务。
2020 年 12 月,复旦大学、牛津大学、腾讯等机构的研究者提出了 SEgmentation TRansformer(SETR),将语义分割视为序列到序列的预测任务,该模型在 ADE20K 上排名第一,性能优于 OCNet、GCNet 等网络。
元旦刚过,OpenAI 又 ,用 DALL·E 和 CLIP 打破了自然语言与视觉的次元壁。两个模型都利用 Transformer 达到了很好的效果,前者可以基于本文直接生成图像,后者则能完成图像与文本类别的匹配。

DALL·E 示例。给出一句话「牛油果形状的椅子」,就可以获得绿油油、形态各异的牛油果椅子图像。
这些研究覆盖了图像分类、目标检测、语义分割等 CV 主流方向。因此有人提问:未来,Transformer 有可能替代 CNN 吗?
这一问题在知乎、Reddit 等平台上都有人讨论。从讨论的结果来看,大部分人认为 Transformer 和 CNN 各有优劣,二者可能并非取代和被取代的关系,而是互相融合,取长补短。从研究现状来看,Transformer 在 CV 领域的应用还需要解决计算效率低等问题。
Transformer 取代 CNN?下结论还为时过早
在知乎讨论区,用户 @小小将指出,「目前我们看到很大一部分工作还是把 transformer 和现有的 CNN 工作结合在一起」。以 DETR 为例,该模型使用 CNN 从图像中提取局部信息,同时利用 Transformer 编码器 - 解码器架构对图像进行整体推理并生成预测。
声称「对 CNN 的依赖并非必需」的 ViT 模型可能也不例外。@小小将表示,「ViT 其实也是有 Hybrid Architecture(将 ResNet 提出的特征图送入 ViT)」。@mileistone 也认为,「(ViT)文章里提出的方法中会将图片分成多个无 overlap 的 patch,每个 patch 通过 linear projection 映射为 patch embedding,这个过程其实就是卷积,跟文章里声称的不依赖 CNN 自相矛盾。」
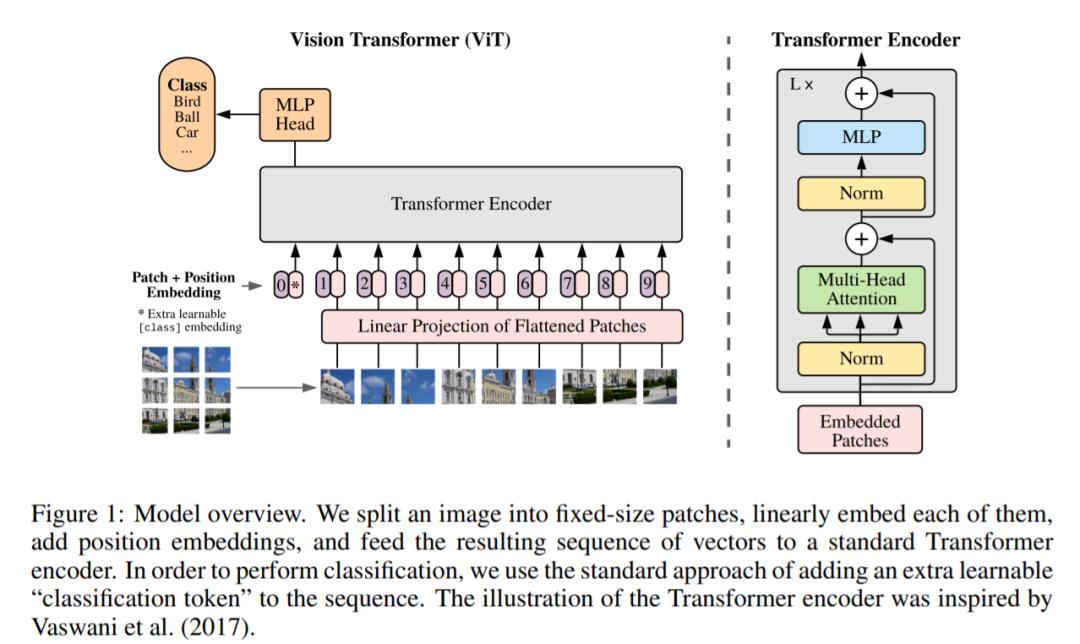
由于 CNN 和 Transformer 各有优势和不足,这种融合的做法出现在很多 Transformer 的跨界论文中。
在解释 CNN 和 Transformer 各自的优缺点时,用户 @齐国君提到,「CNN 网络在提取底层特征和视觉结构方面有比较大的优势。这些底层特征构成了在 patch level 上的关键点、线和一些基本的图像结构。这些底层特征具有明显的几何特性,往往关注诸如平移、旋转等变换下的一致性或者说是共变性。CNN 网络在处理这类共变性时是很自然的选择。但当我们检测得到这些基本视觉要素后,高层的视觉语义信息往往更关注这些要素之间如何关联在一起进而构成一个物体,以及物体与物体之间的空间位置关系如何构成一个场景,这些是我们更加关心的。目前来看,transformer 在处理这些要素之间的关系上更自然也更有效。」
从现有的研究来看,二者的结合也确实实现了更好的结果,比如近期的《Rethinking Transformer-based Set Prediction for Object Detection》「还是把现有的 CNN 检测模型和 transformer 思想结合在一起实现了比 DETR 更好的效果(训练收敛速度也更快)」(引自 @小小将)。反过来说,如果全部将 CV 任务中的 CNN 换成 Transformer,我们会遇到很多问题,比如计算量、内存占用量大到无法接受。
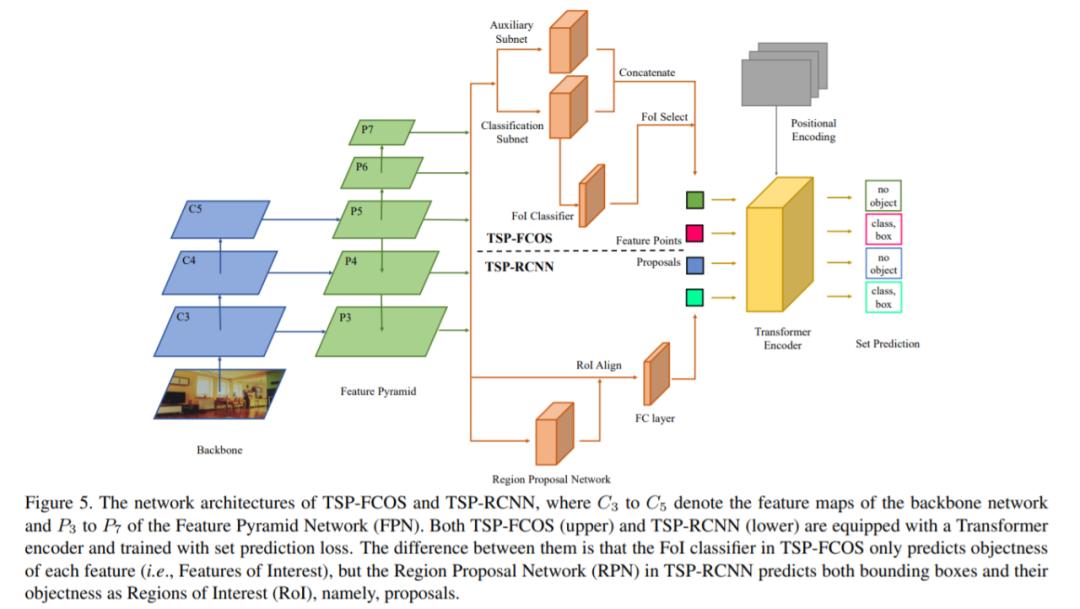
未来研究思路
Transformer 的跨界之旅还在继续,那么未来有哪些可能的研究思路呢?
去年 12 月,来自华为诺亚方舟实验室、北京大学、悉尼大学的研究者整理了一份综述,详细归纳了多个视觉方向的 Transformer 模型。
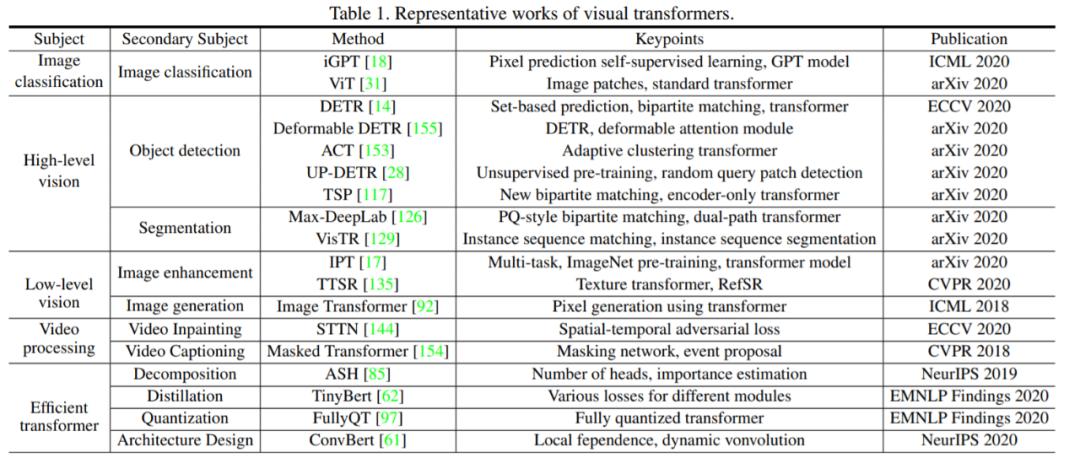
论文链接:https://arxiv.org/pdf/2012.12556.pdf
此外,他们还在论文中初步思考并给出了三个未来的研究方向:
现有的 Visual Transformer 都还是将 NLP 中 Transformer 的结构套到视觉任务做了一些初步探索,未来针对 CV 的特性设计更适配视觉特性的 Transformer 将会带来更好的性能提升。
现有的 Visual Transformer 一般是一个模型做单个任务,近来有一些模型可以单模型做多任务,比如 IPT,未来是否可以有一个世界模型,处理所有任务?
现有的 Visual Transformer 参数量和计算量多大,比如 ViT 需要 18B FLOPs 在 ImageNet 达到 78% 左右 Top1,但是 CNN 模型如 GhostNet 只需 600M FLOPs 可以达到 79% 以上 Top1,所以高效 Transformer for CV 亟需开发以媲美 CNN。(引自 @kai.han)
类似的综述研究还有来自穆罕默德 · 本 · 扎耶德人工智能大学等机构的《Transformers in Vision: A Survey》。
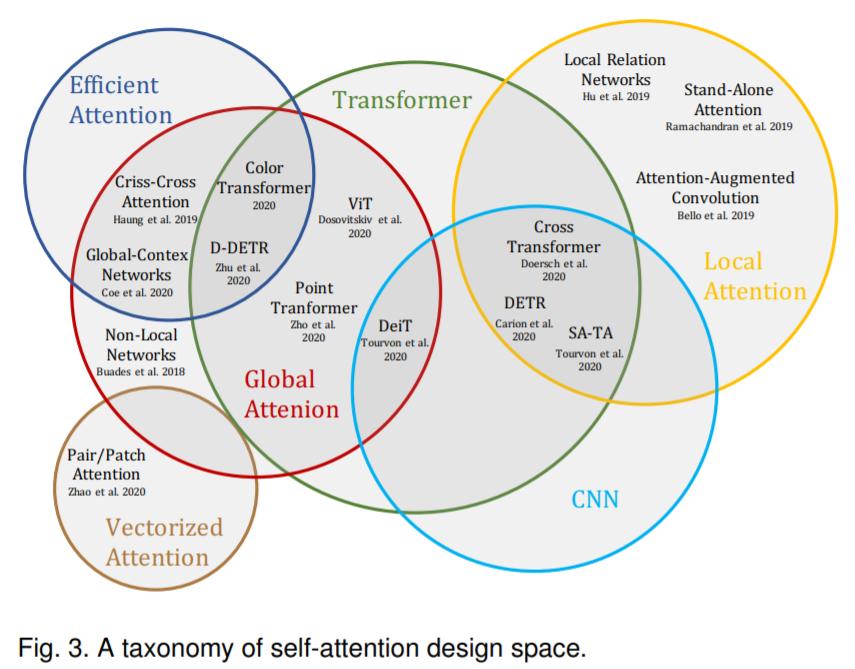
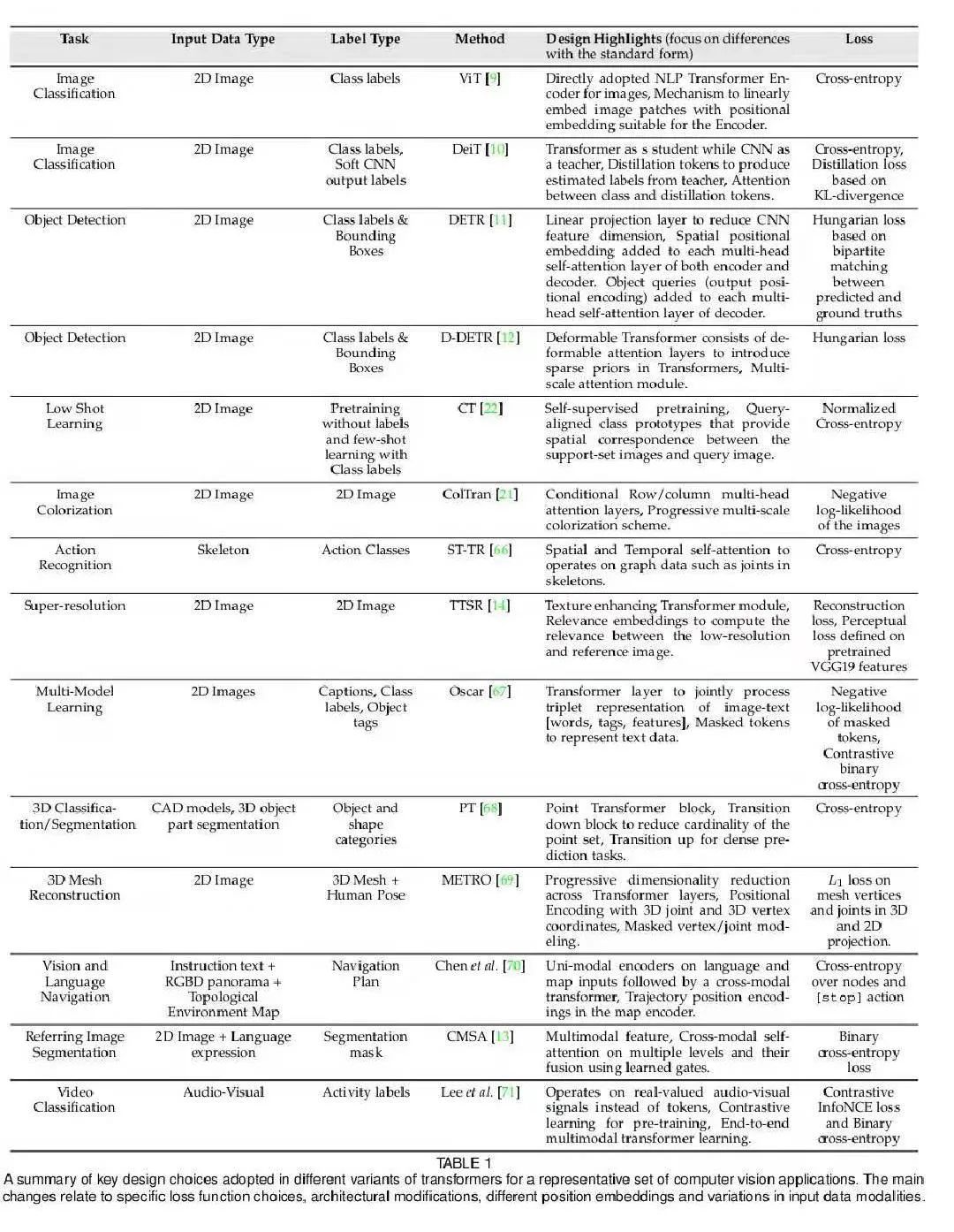
论文链接:https://arxiv.org/pdf/2101.01169.pdf
有志于 Transformer 跨界研究的同学可以在读完综述后寻找自己感兴趣的研究方向。
参考链接:https://www.zhihu.com/question/437495132
Nature论文线上分享 | 世界最快光子AI卷积加速器
世界最快光子AI卷积加速器登上Nature,该研究展示的是一种"光学神经形态处理器",其运行速度是以往任何处理器的1000多倍,该系统还能处理创纪录大小的超大规模图像——足以实现完整的面部图像识别,这是其他光学处理器一直无法完成的。
1月18日19:00,论文一作、莫纳什大学研究员徐兴元博士带来线上分享,详细介绍他们的工作以及光学芯片领域进展。
添加机器之心小助手(syncedai5),备注「光子」,进群一起看直播。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《Transformer有可能替代CNN吗?未来有哪些研究方向?听听大家都怎么说》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

